【nn.Parameter()】生成和为什么要初始化
参考博文:
- 《pytorch 生成全零tensor 指定type_Tensor与tensor深入分析》
一、定义
torch.nn.Parameter是继承自torch.Tensor的子类,其主要作用是作为nn.Module中的可训练参数使用。它与torch.Tensor的区别就是nn.Parameter会自动被认为是module的可训练参数,即加入到parameter()这个迭代器中去;而module中非nn.Parameter()的普通tensor是不在parameter中的。
-
nn.Parameter可以看作是一个类型转换函数,将一个不可训练的类型 Tensor 转换成可以训练的类型 parameter .
-
并将这个 parameter 绑定到这个module 里面(net.parameter() 中就有这个绑定的 parameter,所以在参数优化的时候可以进行优化),所以经过类型转换这个变量就变成了模型的一部分,成为了模型中根据训练可以改动的参数。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
-
nn.Parameter()添加的参数会被添加到Parameters列表中,会被送入优化器中随训练一起学习更新
-
在nn.Module类中,pytorch也是使用nn.Parameter来对每一个module的参数进行初始化的
class Parameter(torch.Tensor)
| Parameter(data=None, requires_grad=True)
二、data是与其他函数搭配生成+初始化
torch.Tensor
a = nn.Parameter(torch.Tensor(size=(2,3)))#有梯度
print(a)
b=torch.Tensor(size=(2,5)) #没有梯度
print(b,b.grad)
out:
Parameter containing:
tensor([[0., 0., 0.],
[0., 0., 0.]], requires_grad=True)
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]]) None
torch.FloatTensor
a = nn.Parameter(torch.FloatTensor(size=(2,3)))#有梯度
print(a)
b=torch.FloatTensor(size=(2,5)) #没有梯度
print(b,b.grad)
out:
Parameter containing:
tensor([[0., 0., 0.],
[0., 0., 0.]], requires_grad=True)
tensor([[1.0653e-38, 1.0194e-38, 8.4490e-39, 1.0469e-38, 9.3674e-39],
[9.9184e-39, 8.7245e-39, 9.2755e-39, 8.9082e-39, 9.9184e-39]]) None
torch.empty
a = nn.Parameter(torch.empty(size=(2,3)))#有梯度
print(a)
b=torch.empty(size=(2,5)) #没有梯度
print(b,b.grad)
out:
Parameter containing:
tensor([[0.0000e+00, 0.0000e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00, 7.1450e+31]], requires_grad=True)
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]]) None
- 随机初始化得方法
《[nn.Parameter]理解总结与初始化方法大全》
三、nn.Parameter+随机函数生成训练参数,不用初始化
class My(nn.Module):
def __init__(self,):
super(My, self).__init__()
self.x = nn.Parameter(torch.rand(4,2)) #生成0~1之间得均匀分布
self.w = nn.Parameter(torch.randn(size=(3,1))) #生成mean=0,std=1得正太分布
self.u = nn.Parameter(torch.randint(10, (2, 2)).float())#生成low=0,high=10得随机整数,然后变为浮点数
self.v = nn.Parameter(torch.normal(mean=1,std=0.05,size=(5,1)))#生成mean=1,std=0.05得正太分布
my = My()
for p in my.parameters():
print(p,type(p))
总结:常用得随机函数。可以当作初始化得一个替代。
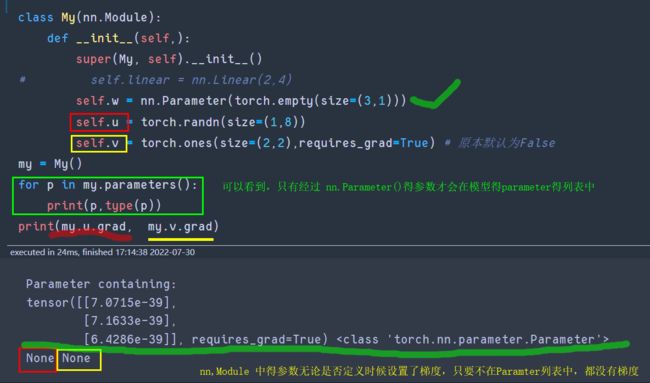
四、在nn.module下生成Tensor不为训练参数
定义一个简单得model
class My(nn.Module):
def __init__(self,):
super(My, self).__init__()
self.linear = nn.Linear(2,3)
self.w = nn.Parameter(torch.empty(size=(3,1)))
self.u = torch.randn(size=(1,4))
my = My()
for p in my.parameters():
print(p,type(p))
- 查看model得Parameter。下面是self.linear和self.w得参数
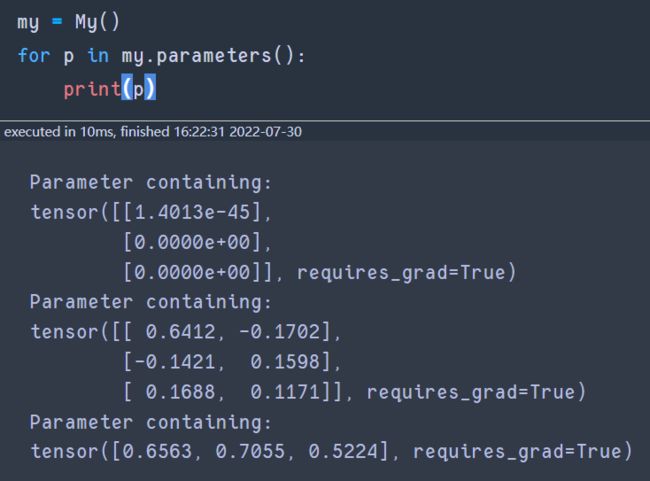
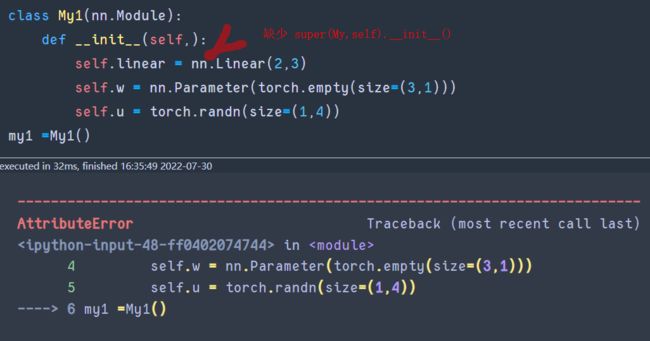
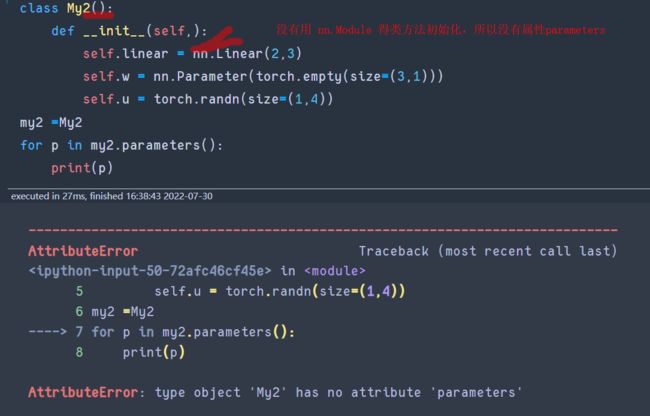
- 原因在于My是
nn.Module得子类并用它得方式初始化过了。否则My不具备parameters()方法且会初始化报错。
附录1:使用torch.FloatTensor产生0值或着nan值
我们使用torch.FloatTensor循环100次生成shape分别维1维、2维、3维、4维的Tensor。然后查看生成0值或着nan值得情况。
# -*- coding:utf-8 -*-
import torch
A1,A2,A3,A4 =[],[],[],[]
N1,N2,N3,N4 =[],[],[],[]
for i in range(100):
B1=torch.FloatTensor(size=(3,))
B2=torch.FloatTensor(size=(3,4))
B3=torch.FloatTensor(size=(5,4,2))
B4 =torch.FloatTensor(size=(7,5,3,4))
if torch.sum(B1)==torch.tensor(0.):
A1.append(i)
elif torch.sum(B1.isnan())>0:
N1.append(i)
if torch.sum(B2)==torch.tensor(0.):
A2.append(i)
elif torch.sum(B2.isnan())>0:
N2.append(i)
if torch.sum(B3)==torch.tensor(0.):
A3.append(i)
elif torch.sum(B1.isnan())>0:
N3.append(i)
if torch.sum(B4)==torch.tensor(0.):
A4.append(i)
elif torch.sum(B1.isnan())>0:
N4.append(i)
print(A1,A2,A3,A4)
print(N1,N2,N3,N4)
out:
[0, 2, 14, 18, 23, 40, 41, 42, 46, 60, 84, 91, 94] [11, 24, 38, 41, 42, 60, 84, 95] [] []
[62] [] [62] [62]
结论:显然使用torch.FloatTensor随机生成float类型得数据得时候,会产生全0值和出现nan值。这样得参数在做乘除法得 时候不具有意义。因此,我们需要进行参数得重新初始化。并且避免用到自动初始化得数值,因为这样可能会用到0值或着nan值。
附录2:nn.Parameter中很可能会生成全0张量
- 验证使用torch.FloatTensor搭配生成nn.Parameter得时候为全0张量得次数和生成nan得次数
A1,A2 =[],[]
for i in range(100):
a = nn.Parameter(torch.FloatTensor(size=(2,3)))
if torch.sum(a) ==torch.tensor(0.0):
A1.append(i)
elif torch.sum(a.isnan()) >0:
A2.append(i)
print(len(A1)/100,len(A2)/100) #0.37 ;0
- 验证使用torch.empty搭配生成nn.Parameter得时候为全0张量得次数和生成nan得次数
A1,A2 =[],[]
for i in range(100):
a = nn.Parameter(torch.empty(size=(2,3)))
if torch.sum(a) ==torch.tensor(0.0):
A1.append(i)
elif torch.sum(a.isnan()) >0:
A2.append(i)
print(len(A1)/100,len(A2)/100) #0.24 ;0
- 验证使用torch.Tensor搭配生成nn.Parameter得时候为全0张量得次数和生成nan得次数
A1,A2 =[],[]
for i in range(100):
a = nn.Parameter(torch.Tensor(size=(2,3)))
if torch.sum(a) ==torch.tensor(0.0):
A1.append(i)
elif torch.sum(a.isnan()) >0:
A2.append(i)
print(len(A1)/100,len(A2)/100) #0.13 ;0
结论:经过多次实验发现。单单使用torch.FloatTensor得时候会出现nan值,但加上nn.Parameter得时候,并没有出现nan值,这似乎是系统自动预防出现nan值无法求导得现象。但是多次出现了全0值。权重参数为全0值,对于梯度下降算法没有任何帮助,这也是要求我们对参数进行初始化得原因。同理,适用于(torch.Tensor和torch.empty)