小 T 导读:TDengine 是专为时序数据而研发的大数据平台,存储和计算都针对时序数据的特点量身定制,在支持标准 SQL 的基础之上,还提供了一系列贴合时序业务场景的特色查询语法,极大地方便了时序场景的应用开发。TDengine 提供的特色查询包括数据切分查询和窗口切分查询,本文将从语法层面深入解读这两种特色查询。
数据切分查询
根据业务需要,有时我们需要按一定的维度对数据进行切分,当在切分出的数据空间内进行一系列的计算时,就需要使用数据切分子句,语法如下:PARTITION BY part_list
在上述语法中,part_list 可以是任意的标量表达式,包括列、常量、标量函数和它们的组合。
时序数据库(Time Series Database)TDengine 按如下方式处理数据切分子句:
- 数据切分子句位于 WHERE 子句之后;
- 数据切分子句将表数据按指定的维度进行切分,每个切分的分片进行指定的计算。计算由之后的子句定义(窗口子句、GROUP BY 子句或 SELECT 子句);
- 数据切分子句可以和窗口切分子句(或 GROUP BY 子句)一起使用,此时后面的子句作用在每个切分的分片上。例如,将数据按标签 location 进行分组,并对每个组按 10 分钟进行降采样,取其最大值。
select max(current) from meters partition by location interval(10m)数据切分子句最常见的用法就是在超级表查询中,按标签将子表数据进行切分,然后分别进行计算。特别是 PARTITION BY TBNAME 用法,它将每个子表的数据独立出来,形成一条条独立的时间序列,极大地方便了各种时序场景的统计分析。
窗口切分查询
TDengine 支持按时间段窗口切分方式进行聚合结果查询,比如温度传感器每秒采集一次数据,但需查询每隔 10 分钟的温度平均值,这种场景下可以使用窗口子句来获得需要的查询结果。想要让查询的数据集合按照窗口切分成查询子集并进行聚合,就需要用到窗口子句,窗口包含时间窗口(time window)、状态窗口(status window)、会话窗口(session window)三种窗口。其中时间窗口又可划分为滑动时间窗口和翻转时间窗口。窗口切分查询语法如下:
SELECT select_list FROM tb_name
[WHERE where_condition]
[SESSION(ts_col, tol_val)]
[STATE_WINDOW(col)]
[INTERVAL(interval [, offset]) [SLIDING sliding]]
[FILL({NONE | VALUE | PREV | NULL | LINEAR | NEXT})]窗口子句的规则
- 窗口子句位于数据切分子句之后,GROUP BY 子句之前,且不可以和 GROUP BY 子句一起使用;
窗口子句将数据按窗口进行切分,对每个窗口进行 SELECT 列表中表达式的计算,SELECT 列表中的表达式只能包含:
- 常量
- _wstart 伪列、_wend 伪列和_wduration 伪列
- 聚集函数(包括选择函数和可以由参数确定输出行数的时序特有函数)
- 包含上面表达式的表达式
- 且至少包含一个聚集函数
- 窗口子句不可以和 GROUP BY 子句一起使用;
- WHERE 语句可以指定查询的起止时间和其他过滤条件。
FILL 子句
FILL 语句指定的是某一窗口区间数据缺失情况下的填充模式。填充模式包括以下几种:
- 不进行填充:NONE(默认填充模式);
- VALUE 填充:固定值填充,此时需要指定填充的数值。例如:FILL(VALUE, 1.23)。这里需要注意,最终填充的值受由相应列的类型决定,如 FILL(VALUE, 1.23),相应列为 INT 类型,则填充值为 1;
- PREV 填充:使用前一个非 NULL 值填充数据,例如:FILL(PREV);
- NULL 填充:使用 NULL 填充数据,例如:FILL(NULL);
- LINEAR 填充:根据前后距离最近的非 NULL 值做线性插值填充,例如:FILL(LINEAR);
- NEXT 填充:使用下一个非 NULL 值填充数据,例如:FILL(NEXT)。
在使用 FILL 子句时,需要注意:
- 使用时可能生成大量的填充输出,因此务必指定查询的时间区间。针对每次查询,系统可返回不超过 1 千万条具有插值的结果。
- 在进行时间维度聚合时,返回的结果中时间序列严格单调递增。
- 如果查询对象是超级表,则聚合函数会作用于该超级表下满足值过滤条件的所有表的数据。如果查询中没有使用 PARTITION BY 语句,则返回的结果按照时间序列严格单调递增;如果查询中使用了 PARTITION BY 语句分组,则返回结果中每个 PARTITION 内不会按照时间序列严格单调递增。
时间窗口
时间窗口又可分为滑动时间窗口和翻转时间窗口。INTERVAL 子句用于产生相等时间周期的窗口,SLIDING 用以指定窗口向前滑动的时间,在执行时间窗口查询时,其会随着时间流动向前滑动。在定义连续查询时我们需要指定时间窗口(time window )大小和每次前向增量时间(forward sliding times)。
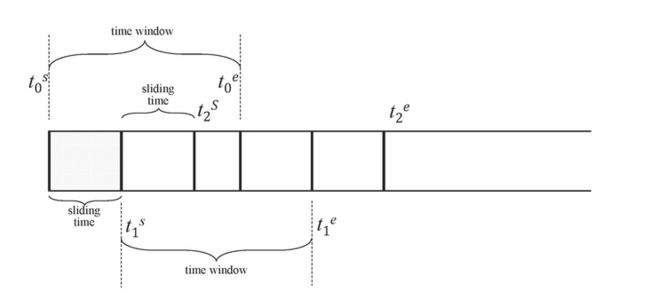
如上图,[t0s, t0e] 、[t1s , t1e]、[t2s, t2e] 分别是执行三次连续查询的时间窗口范围,窗口的前向滑动的时间范围以 sliding time 标识 。查询过滤、聚合等操作按照每个时间窗口为独立的单位执行。当 SLIDING 与 INTERVAL 相等的时候,滑动窗口即为翻转窗口。
INTERVAL 和 SLIDING 子句需要配合聚合和选择函数来使用。以下 SQL 语句非法:SELECT * FROM temp_tb_1 INTERVAL(1m);
SLIDING 的向前滑动的时间不能超过一个窗口的时间范围。以下语句非法:
SELECT COUNT(*) FROM temp_tb_1 INTERVAL(1m) SLIDING(2m);使用时间窗口需要注意:
- 聚合时间段的窗口宽度由关键词 INTERVAL 指定,最短时间间隔 10 毫秒(10a);并且支持偏移 offset(偏移必须小于间隔),也即时间窗口划分与“UTC 时刻 0”相比的偏移量。SLIDING 语句用于指定聚合时间段的前向增量,也即每次窗口向前滑动的时长。
- 使用 INTERVAL 语句时,除非极特殊的情况,都要求把客户端和服务端的 taos.cfg 配置文件中的 timezone 参数配置为相同的取值,以避免时间处理函数频繁进行跨时区转换而导致的严重性能影响。
- 返回的结果中时间序列严格单调递增。
状态窗口
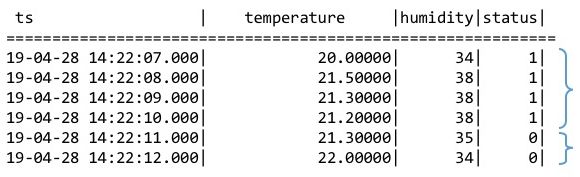
TDengine 使用整数(布尔值)或字符串来标识产生记录时设备的状态量。产生的记录如果具有相同的状态量数值则归属于同一个状态窗口,数值改变后该窗口关闭。如上图所示,根据状态量我们能够确定的状态窗口分别是 [2019-04-28 14:22:07,2019-04-28 14:22:10] 和 [2019-04-28 14:22:11,2019-04-28 14:22:12] 两个。
我们可以使用 STATE_WINDOW 来确定状态窗口划分的列。例如:
SELECT COUNT(*), FIRST(ts), status FROM temp_tb_1 STATE_WINDOW(status);会话窗口
SELECT COUNT(*), FIRST(ts) FROM temp_tb_1 SESSION(ts, tol_val);示例
以智能电表为例,其建表语句如下:
CREATE TABLE meters (ts TIMESTAMP, current FLOAT, voltage INT, phase FLOAT) TAGS (location BINARY(64), groupId INT);针对智能电表采集的数据,以 10 分钟为一个阶段,计算过去 24 小时的电流数据的平均值、最大值、电流的中位数。如果没有计算值,则用前一个非 NULL 值填充。使用的查询语句如下:
SELECT AVG(current), MAX(current), APERCENTILE(current, 50) FROM meters
WHERE ts>=NOW-1d and ts<=now
INTERVAL(10m)
FILL(PREV);写在最后
除了数据量大、结构相对简单的特点外,时序数据在查询场景中还大量涉及时间戳的处理,在很多业务场景的采集数据时,都需要按时间戳进行分组与计算,如果按照常规模式将原始数据读入内存,再由应用层程序去处理时间窗口划分的逻辑,就会因读取海量原始时序数据导致磁盘 IO、CPU 及内存开销的严重浪费,还会提升业务层代码复杂度。
但如果我们能够掌握并灵活运用 TDengine 所提供的上述时序数据特色查询功能,结合业务场景选择相应的函数就能将相关计算负荷下沉到数据库层,在提升系统响应性能的同时也减少了系统资源的浪费。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。