操作系统OS lab4 (xv6) 实验报告
Lab 4: 调度
实验简介
实验目的:
- 1.理解操作系统的调度管理机制
- 2.熟悉 xv6的系统调度器框架,以及缺省的Round-Robin 调度算法
- 3.实现Priority based scheduling调度算法来替换缺省的调度算法
实验背景
- 1.调度: 任何操作系统都可能碰到进程数多于处理器数的情况,这样就需要考虑如何分享处理器资源。理想的做法是让分享机制对进程透明。这就要求进程调度程序按一定的策略,动态地把处理机分配给处于就绪队列中的某一个进程,以使之执行。调度策略必须满足几个相互冲突的目标:快速的进程响应时间、良好的后台作业吞吐量、避免进程饥饿、协调低优先级和高优先级进程的需求,等等。
- 2.Round-Robin: 在循环调度算法中,操作系统定义了一个时间量(片)。所有进程都将以循环方式执行。每个进程将获得CPU一小段时间(称为时间量),然后回到就绪队列等待下一轮。
- 3.Priority based scheduling: 每个进程会被赋予一个优先级。优先级越高,进程越快获得CPU。如果两个进程的优先级相同,那么它们将根据到达时间进行调度。
实验环境
本次实验的系统环境为XV6,Xv6是由麻省理工学院(MIT)为操作系统工程的课程(代号6.828),开发的一个教学目的的操作系统。Xv6是在x86处理器上(x即指x86)用ANSI标准C重新实现的Unix第六版(Unix V6,通常直接被称为V6)。1
TODO #1:阅读代码
阅读proc.c 中以下函数,分析函数的原理并解释函数的作用:sched, yield, sleep, wakeup, wait
整体背景分析
本次实验的目的是理解操作系统的调度管理机制,熟悉其系统调度器框架,以及缺省的Round-Robin调度算法。最后在上述基础上实现Priority based scheduling调度算法来替代缺省的调度算法。那么首先我们需要了解RR调度算法的定义和它在xv6系统里的实现形式。
根据实验说明给出的RR调度算法的定义,我们知道RR算法指的是系统将所有的进程按照FCFS算法排成一个就绪队列,然后设定一个时间片的大小,当当前进程运行完一个时间片大小的时间时,就产生一次时间中断,把cpu的使用权交还给调度器scheduler。scheduler拿到使用权后,在就绪队列里找到队首进程,将cpu的使用权分配给该进程。当该进程在cpu上运行完一个时间片后,再度重复上述操作。这就是RR算法的基本思想。但在实际实现中,算法的表现形式不一定一致,因此我们需要再看看xv6系统中scheduler函数的具体实现方式。首先看看scheduler函数的头部注释:
//PAGEBREAK: 42
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run
// - swtch to start running that process
// - eventually that process transfers control
// via swtch back to the scheduler.
通过直译注释,我们能得到的信息有:
- 1.每个CPU都有相同的scheduler
- 2.每个cpu在初始化自身之后就调用scheduler
- 3.scheduler调度器永远不返回,它不断的循环,内容是:
- 选择一个进程来运行
- 用swtch函数来开始运行被选择的进程
- 最终该进程同样通过调用swtch函数将cpu控制权交还给scheduler
对比RR算法的定义,我们可以看到它的大致框架与RR类似,但没有提到就绪队列这一说,让我们看看实际的代码实现里是怎么复现这个就绪队列的。
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Enable interrupts on this processor.
sti();
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
// Switch to chosen process. It is the process's job
// to release ptable.lock and then reacquire it
// before jumping back to us.
c->proc = p;
switchuvm(p);
p->state = RUNNING;
swtch(&(c->scheduler), p->context);
switchkvm();
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&ptable.lock);
}
}
可以看到第8行至第34行就是注释中所提到的无限循环loop,这使得scheduler永远不会返回。而第14行到第31行则是第二层循环,在进入该循环前,调度器获取了ptable.lock,这可以防止其他cpu对进程指针表中进程状态作出修改,避免了数据冲突。进入循环后,调度器按顺序遍历进程表中的进程,当找到一个进程的状态(state)为可运行(RUNNABLE)时,就在第21行到第23行进行以下操作:
- 1.将本cpu当前运行的进程指针改为该被选中的进程指针
- 2.切换到该进程的用户虚拟内存空间
- 3.将进程的状态改为RUNNING
完成上述操作后,就调用swtch函数,切换上下文。知道该进程因为某些原因(例如完成一个时间片的运行)调用swtch函数切换回scheduler的上下文。这是scheduler将从第26行开始运行,在切换到内核虚拟内存空间并且将当前cpu上的运行进程置为空后,进入下一次循环。
可以看出来xv6系统实现的所谓RR算法虽然满足了轮询的要求,但是并没有按照FCFS的原则来排就绪队列。而是按照固定的顺序(即进程在进程表中的顺序)来排序。举例来说,当表中第a个进程正在运行(RUNNING)时,第a+2个进程处于就绪(RUNNABLE)状态,那么该进程就必须等待第a个进程交出cpu的控制权。但如果在等待的过程中第a+1个进程也完成了必要的工作从而处于就绪状态(RUNNABLE),那么接下来调度器将不会把cpu的控制权优先交给先进入就绪队列的第a+2个进程,而是交给后来的第a+1个进程。这个例子说明了xv6中就绪队列的排列方式不遵守FCFS的原则,而是按照进程表中的固定顺序。
但总的来说,这样的偏差并不会引起饥饿的出现,该实现仍然能够保证每个处于就绪队列中的进程能在可以预期的时间内获取cpu的使用权。
了解了xv6系统的缺省调度算法及其实现方式,我们仅仅触及了整个xv6系统调度的冰山一角,整个进程调度系统涉及到的函数包括但不限于:sleep,wakeup,wait,yield,sched,swtch,scheduler。为了更好的理解xv6系统的调度实现,我们首先需要对整个调度过程中使用到的函数及其作用有一个概括性的了解。2
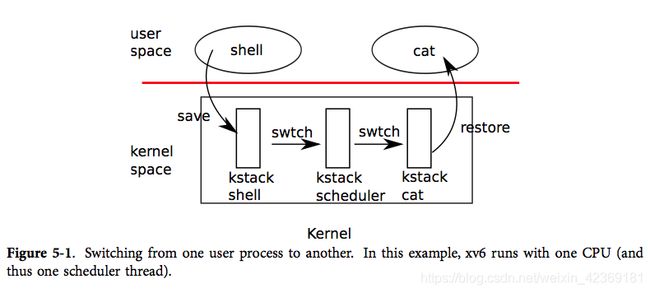
通过这张图我们能了解到,每次用户进程之间互相切换并不是直接交换两个进程的上下文,而是存在一个中间的协调者。这个中间者的存在拥有充分的理由。我们知道在多进程的操作系统中,通过系统实现时的特殊技巧使得每一个进程都拥有完整的一套寄存器,内存栈空间,并且仿佛独占了一个cpu。那么对应的,当我们在切换进程时,原进程占有的资源也应该是释放,问题是应该由谁来释放这些资源。
若用最直接的想法,即在切换两个进程时直接切换他们的上下文,中间不存在任何中间函数。那么释放资源的任务只能交给被切换出cpu的进程本身。但一个进程是无法将自己占用的资源全部释放的,否则它连执行释放资源本身所需的资源也无法提供。那么这里就必须存在一个第三者来完成这一工作。
现在我们再来看前文的这张图,就能理解为什么一个切换进程的操作需要经过三个中间节点了。首先我们需要了解xv6调度中的一个最底层的关键函数swtch:
# Context switch
#
# void swtch(struct context **old, struct context *new);
#
# Save the current registers on the stack, creating
# a struct context, and save its address in *old.
# Switch stacks to new and pop previously-saved registers.
.globl swtch
swtch:
movl 4(%esp), %eax
movl 8(%esp), %edx
# Save old callee-saved registers
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
# Switch stacks
movl %esp, (%eax)
movl %edx, %esp
# Load new callee-saved registers
popl %edi
popl %esi
popl %ebx
popl %ebp
ret
swtch函数的实现语言是汇编语言,通过阅读它的头部注释我们能知道它的作用正是我们前文屡次提到的上下文交换。所谓上下文交换,就是在进程切换时保存上一个进程的寄存器等信息,然后载入新进程的寄存器等信息。我们可以看到第14行到第18行将callee-saved(调用者保存)的寄存器信息按照:ebp,ebx,esi,edi的顺序入栈。在此之前,第11行和第12行将栈指针高处的两个值存放在eax和edx当中。根据汇编的惯例,在函数的一开始,栈基指针ebp需要与栈顶esp同步,此时esp仍然指向上一个函数栈的栈顶,而栈基指针对应的是当前函数栈空间的最高处。比这个地址再高的地方就是该函数的调用者的栈空间在调用该函数前的栈顶,也就是在调用本函数前储存了eip的位置,而我们注意到swtch函数有两个形参,分别是被切换出cpu的进程context指针和被切换进cpu的进程context指针。而在汇编代码中参数的进栈顺序是从右到左,即将被切换进cpu的进程指针先进栈,因此储存高位信息的edx指的是新进程的指针,而eax是旧进程的指针。
知道了eax,edx和esp的内容,我们再来看第20行到第22行,swtch将esp内的内容(即返回地址eip)放到eax内的指针指向的地址处。我们知道eax的本质是一个context指针,查看context的定义:
struct context {
uint edi;
uint esi;
uint ebx;
uint ebp;
uint eip;
};
可以看到context的最后一个元素正是eip,因此第21行的操作将旧进程的eip储存进了context中。而第22行将当前的栈顶置为新进程context指针的地址。根据规范性我们知道新进程的context格式与旧进程相同,因此按照顺序pop就能取到新进程的context内容。
了解了swtch的内容,我们就能进一步对这个切换过程有更多认识,首先我们先来看看本次实验所涉及到的函数之间有什么关系:
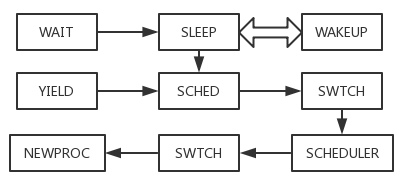
可以看到一个进程要交出cpu的控制权由两种方式,一个是通过调用sleep进入休眠状态(具体解析在下文呈现),sleep完成准备工作后将调用sched,sched的具体实现将在下一个小节解析。而sched将调用swtch,接下来的部分我们都已经在前文做出了最基本的解释。而另一种方式是调用进程调用yield,yield的解析同样在下文给出。而yield也将调用sched,之后的过程与上一种形式相同。
根据这张依赖图,我们应该先从没有任何依赖的swtch开始分析,然后再分析scheduler,以此类推。而我们已经在前文完成了两者的分析,因此接下来我们将按照sched,yield,sleep,wakeup,wait的顺序逐个函数进行解析。
sched分析
首先我们阅读sched的头部注释:
// and have changed proc->state. Saves and restores
// intena because intena is a property of this
// kernel thread, not this CPU. It should
// be proc->intena and proc->ncli, but that would
// break in the few places where a lock is held but
// there's no process.
注释内容告诉我们,在进入scheduler之前必须支持有ptable.lock一个锁,并且proc的状态不能是RUNNING,并且已经储存了当前进程的intena,此处intena的作用在上一个实验的实验报告中已经作出说明,简要的来说就是判断在上锁之前系统中断是否已经被阻止,这对于进程释放所有锁后是否允许系统中断是很重要的判断依据,而切换进程后这个值将会被新进程的intena顶替,所以在此应该先储存intena,再进入scheduler。从scheduler回来后,再将intena赋值给mycpu()->intena。保证数据不被损坏。我们再来看具体的实现:
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&ptable.lock))
panic("sched ptable.lock");
if(mycpu()->ncli != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(readeflags()&FL_IF)
panic("sched interruptible");
intena = mycpu()->intena;
swtch(&p->context, mycpu()->scheduler);
mycpu()->intena = intena;
}
我们可以看到sched的实现基本上就是检查了注释中提到的几个条件是否符合,并储存了intena,然后直接调用了swtch函数将当前进程的上下文与scheduler的上下文进行切换。在scheduler再次选择当前进程来占有cpu时,scheduler将调用swtch恢复该进程的上下文,即运行第17行代码,重新给intena赋值。
yield分析
我们直接阅读yield的代码:
// Give up the CPU for one scheduling round.
void
yield(void)
{
acquire(&ptable.lock); //DOC: yieldlock
myproc()->state = RUNNABLE;
sched();
release(&ptable.lock);
}
从yield函数简单的头部注释我们可以知道,yield的作用是结束当前时间片的运行,交出cpu的使用权。通过对sched的解析我们知道进入sched时必须持有ptable.lock,并且将当前进程的状态从RUNNING改为其他状态。而yield的四行代码中,前两行就完成了申请ptable.lock和修改状态的工作,并在第三行进入了sched,然后就会交出cpu的使用权。而当cpu的使用权再次被交还时,进程从sched函数返回到yield函数的第四行代码,释放ptable.lock,然后返回到更高层的地方。以上就是关于yield的解析。
在此处补充一些关于yield调用方式的内容。在xv6的源代码中以yield为关键词查询,能发现近万行的源代码中只有一处调用了yield函数。那就是trap函数:
// Force process to give up CPU on clock tick.
// If interrupts were on while locks held, would need to check nlock.
if(myproc() && myproc()->state == RUNNING &&
tf->trapno == T_IRQ0+IRQ_TIMER)
yield();
阅读这段代码和注释我们能了解到,这段代码的作用是在一个时间片运行完时强迫进程交出cpu的使用权。这与我们进程调度的实现是息息相关的,因此我们稍微深挖一下这背后的机制。
谈到RR进程调度算法,这当中有一个很关键的要素就是时间片,这要求进程每运行一个时间片就要交出对cpu的控制权,那么cpu与进程是如何知道时间的呢,知道了时间又如何才能调用trap函数呢?很显然不可能要求每个进程都随身携带一个计时器,计时器一到就调用trap函数,特别是对于xv6系统这样的单线程系统,一个进程不可能同时计算时间和运行其他任务。因此这个计时器必定是一个外部计时器。但外部的计时器要如何使当前进程调用trap呢?很明显每个进程运行的用户程序本身是没有这个命令的,用户程序本身只会试图完成用户的任务,试图独占整个cpu资源。因此接下来我们就将目光放到时间中断的实现上。首先我们先对整体的框架有一个认识:
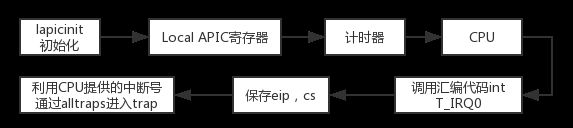
我们根据流程图中的顺序来简要的解释一下时间中断的实现,首先我们需要了解Local APIC寄存器的结构:3
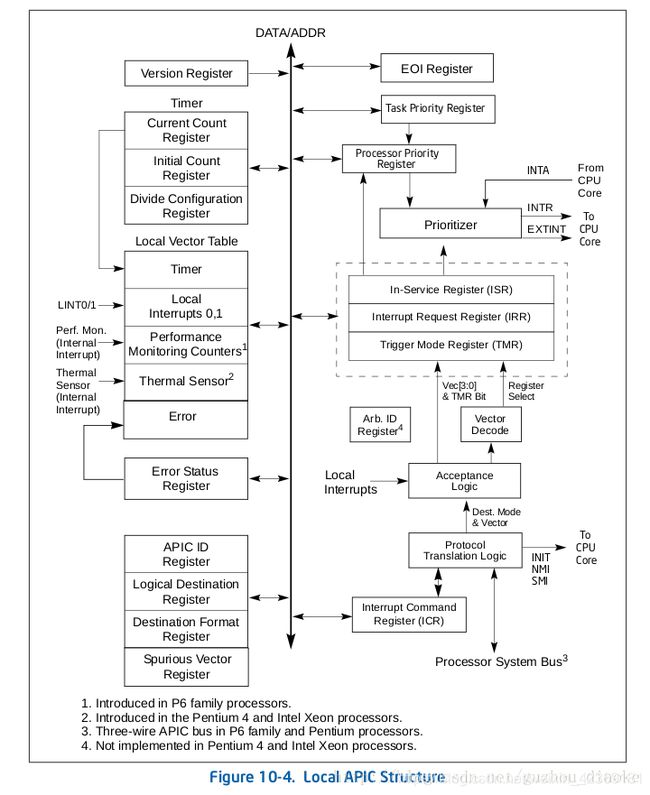
可以看到左半部分第二个小块是一个计数器,在此处用来计算时间,其中包含三个值:初始值,当前值,时分频率配置。而左半部分第三个块的第一个方框储存的则是对应的Local Vector Table 0,即表示时间中断的中断号。这些值的设置在lapic.c文件中完成。当计数器溢出时就按照Local Vector Table 0将中断号发送给CPU,CPU通过eflag寄存器上的值判断当前是否允许系统中断,如果允许中断,就进行响应,将eip与cs入栈后通过汇编指令int n(n为中断号)调用中断处理程序根据中断号进行中断处理。中断号会一直传递到trapframe中的trapno(trap number)上,然后进入trap函数。当中断号为时间中断对应的32时,trap函数就会利用前文的代码调用yield强制进程交出cpu的使用权。
sleep分析
在开始分析sleep前,我们先了解一下sleep以及后续的wakeup,wait等函数的存在意义。通过前文的分析,我们大致了解了系统进程切换的过程。但在一个多进程的系统中,进程之间的相互协作,同步也是一个问题。在xv6系统中,系统通过sleep与wakeup来完成进程之间的同步协作,当一个进程作为消费者需要另一个进程作为生产者生产的产品时,如果出现缺货,消费者就进入sleep,直到生产者产出产品利用wakeup唤醒消费者消费。这就是xv6系统中sleep与wakeup这组函数存在的意义,而wait函数就像一个等待指令,当wait被调用,消费者进程就试图消费一个产品,如果成功消费,那么wait就直接返回,否则就进入sleep直到产品被生产出来。
了解了这几个函数的实际意义,我们再来详细的解析这几个函数在xv6中的实现,首先是sleep函数。阅读它的头部注释:
// Atomically release lock and sleep on chan.
// Reacquires lock when awakened.
从注释中我们得知该函数的作用是原子的释放锁并在chan上sleep,当被唤醒时重新获取被释放的锁。接下来我们阅读sleep实现的前半部分,即检查判断是否符合sleep条件的代码段:
if(p == 0)
panic("sleep");
if(lk == 0)
panic("sleep without lk");
// Must acquire ptable.lock in order to
// change p->state and then call sched.
// Once we hold ptable.lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup runs with ptable.lock locked),
// so it's okay to release lk.
if(lk != &ptable.lock){ //DOC: sleeplock0
acquire(&ptable.lock); //DOC: sleeplock1
release(lk);
}
其中p是当前进程的进程指针,显然若p为空,那么一定出现了bug,需要panic。而对于第二个if判断,我们需要回顾一下sleep的意义。sleep是当进程试图获取尚未准备好的产品时调用的函数,对于这样的产品,它存在数据冲突的可能性。即消费者进程和生产者进程都会对它进行操作,因此我们需要在申请该产品时申请对应的锁。对于sleep函数而言,所有调用它的函数都需要传入两个参数,其中第二个就是这个锁。当sleep函数发现该锁为空时,那么一定也出现了bug。再来看伴有一段注释的if判断语句,以下为翻译:
“为了修改p->state后调用sched函数,必须先获取ptable.lock。这样我们可以保证不会错过任何唤醒信号,因为唤醒需要在持有ptable.lock时运行。因此可以先释放之前申请的锁。”
这段代码保证了sleep在进入sched之前支持有ptable.lock这一个锁,至于为什么只能持有这个锁,原因已经在前文sched函数的解析中给出。这里需要注意的是释放“产品锁”会不会导致在进程运行到修改pstate前出现唤醒信号,而却因为进程还未处于SLEEPING状态而错过信号?答案是否定的,在下一小节对wakeup的解析中我们将了解到wakeup需要获取ptable.lock才能运行,而sleep在释放“产品锁”之前已经确保了ptable.lock的获取,因此杜绝了wakeup在此期间成功发出对应唤醒信号的可能性。
再看下一段代码:
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
在完成进程状态的确认后,sleep将进程结构指针上的chan置为传入的第一个参数。对于这个参数,注释的描述是进程将“睡在chan上”。这里实际上是一个类似等待队列的形式。由于在多进程系统中有可能出现有多个进程在申请同一个数据结构时进入sleep,那么当生产者进程准备好该数据结构时就需要把所有这类进程全部唤醒,xv6系统通过chan(channel)变量来设定每个进程沉睡在哪个队列中。这里的chan实际上是一个与“产品”相关的一个地址,实现者需要保证每个申请同类数据结构的进程都沉睡在同一个chan(地址)上,而wakeup将会利用这个chan将所有该类型的进程唤醒,具体方式将在下一小节进行分析。
随后sleep进程将进程状态修改为SLEEPING,然后就完成了全部的准备工作,接下来可以进入sched,后续的过程已经在前文做出解析,不再赘述。
接下来我们阅读sleep函数的最后一部分,也就是被唤醒后从sched返回的部分:
// Tidy up.
p->chan = 0;
// Reacquire original lock.
if(lk != &ptable.lock){ //DOC: sleeplock2
release(&ptable.lock);
acquire(lk);
}
从sched返回后,进程状态已经改为RUNNING,因此只需要将chan置为空,然后还原前文对锁的操作,即释放ptable.lock,并重新获取“产品锁”。到此为止sleep的工作结束。
wakeup分析
wakeup函数在获取ptable.lock后调用了wakeup1进行进一步操作,因此我们有限解析wakeup1函数:
//PAGEBREAK!
// Wake up all processes sleeping on chan.
// The ptable lock must be held.
static void
wakeup1(void *chan)
{
struct proc *p;
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p->state == SLEEPING && p->chan == chan)
p->state = RUNNABLE;
}
阅读wakup1的头部注释,我们能了解到wakeup1的作用是唤醒所有沉睡在chan上的进程,在这期间ptable.lock必须被当前进程所持有。这里的chan指的是传入wakeup1的形参,这里要求代码编写者需要保证此处的产即为沉睡进程入睡时传入的chan,否则唤醒信号将会丢失。再来看代码实现,wakeup1的主题是一个单层循环,它遍历了整个进程表的进程,寻找所有处于SLEEPLING状态且p->chan等于chan的进程,将符合条件的目标进程状态改为RUNNABLE,这样就算完成了唤醒。
而wakeup的实现则更为简单:
// Wake up all processes sleeping on chan.
void
wakeup(void *chan)
{
acquire(&ptable.lock);
wakeup1(chan);
release(&ptable.lock);
}
可以看到它申请了ptable.lock后就调用了wakeup1,这里是因为在wakeup1内需要持有ptable.lock来修改进程状态。在从wakeup1返回后,wakeup函数释放ptable.lock并返回。到此为止wakeup的工作结束。
wait分析
在前文的分析中,wait作为wait,sleep,wakeup等组成xv6系统进程间同步协作的重要函数成员之一,是sleep函数常见的调用者。它的作用主要是等待所有当前进程的子进程结束并回收这些进程的资源。首先阅读wait函数的头部注释:
// Wait for a child process to exit and return its pid.
// Return -1 if this process has no children.
通过头部注释可以得知,wait函数的作用是等待一个子进程exit,然后返回退出子进程的pid;如果该进程已经没有子进程那么返回-1。
那么我们根据这段描述可以推测在一个父进程中,wait函数的使用方式应该类似下方代码所示:
for(;;){
if(wait() == -1)
return 0;
}
并且使用的位置应该位于一个函数的末端,在函数完成所有工作后用于回收所有子进程。具体分析wait函数的实现:
int
wait(void)
{
struct proc *p;
int havekids, pid;
struct proc *curproc = myproc();
...
开头的一段初始化了整个实现中用到的参数,其中指针p用于遍历进程表中的进程,havekids用于计算当前找到的子进程数,pid用于记录找到的子进程的pid。最后一个curproc利用myproc函数来初始化,目的是获取当前进程的进程信息。
acquire(&ptable.lock);
for(;;){
// Scan through table looking for exited children.
havekids = 0;
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->parent != curproc)
continue;
havekids = 1;
if(p->state == ZOMBIE){
// Found one.
pid = p->pid;
kfree(p->kstack);
p->kstack = 0;
freevm(p->pgdir);
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->killed = 0;
p->state = UNUSED;
release(&ptable.lock);
return pid;
}
...
}
接下来这段代码的主体是一个双层for循环,在进入循环前,wait函数先获取了进程表的锁ptable.lock,保证在遍历过程中不会受到其他进程的干扰。
可以看出第一层for循环没有任何终止条件和迭代条件,每次循环的操作都将havekids置零,然后进入第二层循环。
在第二层循环中,wait函数利用指针p来遍历进程表中的所有进程,每遍历到一个进程,若其不是当前进程的子进程,则遍历下一个进程。否则,当该进程是当前进程的子进程时,将havekids置为1,并判断该子进程的进程状态,若其状态为ZOMBIE,那么就算找到了一个需要回收的子进程。wait将该子进程的资源释放并重置指针p内的所有内容,最后将其状态改为UNUSED,释放进程表锁后返回该子进程的pid。若找到的子进程状态不是ZOMBIE,那么说明该进程还在运行中,wait函数将继续遍历进程表中的下一个进程。
当遍历完所有进程表中的进程后,在一层循环内还有下面一段内容:
...
// No point waiting if we don't have any children.
if(!havekids || curproc->killed){
release(&ptable.lock);
return -1;
}
// Wait for children to exit. (See wakeup1 call in proc_exit.)
sleep(curproc, &ptable.lock); //DOC: wait-sleep
}
在第一个if语句中,wait函数在没有任何子进程或自身已经被kill时直接return -1。
如果上述if没有执行,那么就利用sleep函数使该进程进入休眠,否则一直进行循环将会消耗大量的资源。直到该进程被wakeup时,才会接着进行下一次循环。至此整个wait函数的解析结束。
TODO #2:统计RR调度情况
添加系统调用waitSch
int waitSch(int *rutime, int *retime, int *sltime);
# Description: 拓展wait()系统调用,在子进程结束时同时获取系统调度该进程的相关信息。
# Input: int *rutime / *retime / *sltime - 指向int的指针,在调用后分别返回程序处于running/ready/sleeping状态下的时间
# Output: 为int类型,在调用成功时返回进程pid,失败时返回-1。
Tips:
- 1.在proc.h中定义相关字段ctime/rutime/retimr/sltime分别记录进程创建时间,处于各状态下的时间。
- 2.阅读trap.c代码,每次发生时钟中断时判断进程状态,更新相关字段。
- 3.添加系统调用时可参考xv6文档:Chapter3:Traps, interupts, and drives.
对于这部分实验的分析将分为四部分,第一部分是整体思路分析,第二部分是实现代码的关键核心即其解析;第三部分是在文档中各处的细节修改及其分析,最后是waitSch函数的实现。
整体思路分析
根据实验要求,我们需要统计子进程从创建到结束期间,它处于每个状态的时长,并且要同时完成wait函数原先的对子进程的回收工作。因此首先第一点可以明确的就是waitsch函数的实现是在wait函数的基础上进行扩充。接下来我们面临的最大的问题就是:时间从哪里获取?
在前文对于yield函数的解析中,我们补充了一部分对于xv6系统时钟中断实现原理的分析。通过这段分析我们知道xv6系统的时间实际上可以从Local APIC寄存器上的计数器中获取。那么我们能不能直接从这个寄存器上获取当前时间呢。我们可以查看初始化Local APIC寄存器的lapic.c文件中最下方的cmostime函数:
// qemu seems to use 24-hour GWT and the values are BCD encoded
void
cmostime(struct rtcdate *r)
{
struct rtcdate t1, t2;
int sb, bcd;
sb = cmos_read(CMOS_STATB);
bcd = (sb & (1 << 2)) == 0;
// make sure CMOS doesn't modify time while we read it
for(;;) {
fill_rtcdate(&t1);
if(cmos_read(CMOS_STATA) & CMOS_UIP)
continue;
fill_rtcdate(&t2);
if(memcmp(&t1, &t2, sizeof(t1)) == 0)
break;
}
// convert
if(bcd) {
#define CONV(x) (t1.x = ((t1.x >> 4) * 10) + (t1.x & 0xf))
CONV(second);
CONV(minute);
CONV(hour );
CONV(day );
CONV(month );
CONV(year );
#undef CONV
}
*r = t1;
r->year += 2000;
}
可以看出这个函数将形参r赋值,而赋值后的r就包含了一个包含年月日时分秒的时间结构体。这个函数本质上是xv6系统用来获取当前时间的相对底层的实现。它使用cmos_read来读取对应寄存器上的时间量,而这组寄存器实质上组成了一个计时器。因此我们的第一个想法就是在allocproc函数中调用该函数,获取该进程初始化的准确时间并保存在进程指针中。对于实验要求的其他时间量也可以如法炮制,在进程状态切换的节点调用该函数记录时间,头尾时刻相减就能得到每个时间段的长度。
但当我们在proc.h中的proc结构体中加上一个struct rtcdate*元素ctime,然后在allocproc函数中调用cmostime(p->ctime)时,我们会发现xv6系统在启动时会不断地循环在屏幕上闪出“cpu1: starting 1”的字样,这说明方才的修改使得cpu无法正常初始化。但由于缺少其他的debug信息,我最终没能找到触发这个错误的根本原因。那么既然在allocproc上插入该语句会造成系统无法正常启动,那么原因就可能和初始进程在初始化时lapic.c的函数还不能正常运行有关。要避开这个可能存在的问题,可以通过在fork内加入这句语句来实现。具体的来说,如果只针对initproc之后的进程进行计时的话,那么利用fork来操作也是一个不错的选择。于是我们在fork函数从allocproc函数中返回后调用函数cmostime(np->ctime)。但经过测试后我们发现这将触发第14号系统中断,这是一个系统未能用panic捕捉的错误,因此我们还是缺少相关的bug信息。
经过多次尝试后,笔者发现很难直接使用cmostime获取到进程的创建时间,同时读取Local APIC寄存器的操作也有很大的风险。毕竟cmostime的本质也是读取该外部寄存器。那么直接获取时间的思路走不通,我们还有没有其他获悉时间的方式呢?注意到xv6系统的时钟中断机制的实现必然需要定义一个时间片的大小,并且记录下每一个时间片的信息。并且很重要的一点是,xv6系统存在一个sleep系统调用,该系统调用能够根据输入的数值来决定进程sleep的时长,显然我们可以采取与该系统调用相似的方式来衡量时间。这个时间量在xv6系统中的名字为“ticks”。它的本质是计数系统启动以来经过的时间片的数量,而一个时间片的大小是固定的,因此从这种意义上来说,ticks就是一个度量时间的单位。ticks与时间片数量之间的关系由trap函数的如下代码呈现:
// qemu seems to use 24-hour GWT and the values are BCD encoded
switch(tf->trapno){
case T_IRQ0 + IRQ_TIMER:
if(cpuid() == 0){
acquire(&tickslock);
ticks++;
wakeup(&ticks);
release(&tickslock);
}
lapiceoi();
break;
...
可以看到当tf->trapno(trapframe中储存的中断号)为时间中断的中断号时,这代表当前进程已经完成了一个时间片时间的运行。因此trap函数在获取了ticklock后对ticks进行了自增操作。在前文对yield的解析中,trap函数的后半部分对于与此相同的中断信号还将强制当前进程交出cpu的使用权。这一切可以充分地说明,ticks在xv6系统中是一个比较可靠的度量时间的单位。并且它是一个由xv6系统负责更新的时间量,因此不需要我们冒各种风险来自行从外部获取时间。
利用这个量,我们不仅可以在allocproc是直接将当时的tick直接保存在proc结构中视为进程初始化的时间,也可以在进程状态转换的时刻轻松地维护一个记录进程处于各种不同状态的数据结构。
核心代码实现及分析
- proc.h中的修改
根据上一小节总结的思路,我们首先修改proc.h文件中的proc结构体的定义,补充我们所需要的元素变量:
// Per-process state
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table
char *kstack; // Bottom of kernel stack for this process
enum procstate state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall
struct context *context; // swtch() here to run process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
int ctime; // Created time
int rutime; // Running time
int retime; // Ready time
int sltime; // Sleeping time
int endtime; // Finish time
int start; // start timing of a state
int end; // end timing of a state
};
其中第16行到第22行是修改添加的部分。此处的ctime用于记录进程被创建时所处的时间片编号;rutime指进程当前累计处于RUNNING状态的总时间片数量;retime指进程当前累计处于RUNABLE状态的总时间片数量;sltime指进程当前累计处于SLEEPING状态的总时间片数量;endtime指进程exit时所处的时间片;start表示某一个状态时间段的开始时间片数量,end表示某一个状态时间段的结束时间片数量。利用这些变量元素,我们在proc.c中可以实现一个用于记录进程之间状态转换时的时刻的函数,函数名“changestate”,实现如下:
int
changestate(int from, int to, struct proc *p)
{
struct proc *curproc = p;
if(from == SLEEPING){
if(to == SLEEPING)
return 0;
curproc->end = ticks;
curproc->sltime += (curproc->end - curproc->start);
curproc->start = curproc->end;
if(to == RUNNING){
panic("sleeping to running\n");
}
}
else if(from == RUNNABLE){
if(to == RUNNABLE)
return 0;
curproc->end = ticks;
curproc->retime += (curproc->end - curproc->start);
if(to == SLEEPING){
panic("runnable to sleeping");
}
}
else if(from == RUNNING){
if(to == RUNNING)
return 0;
curproc->end = ticks;
curproc->rutime += (curproc->end - curproc->start);
curproc->start = curproc->end;
}
else{
curproc->start = ticks;
}
if(to == ZOMBIE){
curproc->endtime = ticks;
}
return 0;
}
该函数的使用方式是传入当前进程状态和即将转变的进程状态以及该进程指针。然后通过这些传入的信息来更新这次状态改变后该进程累积的各个状态持续时间为多少。由于我们只关心程序处于SLEEPING,RUNNABLE,RUNNING三种状态的时长,因此我们的实现逻辑如下:
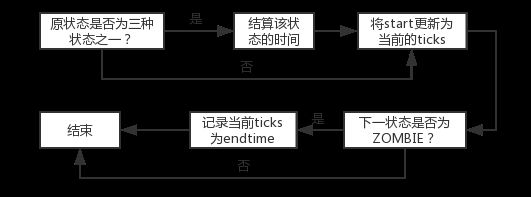
文档中各处的细节修改及其分析
接下来我们需要将上述的关键函数应用在文档中所有涉及进程状态改变的函数上,如果出现了遗漏就会使最终的统计结果有误。我们按allocproc,userinit,fork,exit,scheduler,yield,sleep,wakeup,kill的顺序进行展示。
- 修改allocproc
我们需要在每个进程通过allocproc初始化时都初始化我们新增在proc结构指针中的内容,将其创建时间,p->start,p->end都置为当前的ticks:
found:
p->state = EMBRYO;
p->pid = nextpid++;
p->ctime = ticks;
p->rutime = 0;
p->retime = 0;
p->sltime = 0;
p->start = ticks;
p->end = ticks;
- 修改userinit
作为第一个用户进程,该进程的初始化早于mp的初始化,因此此时scheduler还未开始运行,没有其他程序能为该进程更新其进程状态,所以userinit完成了这项工作,我们在其更新状态前调用changestate进行记录:
// this assignment to p->state lets other cores
// run this process. the acquire forces the above
// writes to be visible, and the lock is also needed
// because the assignment might not be atomic.
acquire(&ptable.lock);
changestate(p->state, RUNNABLE, p); //edit
p->state = RUNNABLE;
release(&ptable.lock);
}
- 修改fork
在fork中,新进程指针从allocproc中返回时处于EMBRYO状态,而fork函数将该子进程的资源进一步初始化完成后,将其状态改为RUNNABLE,此时我们需要在此处调用changestate来记录这个节点。
acquire(&ptable.lock);
changestate(np->state, RUNNABLE, np); //edit
np->state = RUNNABLE;
release(&ptable.lock);
return pid;
}
- 修改exit
exit函数是一个进程终止的标志,在进程终止时,它的父进程不一定能马上回收它,因此我们需要在exit时就记录该进程的临终时间信息。
changestate(curproc->state, ZOMBIE, curproc); //edit
// Jump into the scheduler, never to return.
curproc->state = ZOMBIE;
sched();
panic("zombie exit");
}
- 修改scheduler
scheduler作为xv6系统的调度器的实现,它在选择RUNNABLE的进程指针后,将其状态改为RUNNING并移交cpu的使用权,因此我们需要在此处用changestate函数记录这个节点。
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
// Switch to chosen process. It is the process's job
// to release ptable.lock and then reacquire it
// before jumping back to us.
c->proc = p;
switchuvm(p);
changestate(p->state, RUNNING, p); //edit
p->state = RUNNING;
swtch(&(c->scheduler), p->context);
switchkvm();
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&ptable.lock);
- 修改yield
scheduler修改的是新进程的状态,而yield修改的则是旧进程的状态,它将进程从RUNNING改为RUNNABLE并进入sched函数,因此我们需要在此处使用changestate函数记录这个节点。
// Give up the CPU for one scheduling round.
void
yield(void)
{
acquire(&ptable.lock); //DOC: yieldlock
changestate(myproc()->state, RUNNABLE, myproc()); //edit
myproc()->state = RUNNABLE;
sched();
release(&ptable.lock);
}
- 修改sleep
由于进程交出cpu控制权有多种方式,其中yield是因为时间中断而交出使用权,除了yield,sleep也是修改旧进程状态的一种函数,它将进程状态修改为SLEEPING,同样我们也使用changestate来记录。
// Go to sleep.
changestate(myproc()->state, SLEEPING, myproc()); //edit
p->chan = chan;
p->state = SLEEPING;
- 修改wakup
sleep修改的状态,将由wakeup改为RUNNABLE,并等待scheduler将其改为RUNNING,因此我们同样需要记录wakeup的修改节点。
static void
wakeup1(void *chan)
{
struct proc *p;
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p->state == SLEEPING && p->chan == chan){
changestate(SLEEPING, RUNNABLE, p); //edit
p->state = RUNNABLE;
}
}
- 修改kill
kill函数在目标进程处于SLEEPING状态时将其唤醒,因此我们在此处也调用changestate来记录这个变化。
// Wake process from sleep if necessary.
if(p->state == SLEEPING){
changestate(SLEEPING, RUNNABLE, p); \\edit
p->state = RUNNABLE;
\end{lstlisting}
\subsubsection{系统调用waitSch的实现}
waitSch除了打印子进程的各个状态累计时间外,其余行为与wait无异。而在实际实现上,waitSch也仅仅比wait函数增加了6行cprintf代码,它们是:
\begin{lstlisting}[language=C]
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->parent != curproc)
continue;
havekids = 1;
if(p->state == ZOMBIE){
// Found one.
pid = p->pid;
cprintf("pid: %d Created time: %d\n", pid, p->ctime); \\add
cprintf("pid: %d RUNNING time: %d\n", pid, p->rutime); \\add
cprintf("pid: %d RUNNABLE time: %d\n", pid, p->retime); \\add
cprintf("pid: %d SLEEPING time: %d\n", pid, p->sltime); \\add
cprintf("pid: %d FINISHI time: %d\n", pid, p->endtime); \\add
cprintf("pid: %d Current time: %d\n", pid, ticks); \\add
kfree(p->kstack);
p->kstack = 0;
freevm(p->pgdir);
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->killed = 0;
p->state = UNUSED;
release(&ptable.lock);
return pid;
}
}
至于将waitSch包装成系统调用的工作,已经在先前的实验中做出过详细的解析,在本报告中不再赘述。至此我们完成了waitSch功能的实现。
编写用户应用程序RRStatistics.c
- 1.接收输入(n),创建n个子进程执行相同的大规模cpu运算
- 2.调用waitSch获取各进程处于各状态下的时间
- 3.统计默认RR调度算法下的所有进程的平均轮转时间
首先展示大规模运算的代码:
long long calcunumber(long long n){
long long i, j;
long long result = 0;
for(i=0;i < n;i++){
result = 1;
for(i = 0;i < n;i++){
for(j = 0;j < n;j++){
result += 1;
result *= -1;
}
}
}
return result;
}
通常来说,子进程在正常运行过程中并不会被置为SLEEPING状态,但为了体现waitSch的功能,我们让子进程的代码再调用三个子进程,然后在子进程代码末尾调用普通的wait函数回收这些子进程:
int child(){
long long i, pid, a;
for(i=0; i<3; i++){
if((pid = fork()) == 0){
a = calcunumber(15000);
printf(0, "pid = %d, %d\n", pid, a);
break;
}
else{
a = calcunumber(5000);
printf(0, "pid = %d, %d\n", pid, a);
}
}
for(i=0; i<5; i++){
wait();
}
exit();
}
然后为了将console输入的字符串参数n变为int型数据,我们需要string2int:
int string2int(char *s){
int i, len = 0;
int res = 0;
len = strlen(s);
for(i = 0;i < len;i++){
res = 10*res + (s[i] - 48);
}
return res;
}
最后是main函数:
int main(int argc, char *argv[])
{
int n = 0, pid, a;
int i;
n = string2int(argv[1]);
for(i = 0;i < n; i++){
if((pid = fork()) == 0){
child();
break;
}
else{
a = calcunumber(5000);
printf(0, "pid = %d, %d\n", pid, a);
}
}
for(i=0; i < n; i++){
waitSch();
}
exit();
}
将上述函数放在文件RRstatistics.c内,在Makefile内将其包装为console命令。就可以在console中调用命令RRstatistics进行测试。在进行测试前我们先根据上方提供的实现来预测我们将会得到的输出。首先我们的输入是RRstatistics n,此处以n=2为例,那么我们应该得到的输出包括父进程和子进程的子进程在运营过程中输出的pid信息,以及最关键的在调用waitSch后,将会看到被回收的两个子进程的各个状态的时间信息。
以下为运行截图:
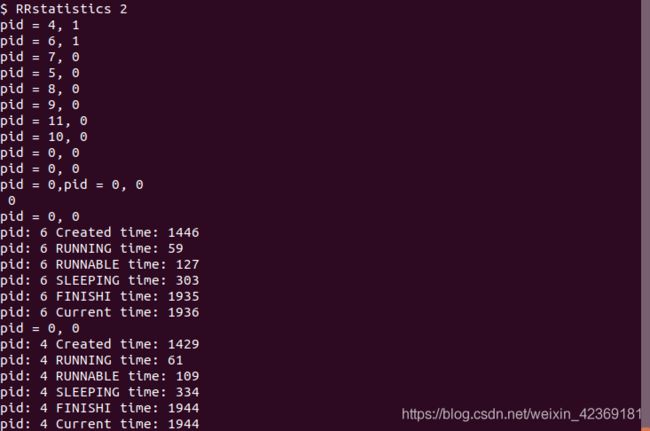
将实验结果整理为表格

通过统计我们可以得到这两个进程的平均轮转时间为:
1 2 × ( 59 + 303 + 127 + 61 + 334 + 109 ) = 496 \frac{1}{2}\times(59+303+127+61+334+109) = 496 21×(59+303+127+61+334+109)=496
TODO #3:实现Priority based scheduling
实现Priority based scheduling调度算法
Tips:
- 1.在proc.h中定义相关字段priority记录进程优先级
- 2.子进程继承父进程优先级
根据题目提示,在proc.h中添加priority字段的相关定义。将其添加进proc结构体的定义当中:
// Per-process state
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table
char *kstack; // Bottom of kernel stack for this process
enum procstate state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall
struct context *context; // swtch() here to run process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
int ctime; // Created time
int rutime; // Running time
int retime; // Ready time
int sltime; // Sleeping time
int endtime; // Finish time
int start; // Start timing of a state
int end; // End timing of a state
int priority; // Scheduling priority // add
};
在添加了新的proc结构体元素后,就应该同时在allocproc函数和fork函数等地方同步初始化或继承这个值。在allocproc处,我们为每个进程将priority初始化为相同的值:
found:
p->state = EMBRYO;
p->pid = nextpid++;
p->ctime = ticks;
p->rutime = 0;
p->retime = 0;
p->sltime = 0;
p->start = ticks;
p->end = ticks;
p->priority = 3; // add
在fork中,根据实验提示,我们令子进程继承父进程的priority:
// Copy process state from proc.
if((np->pgdir = copyuvm(curproc->pgdir, curproc->sz)) == 0){
kfree(np->kstack);
np->kstack = 0;
np->state = UNUSED;
return -1;
}
np->sz = curproc->sz;
np->priority = curproc->priority; // add
np->parent = curproc;
*np->tf = *curproc->tf;
将priority的环境配置好后,我们就可以开始着手实现基于priority的调度算法。由于我们只是修改了xv6系统的默认调度算法,并没有改变xv6系统的整个进程架构,因此我们还是在原有的scheduler函数的基础上思考该如何修改。
首先可以肯定的一点是,原有scheduler的双重循环这个特点不变,并且循环外的代码也无需作出修改。在循环内,诸如sti和acquire(&ptable.lock)以及release(&ptable.lock)这样的操作也无需作出修改。因此我们可以得到我们的初始框架:
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
int priority;
c->proc = 0;
for(;;){
// Enable interrupts on this processor.
sti();
// Loop over process table looking for process to run.
acquire(&ptable.lock);
...
release(&ptable.lock);
}
}
这里我们规定priority的数值越大,进程的优先级越高,并且priority的数值范围是0到10。于是我们需要在如上所示的框架的第13行到第15行之间插入代码,完成从进程表中挑选优先级最高的进程来执行的工作。这里我们最终采用的办法是使用与缺省scheduler相似的方式,即遍历ptable。但与原scheduler不同的是,原来的调度器在找到第一个RUNNABLE进程后,就确定它为目标进程,并开始切换虚拟内存空间等一系列操作。我们为了实现基于priority的调度,在进入ptable前设置一个名为priority的flag,其值为-1,进入ptable后,对于找到的每个RUNNABLE进程,都取其priority值与当前的flag进行比较,如果该进程的值较大,则选择该进程指针作为待定的目标指针,并将flag更新为该指针的priority值。若该进程的值等于当前的flag值,那么就比较两者的p->start,由于两者的状态都为RUNNABLE,因此p->start的值就代表了双方进入队列的时间点。当该进程的p->start小于当前待定的目标进程的start时,就将该进程选为新的待定进程。
根据上述规则遍历一次ptable,我们就能保证在ptable中存在RUNNBALE进程时选出其中优先级最高的一个。具体的实现如下所示:
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
int priority;
c->proc = 0;
for(;;){
// Enable interrupts on this processor.
sti();
priority = -1;
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
if(p->priority > priority){
c->proc = p;
priority = p->priority;
}
else if(p->priority == priority && p->start < c->proc->start){
c->proc = p;
}
}
if(priority != -1){
p = c->proc;
switchuvm(p);
changestate(p->state, RUNNING, p);
p->state = RUNNING;
swtch(&(c->scheduler), p->context);
switchkvm();
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&ptable.lock);
}
}
值得注意的是,在遍历ptable退出内层循环后,我们需要判断priority是否还是-1,若还是-1说明ptable中没有可以运行的进程。若不是-1,那么我们只需要仿造缺省的scheduler的办法完成准备工作,并把cpu的使用权移交给目标进程即可。以上就是基于priority实现的优先级调度,在优先级相同时采取FCFS原则。值得一提的是缺省的scheduler并没有真正意义上实现FCFS原则,但在这个priority based调度器中,我们利用上一节添加的p->start完成了这个规则的执行。
禁用时钟中断
根据题目要求,我们要实现的是一个非抢占式的优先级调度,因此单靠替换scheduler只能解决调度时的优先级选择问题。如果不禁用时间中断,我们实现的调度算法就更像是一个特殊的抢占式优先级算法,因此我们需要禁用时间中断。
具体来说,由于我们还需要时间片ticks作为计数器来计算时间,因此我们要保留时间中断这个硬件机制本身,而去修改中断处理程序,也就是修改trap.c,先前我们并未解析过trap.c中的内容,在此我们需要先了解trap.c中处理中断的trap函数的具体实现方式:
//PAGEBREAK: 41
void
trap(struct trapframe *tf)
{
...
switch(tf->trapno){
case T_IRQ0 + IRQ_TIMER:
if(cpuid() == 0){
acquire(&tickslock);
ticks++;
wakeup(&ticks);
release(&tickslock);
}
lapiceoi();
break;
...
// Force process to give up CPU on clock tick.
// If interrupts were on while locks held, would need to check nlock.
if(myproc() && myproc()->state == RUNNING &&
tf->trapno == T_IRQ0+IRQ_TIMER)
yield();
...
}
此处我们省去了与时间中断无关的代码段,可以看到第7行到第14行之间,当中断号为时间中断时,ticks自增,这段是我们需要保留的代码。
在第19行到第21行,当中断号为时间中断时并且当前进程状态为RUNNING时,强制进程调用yield交出CPU的使用权,这是实现轮询机制的驱动代码,我们在优先级调度中不需要,因此将这段代码全部注释掉即可。
至此我们在xv6中实现了非抢占式的优先级调度。
添加系统调用 setPriority()
int setPriority(int pid, int priority)
// Description: 更改指定进程的优先级
// Input: int pid - 所指定的进程的pid,int priority - 新的优先级
// Output: 调用成功返回0,失败返回-1
我们将实现这个功能的基本函数放在proc.c中:
int
setPriority(int priority, int pid)
{
struct proc *p;
if(priority > 10 || priority < 0){
return -1;
}
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->pid == pid && p->state != UNUSED){
p->priority = priority;
release(&ptable.lock);
return 0;
}
}
release(&ptable.lock);
return -1;
}
可以看到这个函数在给定的priority超出我们先前的规定范围时,将拒绝修改,并返回-1。若priority是一个合法的值,那么函数就申请ptable.lock,ptable中遍历寻找pid为给定值的非空进程,一旦找到,就将priority值赋给该进程,然后release申请的ptable.lock,返回0。
但若是程序没有在循环内就返回,这说明给定的pid当前不存在对应的进程,应该释放ptable.lock后返回-1。
作为一个需要传入参数的系统调用,它与我们之前实现的系统调用稍有不同,我们可以仿造系统调用sleep(n)来将setPriority包装成系统调用。与之前实现的系统调用相同,我们同样需要在defs.h,syscall.c,syscall.h,user.h,usys.S中声明这个系统调用链。区别在于sysproc.c中对于sys_setPriority的实现。
由于系统调用机制要求sys_xxx类的函数在定义时都没有形参,因此我们需要时用argint函数来读取传入的参数,具体使用方法如下:
int sys_setPriority(void){
int priority, pid;
if(argint(0, &priority) < 0){
return -1;
}
if(argint(1, &pid) < 0){
return -1;
}
return setPriority(priority, pid);
}
通过上述操作,我们就完成了setPriority系统调用的实现和添加。
编写用户应用程序PBStatistics.c
要求:
- 1.接收输入(n),创建(4*n)个子进程
- 2.父进程调用setPriority()分别赋予将各子进程pid%4+1的优先级
- 3.调用waitSch()获取各进程处于各状态下的时间
- 4.统计Priority based scheduling调度算法下各优先级进程平均轮转时间
- 5.统计Priority based scheduling调度算法下所有进程平均轮转时间
PBStatistics.c的实现
PBStatistics.c的实现与前文RRstatistics.c的实现大同小异,它们同样需要大规模的cpu运算来凸显调度的效果,也需要读取console输入的参数n,因此我们可以在RRstatistics.c的基础上,只对main函数做出修改就可以实现PBStatistics.c,其中main函数修改成如下所示:
int main(int argc, char *argv[])
{
int n = 0, pid, a;
int i;
n = 4 * string2int(argv[1]);
for(i = 0;i < n; i++){
if((pid = fork()) == 0){
child();
break;
}
else{
setPriority((pid % 4)+1, pid);
a = calcunumber(5000);
printf(0, "pid = %d, %d\n", pid, a);
}
}
for(i=0; i < n; i++){
waitSch();
}
exit();
}
它与RRstatistics的main函数大同小异,不同之处在于n的取值为原来的4倍,并且由于该程序运行在非抢占式的优先级调度上,因此父进程在运行到第18行之前不会交出cpu的使用权,从而我们可以在第12行调用setPriority函数依次修改每个子进程的优先级。最后由父进程执行waitSch来获取各进程处于个状态的时间。其他的部分皆与RRstatistics的实现无异,因此不在赘述。
以上就是PBStatistics.c的实现。
调用以及统计结果
我们通过在命令行输入"PBStatistics 4"来测试该调用。以下是部分截取的输出结果:
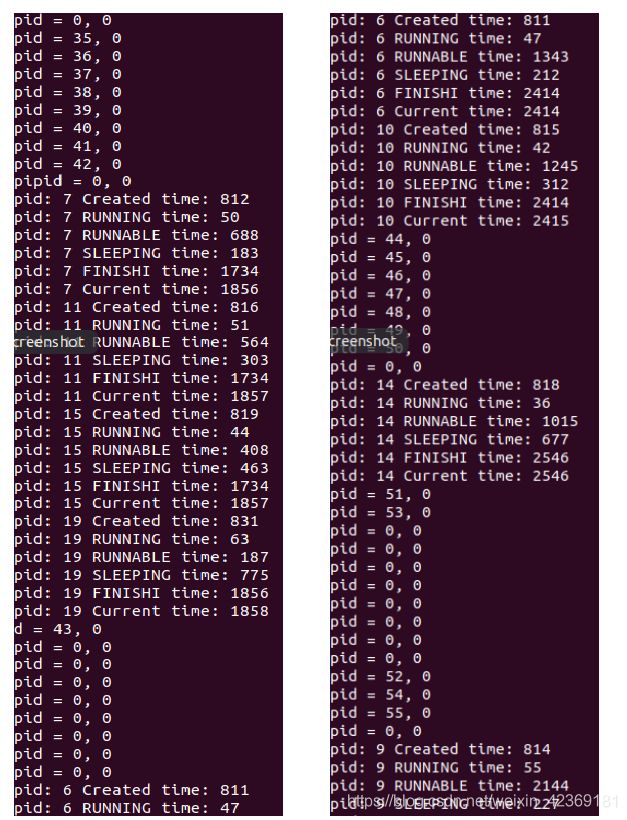
由于结果内容过多,完整的结果我们将展示在附录中,此处我们只展示了部分调用waitSch函数时获取的各进程各状态的信息,其中左图在前,右图在后,左图的最后两行对应右图的前两行。通过统计该结果返回的所有信息(见附录),我们可以得到:
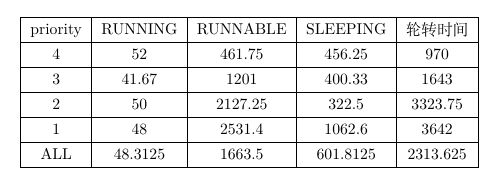
分别统计总的平均轮转时间和每个优先级的轮转时间,我们能得到:
TODO #4:比较RR/Priority based scheduling
解释TODO #2 RRStatistics.c输出
RRstatistics.c的输出结果截图已经在前文展示,此处仅再次展示表格形式的统计结果:
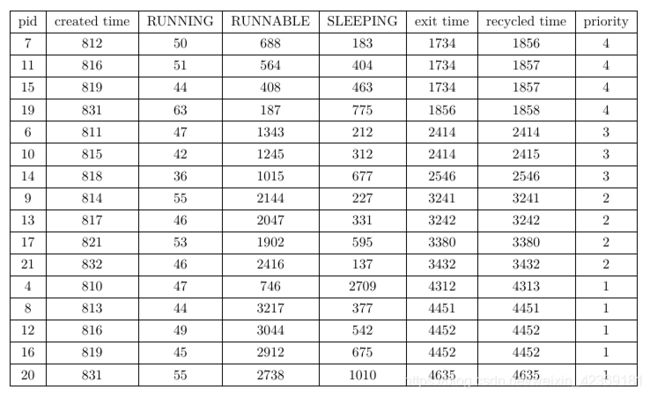
RRstatistics的运行结果是基于xv6默认RR调度的实现结果,对于RR调度,每个进程的优先级是平等的,它们的执行顺序仅仅与任务提交的先后有关,并且每个进程执行完一个时间片后都会让出cpu的使用权,因此即便先提交了一个非常耗时的任务,后续提交的任务也能够在可以预期的时间内获取cpu的计算资源。我们可以看到对于RRstatistics结果中的两个子进程的统计信息,两者的创建时间分别为1446和1429,但两者的exit时间为1935和1944,这说明两个任务在此期间是交替执行的。并且每个子进程本身也有子进程,因此两者都有一定的SLEEPING时间来回收其子进程。总的来说,两个子进程的各个状态的累计时间差距不大,充分体现了RR调度的特点。
解释TODO #3 PBStatistics.c输出
首先根据总的平均轮转时间和每个优先级的平均轮转时间,我们可以发现优先级越高,平均轮转时间越短,这与我们priority based调度器的初衷相符。具体来看每个进程的统计细节,我们先取pid为15,19,6,10,13,17,8,12,4的进程为例:
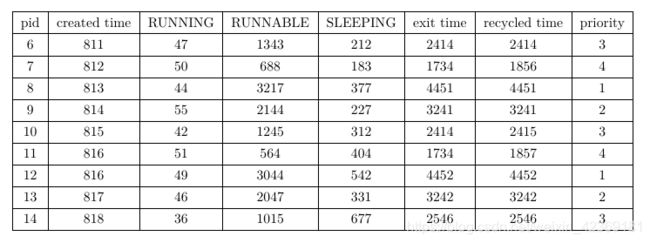
这些进程集中在时间811到818之间被创建,并根据其pid被赋予了不同的调度优先级别。由于他们被分配的cpu计算任务本身是完全相同的,因此它们的累计RUNNING时间并没有很大的差别,大致集中在40至50个时间片左右,不同的优先级影响到的实际上是它们处于RUNNABLE的时间长度。我们可以看到优先级为4的两个进程7和11,它们的RUNNABLE时间都在700个时间片以下,这说明它们在就绪后很快就获得了cpu的使用权。而优先级为3的进程6与10以及14的RUNNABLE时间则均为1000个时间片以上,这远远大于优先级为4的进程的RUNNABLE时间,这说明进程6和进程10的就绪状态持续了较长的时间才得到cpu的使用权。同样的我们能发现优先级为2的进程的RUNNABLE时间大致在2100左右,优先级为1的进程们的RUNNABLE时间在3000以上,呈逐级递增的形式。
在PB调度方式的调度下,我们能发现同样是在时间点815左右创建的这些进程,它们完成任务并exit的时间却截然不同,并根据各个进程不同的优先级分为四个层次:
- 第一个层次为优先级4的进程,退出时间为1800左右
- 第二个层次为优先级3的进程,退出时间为2500左右
- 第三个层次为优先级2的进程,退出时间为3200左右
- 第四个层次为优先级1的进程,退出时间为4400左右
可以看到优先级越高,进程越先被执行完毕。这与我们实现PB调度器和PBStatistics文件的初衷相符,说明我们的实现基本无误。
我们再从同一个优先级的统计数据来分析相同优先级进程之间的竞争:

我们取优先级为4的四个进程为例,作为四个优先级最高的进程它们的RUNNABLE时间都不长,并且pid越大RUNNABLE时间越短,这是因为它们的父进程越晚创建它们,它们就越晚进入就绪队列,而它们所需的RUNNING时间只有50个时间片左右。在优先级调度中,它们的父进程在将他们全部创建之前不会退出cpu,而该父进程的第一个子进程pid为4,因此在这个双cpu的系统中,初始时两个cpu将分别被父进程和pid为4的子进程占用,因此优先级为4的这四个子进程将不能第一时间取得cpu的使用权。
我们可以注意到它们的SLEEPING时间呈随pid递增的状态,实际上,这在所有同级priority进程之间是常态,例如优先级为1的5个进程:
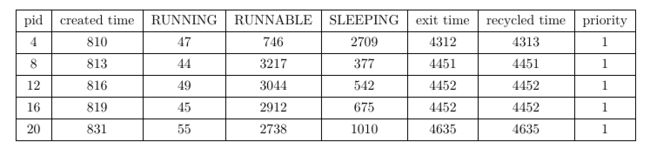
可以看到除了pid为4的进程,其余进程的SLEEPING时间呈随pid递增的形式。这是因为它们的子进程也继承了它们的优先级,并且执行顺序取决于创建顺序的先后,因此pid越小,它的子进程就越早进入就绪队列。而对于pid为4的进程,它作为父进程最早创造的子进程,虽然优先级较低,但在系统还处于空闲状态是就占有了cpu,因此它的RUNNABLE时间很短,但当他创建完它的子进程后,由于它的子进程继承了它的低优先级,但当它进入SLEEPING,此时已经有其他兄弟进程在就绪队列中以较高的优先级存在,作为优先级最低的子进程,它的子进程,将在最后一批被处理,这使得它的SLEEPING时间特别的长。
最后一点是它们的exit time和recycled time,由于我们其他进程的默认优先级为3,因此对于优先级为4的进程,当它们全部exit之后,父进程才能回收它们,而对于其他优先级的进程,父进程将有足够的优先级在这些子进程一退出cpu就获取cpu使用权来回收这些子进程,因此我们能注意到除了优先级为4的子进程,其他进程的exit time和recycled time都基本相同。
分析RR/Priority based scheduling 调度特点
RR scheduling 特点
RR算法的实现是基于时间片的实现的,在挑选进程时,它采用的时FCFS,它与FCFS算法的本质区别在于,当一个进程运行一个时间片后,排在下一个的进程就会抢占它的cpu资源。对于n个cpu,q个进程的系统而言,每个时间片能够运行n个进程,那么一个进程处于RUNNABLE状态后的最长等待时间为 q n \frac{q}{n} nq个时间片。
RR算法的性能很大程度上取决于一个时间片的大小,当时间片的大小取无穷大时,RR算法就退化为FCFS算法。反过来,当时间片非常小时,系统将把大量的时间都花在切换进程上,这会使系统的效率降低。一般性而言,时间片越短,系统cpu的有效运行率越低,但相对的每个进程被分配到的时间会更为平均。RR算法的意义在于区别于FCFS算法,它可以避免一些需要长时间cpu运算的进程长时间占有cpu资源,使得后需提交的进程很长时间内无法获取cpu资源。因此我们设置时间片的原则是过滤那些需要长时间占用cpu资源的进程,对于一般的进程,我们应该尽量让其在一个时间片内完成工作,否则将会把很多cpu运算资源花费在没有意义的进程切换上。根据经验,我们一般把时间片的大小设定为80%的进程运行时间的上限,也就是说有80%的进程将在一个时间片内完成工作。
Priority based scheduling 特点
基于优先级的调度算法考虑了不同进程的重要程度,对于相同优先级的进程,它采用FCFS算法。这个算法的特点是能够以最快的速度完成优先级最高的算法。它又分为抢占式和非抢占式,其中抢占式的算法在新进入队列的进程优先级高于当前进程优先级时,就将cpu的使用权让给该新的进程。而非抢占式的调度算法则只在当前进程完成工作退出后才根据优先级来挑选下一个运行的进程。非抢占式的调度算法在一些特殊情况下会退化为FCFS算法,而抢占式的算法在高优先级的进程不断的进入队列时,将有可能造成一些低优先级的进程出现饥饿。
附录
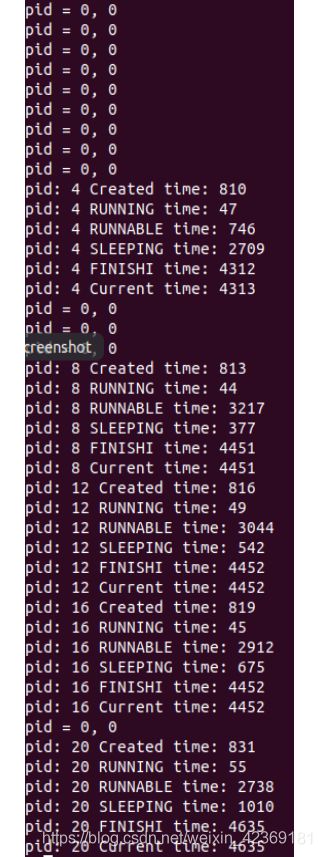
PBStatistics.c运行结果
以下为PBStatistics.c的运行结果的完整截图:


实验源代码
本次实验的源代码已上传至百度云:
链接: \url{https://pan.baidu.com/s/1k1iZbekwPLU01Tw464H88g} 提取码: 53gw
引用自:https://baike.baidu.com/item/xv6/8546040?fr=aladdin ↩︎
https://legacy.gitbook.com/book/th0ar/xv6-chinese/details ↩︎
https://blog.csdn.net/guzhou_diaoke/article/details/79184025 ↩︎