Spark编程及其相关服务的配置
1、配置Linux操作系统网络及主机名及其克隆虚拟机配置映射关系(root权限下,systemctl disable firewalld关闭防火墙(禁止开机启动),systemctl status firewalld查看防火墙状态)
(1)设置静态ip
进入:vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改为:
重启网卡:service network start,之后再ifconfig查询一下就行了
(2)直接跳过虚拟机克隆阶段,进入映射关系的配置(每个机器都这样配置)
修改主机名:vim /etc/hostname(将里面的名字改为主机名,克隆机也一样)
配置生效:hostname 主机名
配置各个机器的映射关系,使其用主机名进行ping通(注意映射的顺序):
vim /etc/hosts
内容修改为:

2、SSH配置免密登录
使用xshell软件连接master主机后进行以下设置:
ssh-keygen -t rsa(全部按回车,生成秘钥)
cd /root/.ssh/
ssh-copy-id master(拷贝秘钥给master),后面输入yes,再输入密码即可(slave01同理,如图)
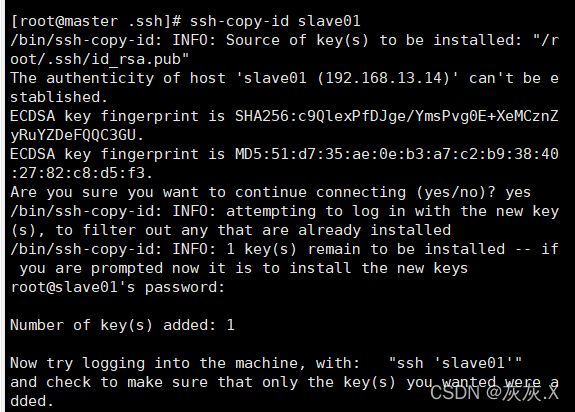
使用ssh slave01命令就可以免密登录slave01
3、配置时间同步(xshell中操作并且联网,指定master作为时间同步服务器)
(1)使用命令yum install chrony -y进行时间同步工具的下载
(2)启动时间同步服务: systemctl start chronyd,如果出现版本兼容的情况则使用命令“journa|ct| -xe”查看信息,使用“yum -y update“命令升级版本,使用reboot命令断开连接,重新在xshell中输入密码进行连接就可以解决版本不兼容的问题
(3)修改 vim /etc/chrony.conf里面的配置文件如图:

设置其他两台虚拟机的时间同步就只需要修改一个东西就行了,其他的不用修改,如图:
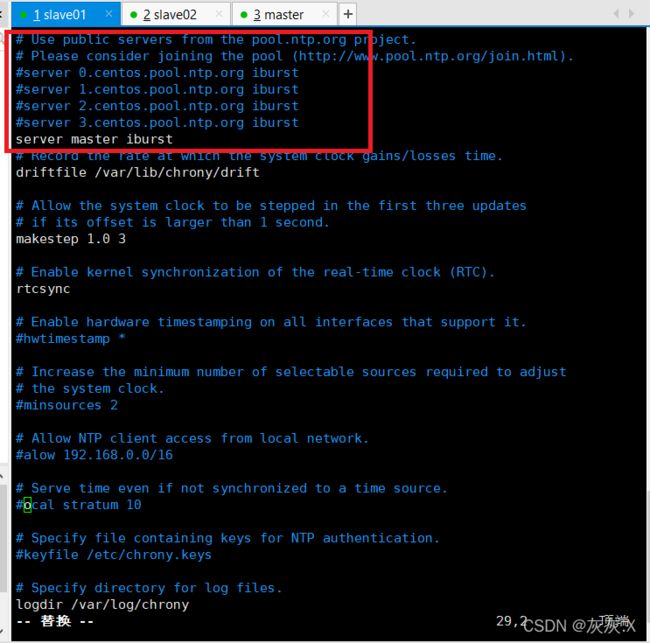

重启服务生效:systemctl restart chronyd
查看时间同步源:chronyc sources -v
4、安装jdk
1.首先查询系统自带的jdk :
[cqhg@master ~]$ rpm -qa | grep java
如果有则移除系统自带的jdk
[cqhg@master ~]su root
[root@master cqhg]# yum remove java-1.*
2.在虚拟机的/home/cqhg目录下,建立一个soft 目录,通过xftp把jdk上传到soft目录中。
3.在usr 目录中建立一个java目录:
root@master:~# mkdir /usr/java
4.将JDK文件解压,放到/usr/java目录下
tar -zxcf jdk-8u202-linux-x64.tar.gz
5.使用gedit配置环境变量
[cqhg@master java]$vim /home/cqhg/.profile
复制粘贴以下内容添加到到上面gedit打开的文件中末尾:
export JAVA_HOME=/usr/java/jdk1.8.0_111(jdk的路径)
export PATH= J A V A H O M E / b i n : JAVA_HOME/bin: JAVAHOME/bin:PATH
加粗样式使改动生效命令:
[cqhg@master java]$ source /home/cqhg/.profile
测试配置:
[cqhg@master ~]$ java -version
5、scala的安装(使用":quit"命令退出scala的编写)
scala的特性:面相对象,函数性,静态类型,可扩展,互操作性的
(1)windows安装:
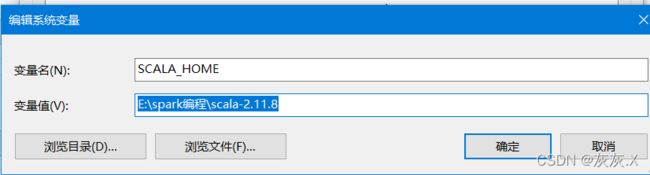
解压scala-2.11.8.zip至一个文件夹下
添加环境变量如图:
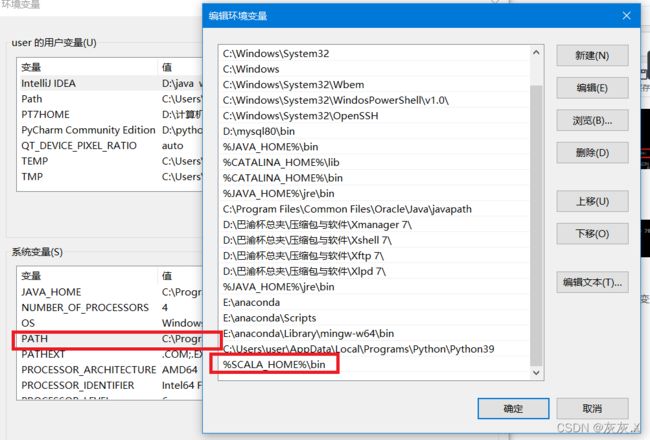
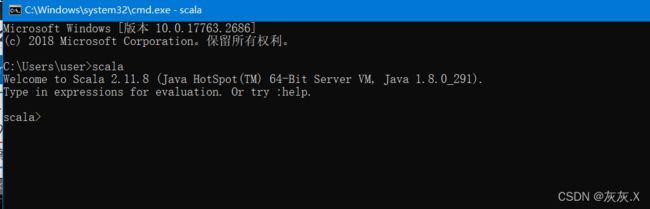
使用windows命令行查看:
(2)linux安装:
使用xftp将scala-2.11.8.tgz上传至linux中
通过解压命令解压至:tar -zxvf scala-2.11.8.tgz -C /root/export/servers
进入vim /etc/profile 编写配置文件如下:

使用source /etc/profile使配置文件生效
使用命令行查看是否安装成功:

使用scala -version查看scala的版本
6、在IDEA环境中下载安装Scala插件
scala插件下载地址:https://plugins.jetbrains.com/plugin/1347-scala,注:对应的idea版本要使用对应的scala插件,例:2021.2.30(scala版本)
2021.2 — 2021.2.4(idea适用的版本)
进入idea->configuer->plugins->install plugin from disk(离线安装) 之后找到下载的scala插件添加进去->restart idea,之后使用搜索框就找到scala
7、使用idea开发第一个scala程序
file->new->projiect->选择scala->idea(下一步)->给文件取一个名字,选择文件夹的存放路径(也可自动创建没有的文件夹),选择1.8的jdk版本,添加scala sdk->下一步->在src中创建new scala class文件夹和工程object,具体如下图:

第一个编写程序如图:

8、ZooKeeper集群的安装与配置
概念:
zookeeper是一个分布式程序应用协调服务,有多个follower和observer服务器,只存在一个leader服务器,数量数是2n+1个
安装zookeeper:
通过官网下载响应的zookeeper压缩包:https://www.apache.org/dyn/closer.cgi/zookeeper/
使用xftp将zookeeper-3.4.10.tar.gz上传至linux,使用命令:“”tar -zxvf zookeeper-3.4.10.tar.gz -C /export/servers“”解压至相应的目录
1、进入conf目录:
cd /root/export/servers/zookeeper-3.4.10/conf
2、对配置文件进行命名:
cp zoo_sample.cfg zoo.cfg
3、编辑配置文件vim zoo.cfg如下:
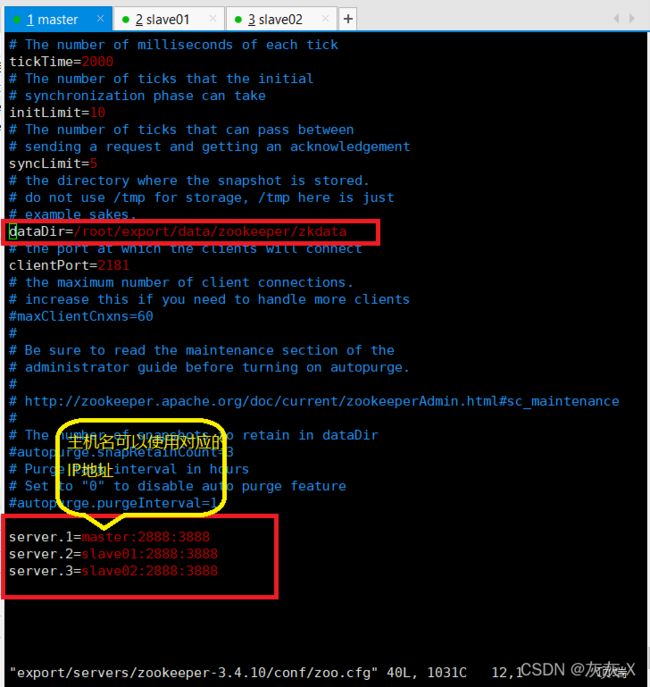
4、创建zkdata目录并进入:
mkdir -p /root/export/data/zookeeper/zkdata
cd /root/export/data/zookeeper/zkdata/
5、在此路径下(/root/export/data/zookeeper/zkdata/)创建myid文件并写入以下内容:
touch myid
echo 1 > myid

6、配置环境变量如下:
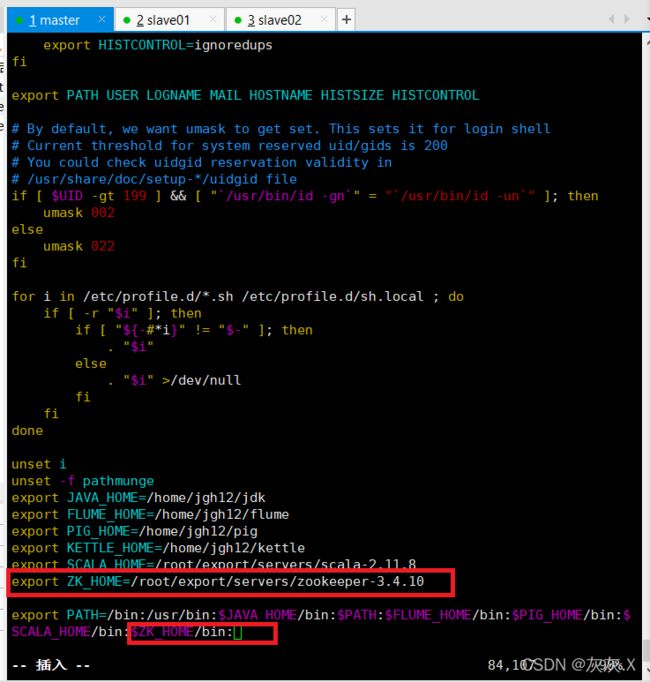
退出使配置生效:source /etc/profile
7、分发zookeeper文件和环境变量到slave01与slave02中
(1)分发zookeeper文件
分发zookeeper文件给slave01使用命令: scp -r /root/export/servers/zookeeper-3.4.10/ root@slave01:/root/export/servers/
分发zookeeper文件给slave02使用命令: scp -r /root/export/servers/zookeeper-3.4.10/ root@slave02:/root/export/servers/
(2)分发环境变量
*分发环境变量给slave01使用命令:*scp /etc/profile root@slave01:/etc/
![]()
*分发环境变量给slave02使用命令:*scp /etc/profile root@slave02:/etc/
8、对slave01与slave02进行创建和写入
*(1)slave01创建zkdata;*mkdir -p /root/export/data/zookeeper/zkdata
(2)在slave01的"/root/export/data/zookeeper/zkdata/myid"中写入东西:[root@slave01 export]# echo 2 > myid
(3)slavw02同理:
9、三台虚拟机的ZooKeeper集群的启动与关闭(每个虚拟机都要使变量生效: source /etc/profile)
1、启动zookeeper服务(slave01和slave02同理):zkServer.sh start,如图:



2、查看三台虚拟机的zookeeper状态命令:
zkServer.sh status



注:master和slave02是follower,slave01是leader
3、关闭三台虚拟机的zookeeper命令:
zkServer.sh stop



10、hadoop的安装、配置与启动
1、使用xftp将“”zookeeper-3.4.10.tar.gz“”上传至master的/root/export/software
2、使用xshell对该包进行命令解压:“tar -zxvf hadoop-2.7.4.tar.gz -C /root/export/servers/”
3、修改hadoop-env.sh文件
(1)进入hadoop文件:[root@master hadoop]#cd export/servers/hadoop-2.7.4/etc/hadoop/
(2)进入并编辑文件(修改jdk的路径,以自己的为准)如图: vi hadoop-env.sh
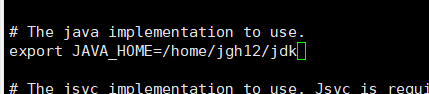
(3)保存退出即可
4、修改yarn-env.sh文件
(1)进入文件:[root@master hadoop]# vim yarn-env.sh
(2)修改jdk路径如图: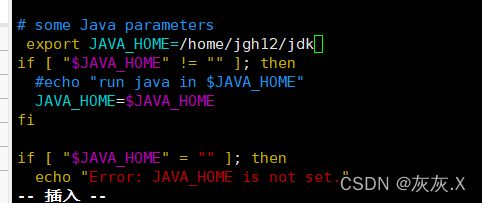
5、修改core-site.xml文件
(1)进入文件:[root@master hadoop]# vim core-site.xml
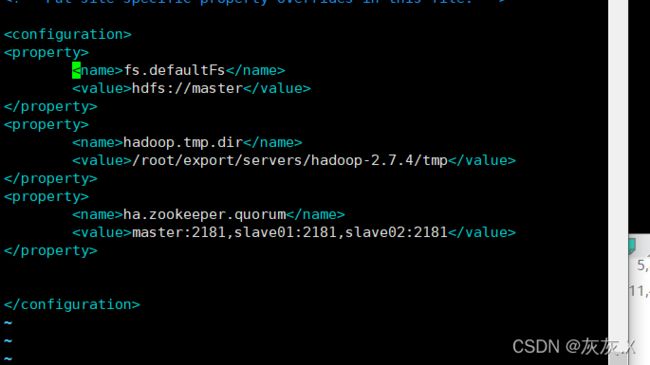
6、修改hdfs-site.xml文件
(1)进入文件:
[root@master hadoop]# vim hdfs-site.xml
7、修改mapred-site.xml 文件
(1)
8、修改yarn-site.xml文件
(1)
9、修改slaves文件
(1)
10、配置hadoop环境变量
(1)
11、分发文件至另外两台虚拟机
(1)
12、验证hadoop环境
(1)