自监督模型---概述
图像自监督网络结构一般包含两种结构:
辨别式(孪生网络),生成式(GAN网络);
由于自监督任务没有标签,我们需要基于一定规则去生成标签或还原图像,该过程称为借口任务(Pretext tasks),Unsupervised/self-supervised 借口任务(Pretext tasks)主要包括如下:
- 去噪:原图加一些噪声送入网络输出去噪后的图
- 上色:将原图变成灰度图送入网络输出上色后的图
- 旋转图片预测角度
- 扣除原图的某一个patch,要求网络补出来
- 将图片切分几块后打乱,要求给出每块正确的位置
- 打乱一段视频帧给出正确的顺序或者判断一段视频帧是否被打乱过
- GAN中数据生成
- 对图片进行随机augmentation(crop,颜色抖动等等),然后判断一对图片是否来自于同一张图片
对于借口任务,我们也需要一些对应的损失函数去优化我们的网络,Loss function:
- L1 or L2 losses:比如pretext去噪上色等任务都可以用
- cross-entropy or margin-based losses:比如pretext给出打乱图片块的正确位置
-
Adversarial losses:测量两个分布的差异,常用于GAN,无监督数据生成
- Contrastive losses:测量一对样本在表示空间里的相似度,起源于Yann LeCun “Dimensionality Reduction by Learning an Invariant Mapping”
- InfoNCE : 常用于目前大多数流行对比式监督模型
- ProtoNCE:用于原型对比模型中(PCL)
评测自监督学习的能力:
自监督学习性能的高低,主要通过模型学出来的feature的质量来评价。feature质量的高低,主要是通过迁移学习的方式,把feature用到其它视觉任务中(分类、分割、物体检测...),然后通过视觉任务的结果的好坏来评价。 此外,训练过程也可参考图像修复的指标(fid、psnr、ssim,inception score)
训练技巧
自监督学习需要更大的 batch 和更长的训练时间。
自监督学习的方法主要可以分为3类:
1、基于上下文
在图像中,研究人员通过一种名为Jigsaw(拼图)[1]的方式来构造辅助任务。我们可以将一张图分成9个部分,然后通过预测这几个部分的相对位置来产生损失。比如我们输入这张图中的小猫的眼睛和右耳朵,期待让模型学习到猫的右耳朵是在脸部的右上方的,如果模型能很好的完成这个任务,那么我们就可以认为模型学习到的表征是具有语义信息的。
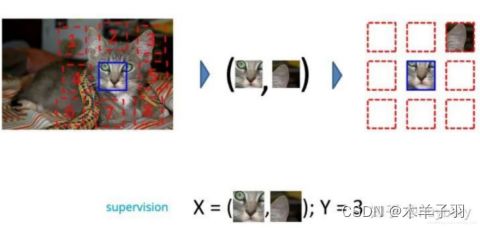
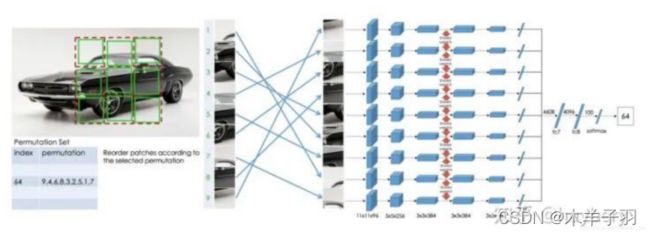
后续的工作[2]人们又拓展了这种拼图的方式,设计了更加复杂的,或者说更难的任务。首先我们依然将图片分为 9 块,我们预先定义好 64 种排序方式。模型输入任意一种被打乱的序列,期待能够学习到这种序列的顺序属于哪个类(64分类),和上个工作相比,这个模型需要学习到更多的相对位置信息。这个工作带来的启发就是使用更强的监督信息,或者说辅助任务越难,最后的性能越好。
除了这种拼图的模式,还有一种是抠图[3],MAE。想法其实也很简单粗暴,就是我们随机的将图片中的一部分删掉,然后利用剩余的部分来预测扣掉的部分,只有模型真正读懂了这张图所代表的含义,才能有效的进行补全。

还有一种思路是通过图片的颜色信息[4],比如给模型输入图像的灰度图,来预测图片的色彩。只有模型可以理解图片中的语义信息才能得知哪些部分应该上怎样的颜色,比如天空是蓝色的,草地是绿色的,只有模型从海量的数据中学习到了这些语义概念,才能得知物体的具体颜色信息。

2、基于时序
最能体现时序的数据类型就是视频。
第一种思想是基于帧的相似性[8],对于视频中的每一帧,其实存在着特征相似的概念,简单来说我们可以认为视频中的相邻帧特征是相似的,而相隔较远的视频帧是不相似的,通过构建这种相似(position)和不相似(negative)的样本来进行自监督约束。

另外,对于同一个物体的拍摄是可能存在多个视角(multi-view),对于多个视角中的同一帧,可以认为特征是相似的,对于不同帧可以认为是不相似的。
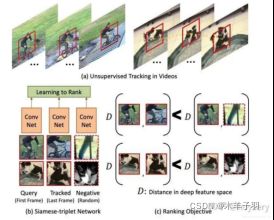
除了基于特征相似性外,视频的先后顺序也是一种自监督信息。比如unsupervised learning using temporal order verification[9].
3、基于对比
通过学习对两个事物的相似或不相似进行编码来构建表征,通过学习对两个事物的相似或不相似进行编码来构建表征,常用的损失函数InfoNCE。
1、我们首先介绍 ICLR 2019 的 DIM [5],DIM 的具体思想是对于隐层的表达,我们可以拥有全局的特征(编码器最终的输出)和局部特征(编码器中间层的特征),模型需要分类全局特征和局部特征是否来自同一图像。所以这里 x 是来自一幅图像的全局特征,正样本是该图像的局部特征,而负样本是其他图像的局部特征。

2、CPC主要是利用自回归的想法,对相隔多个时间步长的数据点之间共享的信息进行编码来学习表示,这个表示c_t可以代表融合了过去的信息,而正样本就是这段序列t时刻后的输入,负样本是从其他序列中随机采样出的样本。CPC的主要思想就是基于过去的信息预测的未来数据,通过采样的方式进行训练。
3、CMC利用多模态(多视角)的信息来构造样本[6] ,一个样本的多个模态为正样本,其他样本的模态为负样本。
4、MoCo把target x看成第i张图片的随机crop,而负样本则从memory bank里面拿,提出了model ema和shuffleBN来解决之前没法很好sample负样本的问题。
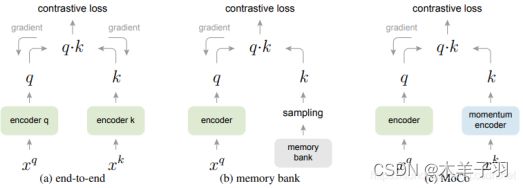
其中,End-2-end,q和k的encoder可相同也可不相同,取一个batch,其中1个可以匹配的key,K个不可以匹配的key。
memory bank,先把所有样本的特征保存下来,仅bp query一个encoder网络。
MoCo,是以上两者的融合版本,只是把memory bank改成了queue,每sample一个batch key。
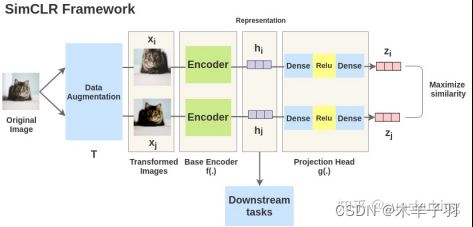
5、SimCLR,拍摄图像并对其进行随机变换以获得一对两个增强图像Xi和Xj。该对中的每个图像都通过编码器以获取表示形式。然后,应用非线性完全连接层以获得表示z。任务是最大化这两种表示之间的相似性zi和zj对于同一张图片。相较与MoCo结构改变不大,训练的 batchsize 需要到几千,要用32-128 cores的TPU。
6、MoCo v2,在MoCo 网络结构中经过卷积层后的一层线性MLP扩展为两层非线性的MLP,使用ReLU激活函数。在 Data Argumentation中,增加使用 Blur augmentation 来进行数据增强。
7、MoCo v3,探索了在自监督学习框架中训练ViT的研究工作,缓解训练稳定性问题。
其他一些自我监督和对比学习:SimCLR、MoCo、BYOL、SwAV、RELICv2
目前,凯明大佬提出的MAE掀起了学术界的热朝,使得Transformer在图像领域上取得了新高。关于Mask机制在CNN是否也能适用,这里收集一些网上讨论。
CNN已有的maksed autoencoder 带掩码的自编码器,denoising autoencoder(噪点),一张图片里加入很多噪音,通过去噪来学习对这张图片的理解。通过GAN Loss可以使图像还原更真实。
跟MAE有诸多不同之处,如补丁掩码,高达75%的掩码率。
MAE在CNN中应用的难点
CNN在一张图片上,使用一个卷积窗口、不断地平滑,来汇聚一些像素上面的信息+模式识别,卷积窗口扫过来、扫过去时,无法区分边界,无法保持 mask 的特殊性,无法拎出来 mask;最后从掩码信息很难还原出来。
Transformer的一个mask对应的是一个特定的词,会一直保留,和别的词区分开来。
更多模型:ImageNet Benchmark (Self-Supervised Image Classification) | Papers With Code
文章参考:自监督学习 | (1) Self-supervised Learning入门_sdu_hao的博客-CSDN博客_自监督学习
- Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised Visual Representation Learning by Context Prediction. In ICCV 2015
- Noroozi, M., & Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In ECCV 2016.
- Deepak Pathak et al. Context Encoders: Feature Learning by Inpainting. In CVPR 2016.
- Zhang, R., Isola, P., & Efros, A. A. Colorful image colorization. In ECCV 2016.
- Hjelm, R. Devon et al. “Learning deep representations by mutual information estimation and maximization.” . ICLR 2019
- Tian, Yonglong et al. “Contrastive Multiview Coding.” ArXiv abs/1906.05849 (2019): n. pag.
- Wu, Zhirong et al. “Unsupervised Feature Learning via Non-parametric Instance Discrimination.” CVPR 2018
- Sermanet, Pierre et al. “Time-Contrastive Networks: Self-Supervised Learning from Video.” 2018 IEEE International Conference on Robotics and Automation (ICRA) (2017): 1134-1141.
- Misra, I., Zitnick, C. L., & Hebert, M. Shuffle and learn: unsupervised learning using temporal order verification. In ECCV 2016.