四、Pandas数据清洗规整
四、Pandas数据清洗规整
4.1 数据加载、储存
4.1.1 从数据文件读取数据
导入支持库:
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
从csv文件读取数据,一般方法:
pd.read_csv('../data/ex1.csv',encoding='gbk')
从csv文件读取数据,去掉头部:
pd.read_csv('../data/ex1.csv',encoding='gbk',header=None)
读取数据,设置头部名称:
colnames = ['商品编号','进货价格(元)','销售价格(元)','销售数量','商品名称']
pd.read_csv('../data/ex1.csv',encoding='gbk',names=colnames)
4.1.2 为读取数据添加索引
添加一级索引:
pd.read_csv('../data/ex1.csv',encoding='gbk',names=colnames,index_col='商品编号')
添加多级索引:
pd.read_csv('../data/csv_mindex.csv',encoding='GBK',index_col=['生产厂商','产品类别'])
4.1.3 读取文件并筛选行
直接读取数据:
pd.read_csv('../data/ex4.csv',encoding='gbk')
设置跳过数据行:
pd.read_csv('../data/ex4.csv',encoding='gbk',skiprows=[0,2,3])
4.1.4设置读取行数
pd.read_csv('../data/ex5.csv')
选择前30行数据:
pd.read_csv('../data/ex5.csv',nrows=30)
4.1.5写csv文件
首先现读取一个文件:
data = pd.read_csv('../data//ex6.csv',encoding='gbk')
data
简单写入文件:
data.to_csv('out1.csv',encoding='UTF8')
4.1.6 写入文件,设置写入参数
data.to_csv('out3.csv',encoding='UTF8',na_rep='NULL',index=False,header=False)
4.1.7 读取数据库
此处只列出连接方法,不做连通测试
导入支持库:
import pymysql
如果提示没有这个模块,请先安装:!pip install pymysql
链接数据库读取数据表:
conn = pymysql.connect(host='localhost',user='root',password='123456',db='employees',charset='utf8')
sql = 'select * from departments'
df = pd.read_sql(sql,conn)
df
4.2 数据规整
4.2.1 导入支持库
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
4.2.2 创建原始数据
data = DataFrame({'k1': ['one'] * 3 + ['two'] * 4,
'k2': [1, 1, 2, 3, 3, 4, 4]})
data

4.2.3 检查重复
data.duplicated()

4.2.4 去除重复
data.drop_duplicates()

4.2.5 添加一列新的数据
data['v1'] = range(7)
data
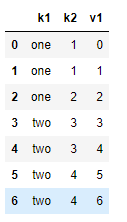
4.2.6 按照k1列为标准,去重
data.drop_duplicates(['k1'])

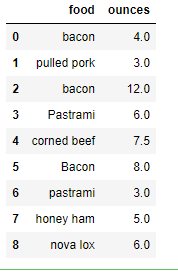
4.2.7 利用映射进行数据转换-创建实验数据
data = DataFrame({'food': ['bacon', 'pulled pork', 'bacon', 'Pastrami', 'corned beef', 'Bacon', 'pastrami', 'honey ham', 'nova lox'],
'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
data
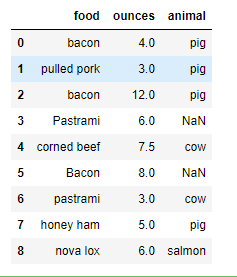
4.2.8 创建映射关系替换数据
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
data['animal'] = data['food'].map(meat_to_animal)
data
4.2.9 利用函数进行数据转换-调用str.lower函数替换为小写
data['animal'] = data['food'].map(str.lower).map(meat_to_animal)
data

4.2.10 替换值-创建实验数据
data = Series([77., -1., 31., -1., -2., 5.])
data

4.2.11 将等于-1的数据替换为NaN,等于-2的数据替换为0
data.replace([-1, -2], [np.nan, 0])

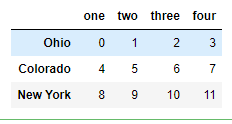
4.2.12 重命名轴索引-创建实验数据
data = DataFrame(np.arange(12).reshape((3, 4)), index=['Ohio', 'Colorado', 'New York'], columns=['one', 'two', 'three', 'four'])
data
4.2.13 将标签改为大写
data.index = data.index.map(str.upper)
data

4.2.14 更换title为大写
data.rename(index=str.title, columns=str.upper)
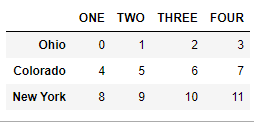
4.2.15 修改指定的行列标签
data.rename(index={'OHIO': 'INDIANA'}, columns={'three': 'peekaboo'})
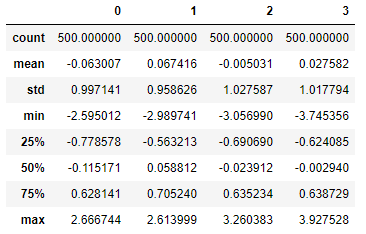
4.2.16 检测和过滤异常值-创建实验数据
np.random.seed(12345)
data = DataFrame(np.random.randn(500, 4))
data.describe()
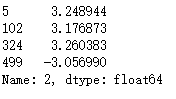
4.2.17 选出第三列绝对值大于3的
col = data[2]
col[np.abs(col) > 3]
4.2.18 假设这些绝对值大于3的数据是异常值,对数据作处理
data[np.abs(data) > 3] = np.sign(data) * 3
data.describe()

4.3 Series和DataFrame对象的绘图方法
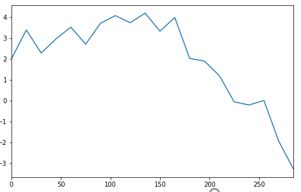
4.3.1 Series对象绘制简单的线形图
import numpy as np
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
ser = Series(np.random.randn(20).cumsum(), index=np.arange(0, 300, 15))
ser.plot(figsize=(8,5))
plt
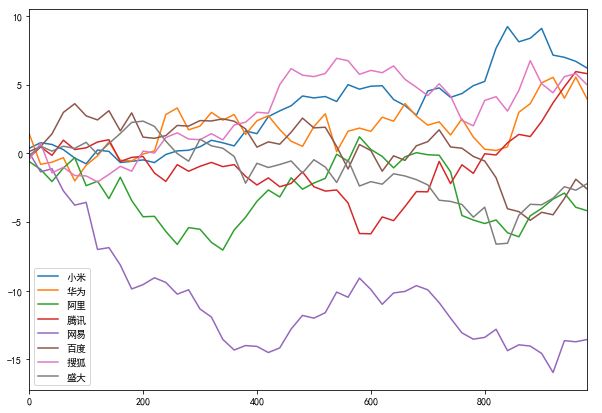
4.3.2 DataFrame对象绘制简单的线形图
import numpy as np
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
df = DataFrame(np.random.randn(50, 8).cumsum(0),
columns=['小米', '华为', '阿里', '腾讯','网易','百度','搜狐','盛大'],
index=np.arange(0, 1000, 20))
df.plot(figsize=(10,7))
plt.show()
4.3.3 Series对象绘制简单的垂直和水平柱状图
import numpy as np
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2, 1,figsize=(16,12))
data = Series(np.random.rand(10), index=list('abcdefghij'))
data.plot(kind='bar', ax=ax[0], color='r', alpha=0.5, rot=360, fontsize=16)
data.plot(kind='barh', ax=ax[1], color='b', alpha=0.7, fontsize=16)
plt.show()

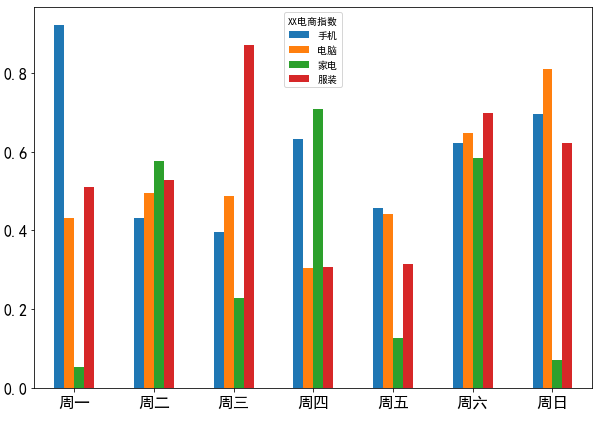
4.3.4 DataFrame对象绘制简单的垂直柱状图
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
df = DataFrame(np.random.rand(7, 4),
index=['周一', '周二', '周三', '周四', '周五', '周六', '周日'],
columns=pd.Index(['手机', '电脑', '家电', '服装'], name='XX电商指数'))
df.plot(kind='bar',figsize=(10,7), rot=360, fontsize=16)
plt.show()
4.4 Pandas绘图函数实例
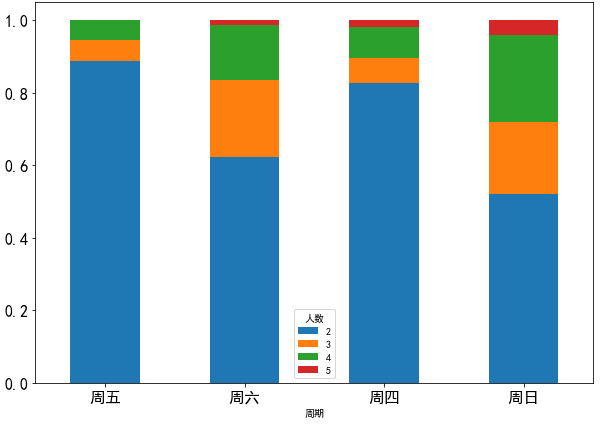
4.4.1 餐厅聚餐数据堆积柱状图
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
import matplotlib.pyplot as plt
restaurant = pd.read_csv('../data/RestaurantData.csv', encoding='gbk')
num_counts = pd.crosstab(restaurant['周期'], restaurant['人数'])
num_counts = num_counts.loc[:, 2:5]
num_pcts = num_counts.div(num_counts.sum(1).astype(float), axis=0)
num_pcts.plot(kind='bar', figsize=(10,7), fontsize=16, rot=360, stacked=True)
plt.show()
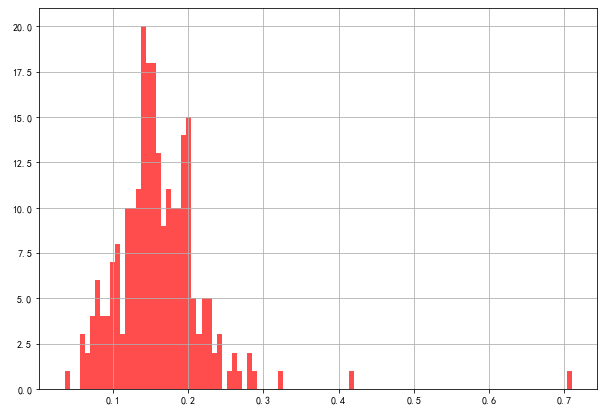
4.4.2 餐厅小费与消费总金额占比数据直方图
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
import matplotlib.pyplot as plt
restaurant = pd.read_csv('../data/RestaurantData.csv', encoding='gbk')
restaurant['百分比'] = restaurant['小费'] / restaurant['消费总金额']
restaurant['百分比'].hist(bins=100, figsize=(10,7), color='r',alpha=0.7)
plt.show()
4.4.3 餐厅小费与消费总金额占比数据密度图
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
import matplotlib.pyplot as plt
restaurant = pd.read_csv('../data/RestaurantData.csv', encoding='gbk')
restaurant['百分比'] = restaurant['小费'] / restaurant['消费总金额']
restaurant['百分比'].plot(kind='kde', figsize=(10,7), color='r',alpha=0.7, fontsize=16)
plt.show()

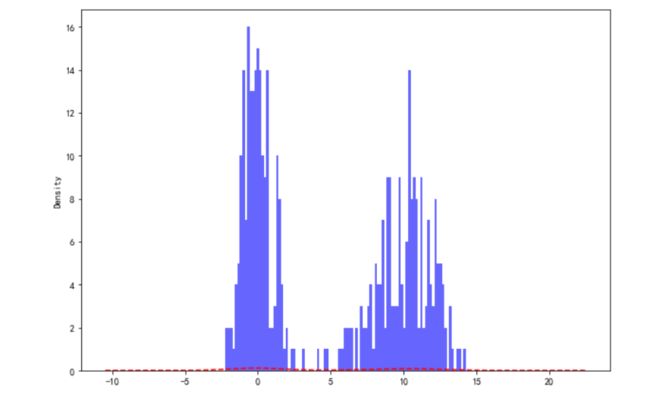
4.4.4 直方图和密度图组成双峰分布图
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
import matplotlib.pyplot as plt
plt.figure(figsize=(10,7))
data1 = np.random.normal(0, 1, size=200)
data2 = np.random.normal(10, 2, size=200)
values = Series(np.concatenate([data1, data2]))
values.hist(bins=100, alpha=0.6, color='b')
values.plot(kind='kde', style='r--')
plt.show()
4.4.5 绘制散布图
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
import matplotlib.pyplot as plt
md = pd.read_csv('../data/macrodata.csv')
data = md[['cpi', 'm1', 'tbilrate', 'unemp']]
trans_data = np.log(data).diff().dropna()
plt.figure(figsize=(10,7))
plt.scatter(trans_data['m1'], trans_data['unemp'])
plt.show()
