【原创】YOLOV4 训练自己的训练集——人头检测
【原创】YOLOV4 训练自己的训练集——人头检测
-
- 数据集准备
- 制作yolov4需要的label以及txt
-
-
- 第一步,删除在“sets”里带2012的,在classes数据写入自己的训练类别“head”
- 第二步,在路径前面添加”data/”
- 第三步,修改convert_annotation()函数
- 第四步,运行.py文件。
-
- 修改配置文件
-
-
- 1) 配置 head.data。
- 2)配置 head.names。
- 3)配置 yolov4-head.cfg
-
- 开始训练
- 测试:
- 修改后python voc_label.py代码:
数据集准备
首先下载人头检测数据集:
在 https://github.com/HCIILAB/SCUT-HEAD-Dataset-Release 中下载 SCUT_HEAD_Part_B 数据集,里面是图片,组织形式已经和yolov4要求的一致,

PartA和PartB任意一份即可,下载后如下图

Annotations是存放标签xml文件
JPEGImage 存放图片
ImageSets 里面txt按行存放着图片名字
如
000001
000002
000003…
在darknet/build/darknet/x64/data里创建文件夹 VOCdevkit/VOC2007 然后把下载的数据放进去如图:【labels文件夹是下面步骤生成的】


制作yolov4需要的label以及txt
这个时候只用xml格式是不满足yolov4训练格式的,需要转成voc的标签,而这个代码也有给出。首先我的darknet是下载在D:/VSLib/darknet/中,如图:

打开路径下 darknet/build/darknet/x64/data/voc/voc_label.py,修改voc_label.py里面的内容。
第一步,删除在“sets”里带2012的,在classes数据写入自己的训练类别“head”

第二步,在路径前面添加”data/”


第三步,修改convert_annotation()函数
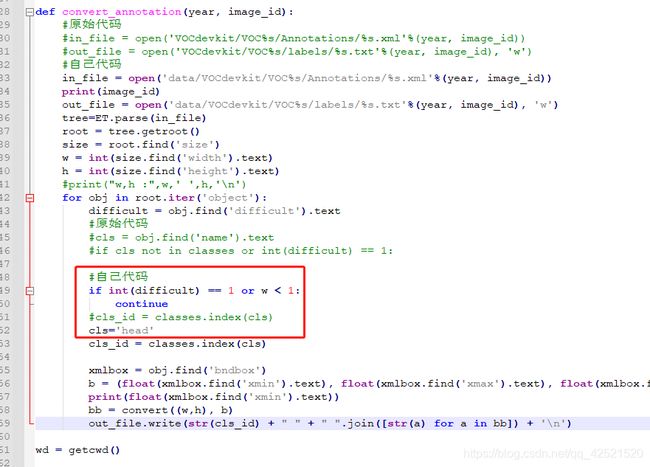
由于对图片中的人头做标记时的xml文件中给的标记”name”是person,而不是人头”head”,与我们自定义的classes不一致,因此在原始代码“if cls not in classes or int(difficult) == 1:”这句判断中,由于”person” 不等于 “head”会让循环 continue即跳过,也就是不会把xml的信息写入到txt中,这会导致转换失败。
因此我修改的思路是,由于训练集里面的人头给的name都是person,第一个思路就是代码不变,把xml文件中 “person“全部改为“head“。第二个思路就是,xml数据不变,在代码去掉这个名称的判断,“cls”变量直接赋为“head”。我采用的是第二个办法。
第二个问题就是代码运行时出现错误“ZeroDivisionError”,我输出每张照片的id后发现,在 PartB_00000.xml中确实有一张size是0。因此我的修改思路是增加一个判断,width大于0的(即有值的)才继续下一步,否则均一化的时候会出错。


代码更改如下图
第四步,运行.py文件。
把修改后的voc_label.py文件复制,放到D:\darknet根目录下而不是build文件夹,否则文件会生成在build/darknet/x64/data下面。然后cmd,输入
python voc_label.py
即可

执行完会在data文件夹下生成几个txt,data/VOCdevkit/VOC2007/下面会生成一个label文件夹。检查一下.txt文件是否有数据即成功生成,如果是0kb则要检查代码。

修改配置文件
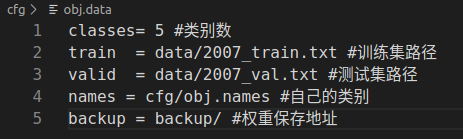
1) 配置 head.data。
D:/VSLib/darknet/cfg/目录下复制coco.data,并且重命名为head.data。然后使用修改下面以下内容。注意backup路径那里不要写成 “backup/”,会报路径错误,另外backup文件夹自己在D:/VSLib/darknet下新建出来先。


【注意在配置文件中不要写注释,并不是python文件,路径使用 “/”。变量含义可以参考下图。】
2)配置 head.names。
D:/VSLib/darknet/cfg/目录下复制coco.names,并且重命名为head.names。改成自己类别的名称,就写一行“head”。

3)配置 yolov4-head.cfg
复制cfg/yolov4-custom.cfg,并且重命名为yolov4-head.cfg,同时修改一下内容。Batch初始是64,可以先不改,我运行的时候会报错memory不足,所以修改小一些到16,网上说要4的倍数。
修改width和height为416,修改最大batch迭代多少个数max_batches = 6000,修改steps多久学习率下降一次,一般设置为max_batch个数的80%和90%。

另外修改三个classes的地方,修改为1。

还有三个filters=255的地方要修改成自己的【注意不是所有filters都该,只改三个等于255的】,公式是(类别数+5)*3,我只有一个类别,所以等于18。

开始训练
1)首先要下载预训练模型,yolov4.conv.137,放到D:/VSLib/darknet文件下,下载链接:
https://pan.baidu.com/s/1XrcPHdp2_4c-dKge2Guw4w
提取码:xsxb
2)在D:/VSLib/darknet文件下,打开cmd,执行代码
darknet detector train cfg/head.data cfg/yolov4-head.cfg yolov4.conv.137
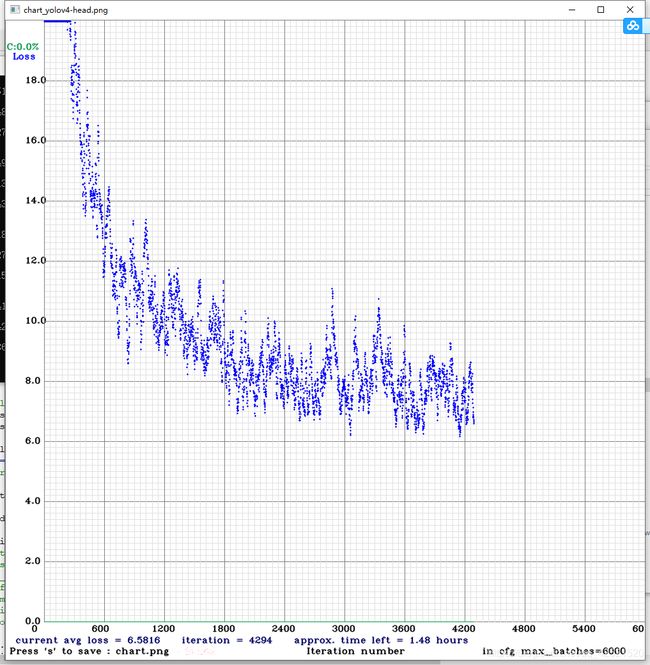
开始训练,会弹出一个实时显示loss的框,我训练了5个小时+,最后的权重文件会保存在backup文件夹中,我使用的是 “yolov4-head_last.weights”

测试:
darknet detector test cfg/head.data cfg/yolov4-head.cfg backup/yolov4-head_last.weights

在命令行输入你的图片,比如

D:\VSLib\darknet\data\VOCdevkit\VOC2007\JPEGImages\PartB_00000.jpg

检测耗时:36ms,非常快速且准确率高!
修改后python voc_label.py代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#原始代码:
#sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
#自己代码:
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["head"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
#原始代码
#in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
#out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
#自己代码
in_file = open('data/VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
print(image_id)
out_file = open('data/VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
#print("w,h :",w,' ',h,'\n')
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#原始代码
#cls = obj.find('name').text
#if cls not in classes or int(difficult) == 1:
#自己代码
if int(difficult) == 1 or w < 1:
continue
#cls_id = classes.index(cls)
cls='head'
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
print(float(xmlbox.find('xmin').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
#if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
# os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
#image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
#list_file = open('%s_%s.txt'%(year, image_set), 'w')
#for image_id in image_ids:
# list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
# convert_annotation(year, image_id)
if not os.path.exists('data/VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('data/VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('data/VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('data/%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/data/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
参考博主:
[1]: https://blog.csdn.net/weixin_44771532/article/details/105495755
[2]: https://github.com/HCIILAB/SCUT-HEAD-Dataset-Release