【无标题】HITCS-程序人生
计算机系统
大作业
题 目 程序人生-Hello’s P2P
专 业 计算学部
学 号 7203610208
班 级 2036011
学 生 李隽
指 导 教 师 刘宏伟
计算机科学与技术学院
2022年5月
摘 要
本文介绍了hello的整个生命过程。利用gcc,gdb,edb,readelf,HexEdit等工具具体分析了hello从源程序开始,历经预处理、编译、汇编、链接的一系列步骤变为可执行文件的过程,即P2P的过程。同时还具体分析了hello在运行过程中涉及的进程管理、内存管理、IO管理到最后hello被回收,即020的过程。通过对hello这个简单程序的详细分析,我们能够更加深入地理解计算机系统。
关键词:Hello’s P2P;进程管理;内存管理;I/O管理
(摘要0分,缺失-1分,根据内容精彩称都酌情加分0-1分)
目 录
第1章 概述 - 4 -
1.1 Hello简介 - 4 -
1.2 环境与工具 - 4 -
1.3 中间结果 - 4 -
1.4 本章小结 - 5 -
第2章 预处理 - 6 -
2.1 预处理的概念与作用 - 6 -
2.2在Ubuntu下预处理的命令 - 6 -
2.3 Hello的预处理结果解析 - 7 -
2.4 本章小结 - 7 -
第3章 编译 - 8 -
3.1 编译的概念与作用 - 8 -
3.2 在Ubuntu下编译的命令 - 8 -
3.3 Hello的编译结果解析 - 9 -
3.4 本章小结 - 11 -
第4章 汇编 - 12 -
4.1 汇编的概念与作用 - 12 -
4.2 在Ubuntu下汇编的命令 - 13 -
4.3 可重定位目标elf格式 - 13 -
4.4 Hello.o的结果解析 - 15 -
4.5 本章小结 - 15 -
第5章 链接 - 16 -
5.1 链接的概念与作用 - 16 -
5.2 在Ubuntu下链接的命令 - 16 -
5.3 可执行目标文件hello的格式 - 17 -
5.4 hello的虚拟地址空间 - 18 -
5.5 链接的重定位过程分析 - 19 -
5.6 hello的执行流程 - 21 -
5.7 Hello的动态链接分析 - 21 -
5.8 本章小结 - 22 -
第6章 hello进程管理 - 23 -
6.1 进程的概念与作用 - 23 -
6.2 简述壳Shell-bash的作用与处理流程 - 23 -
6.3 Hello的fork进程创建过程 - 24 -
6.4 Hello的execve过程 - 24 -
6.5 Hello的进程执行 - 25 -
6.6 hello的异常与信号处理 - 26 -
6.7本章小结 - 28 -
第7章 hello的存储管理 - 29 -
7.1 hello的存储器地址空间 - 29 -
7.2 Intel逻辑地址到线性地址的变换-段式管理 - 30 -
7.3 Hello的线性地址到物理地址的变换-页式管理 - 31 -
7.4 TLB与四级页表支持下的VA到PA的变换 - 33 -
7.5 三级Cache支持下的物理内存访问 - 33 -
7.6 hello进程fork时的内存映射 - 34 -
7.7 hello进程execve时的内存映射 - 34 -
7.8 缺页故障与缺页中断处理 - 35 -
7.9动态存储分配管理 - 35 -
7.10本章小结 - 38 -
第8章 hello的IO管理 - 39 -
8.1 Linux的IO设备管理方法 - 39 -
8.2 简述Unix IO接口及其函数 - 39 -
8.3 printf的实现分析 - 39 -
8.4 getchar的实现分析 - 40 -
8.5本章小结 - 40 -
结论 - 40 -
附件 - 42 -
参考文献 - 43 -
第1章 概述
1.1 Hello简介
根据Hello的自白,利用计算机系统的术语,简述Hello的P2P,020的整个过程。
P2P(From Program to Process):
hello.c是C语言文本文件,经过预处理,进行宏替换,生成文本文件hello.i,经过编译器生成汇编程序hello.s,然后经过汇编器生成二进制可重定位文件hello.o,接着经过链接器生成二进制可执行文件hello。在shell中输入启动命令后,shell为其fork,产生一个子进程,于是hello便从Program变成了Process。
020(From Zero-0 to Zero-0):
shell调用execve函数在新的子进程中加载并运行hello,加载器创建一组新的代码、数据、堆和栈段。新的栈和堆段被初始化为零。将虚拟内存中的页映射到可执行文件的页大小的片(chunk),代码被初始化为可执行文件的内容。加载器跳转到_start地址,调用应用程序的main函数。程序运行结束后,shell回收进程,内核删除相关数据结构。进程从0开始,最后回到0。
1.2 环境与工具
列出你为编写本论文,折腾Hello的整个过程中,使用的软硬件环境,以及开发与调试工具。
硬件环境:Intel® Core™ i5-10300H CPU;2.50GHz;8G RAM;1T SSD
软件环境:Windows10 64位;Vmware 15.5 PRO;Ubuntu 20.04 LTS 64位
开发与调试工具:gcc,vim,edb,readelf,HexEdit
1.3 中间结果
列出你为编写本论文,生成的中间结果文件的名字,文件的作用等。
hello.c——原文件
hello.i——预处理之后文本文件
hello.s——编译之后的汇编文件
hello.o——汇编之后的可重定位目标执行
hello——链接之后的可执行目标文件
1.4 本章小结
本章主要简单介绍了hello的P2P,020过程,列出了本次实验的环境、中间文件。
(第1章0.5分)
第2章 预处理
2.1 预处理的概念与作用
概念:程序设计领域中,预处理一般是指在程序源代码被翻译为目标代码的过程中,生成二进制代码之前的过程。典型地,由预处理器(preprocessor) 对程序源代码文本进行处理,得到的结果再由编译器核心进一步编译。这个过程并不对程序的源代码进行解析,但它把源代码分割或处理成为特定的单位——(用C/C++的术语来说是)预处理记号(preprocessing token)用来支持语言特性(如C/C++的宏调用)。
作用:1.用实际值替换宏定义的字符串
2.文件包含:将头文件中的代码插入到新程序中
3.条件编译:根据if后面的条件决定需要编译的代码
2.2在Ubuntu下预处理的命令
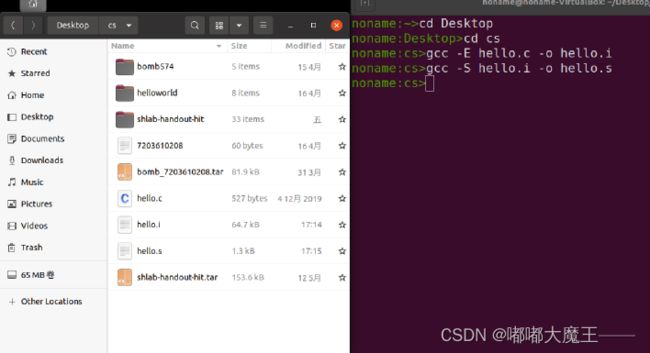
命令:gcc -E hello.c -o hello.i
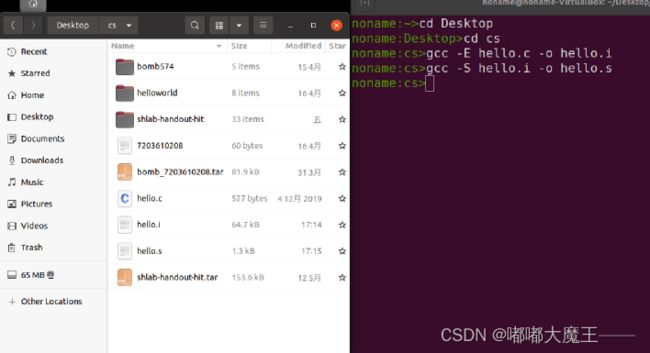
2.3 Hello的预处理结果解析
预处理文件有3060行,main函数在hello.i文件的最后,没有变化。头文件#include
2.4 本章小结
介绍了预处理概念和作用,在Linux下预处理的操作,简要分析了生成的hello.i文件。
(第2章0.5分)
第3章 编译
3.1 编译的概念与作用
概念:编译器(ccl)将hello.i文件转换成汇编文件hello.s,里面是hello.c对应的汇编语言程序。
作用 :编译的过程实质上对预处理文件进行语法分析、语义分析、优化,将其转换为汇编程序,
3.2 在Ubuntu下编译的命令
命令:gcc -S hello.i -o hello.s
3.3 Hello的编译结果解析
3.3.1数据
1.字符串
程序中有两个输出字符串(“用法: Hello 学号 姓名 秒数!\n”和“Hello %s %s\n”),都存在.rodata节,作为printf的参数。

2.数组
传参量int argc,char *argv[],可以看出argv首地址在栈中的位置为-32(%rbp),被多次调用传给printf。
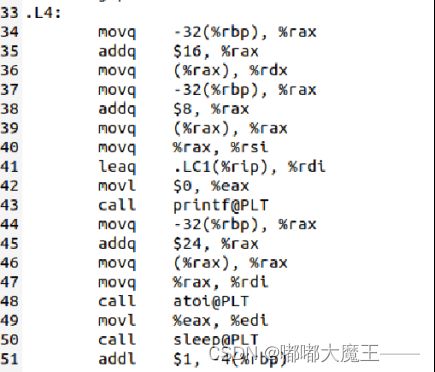
3.局部变量

3.3.2全局函数main

3.3.3数据类型转换
atoi把三个字符串转化为整数.
3.3.4算术操作
i++(自增运算)
![]()
3.3.5关系操作
有判断arge!=4和判断i<8两个

判断arge是否等于4,如果成立转移到L2
![]()
判断i是否小于8,如果不成立转移到L4
![]()
3.3.6函数操作
含有main,exit,printf,atoi,sleep,getchar函数。
1.main函数
mian函数有两个参数,分别是argc和argv[],分别被保存在%rdi和%rsi中。
2.exit函数
判断用户是否输入4个参数,如果不是四个,直接调用exit结束程序。
![]()
3.printf函数
传递参数:
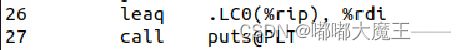
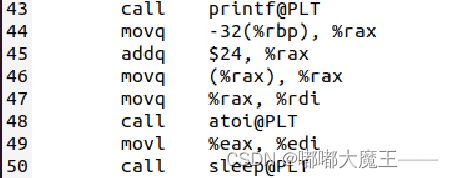
4.atoi函数
把输入的第四个字符串改为整型。并作为参数保存在%rdi中并传入。
5.sleep函数
参数是储存在%eax中的atoi的返回值。
6.getchar函数
没有参数
3.4 本章小结
本章介绍了编译的概念及作用,对hello.c文件进行编译操作,并结合hello.s汇编代码阐述了编译器是如何处理C语言的数据类型、运算操作及函数的。
(第3章2分)
第4章 汇编
4.1 汇编的概念与作用
概念:汇编器(as)将汇编文件(.s)转换为二进制可重定位文件的过程。
作用:
1.汇编语言的大部分语句直接对应机器指令,执行速度快,效率高,代码体积小,在某些存储器容量有限,但需要快速和实时响应的场合比较有用。
2.在系统程序的核心部分,以及与系统硬件频繁打交道的部分,可以使用汇编语言。如操作系统的核心程序段、外部设备的低层驱动程序,以及频繁调用的子程序、动态连接库、某些高级绘图程序、视频游戏程序等等。
4.汇编语言可以用于软件的加密和解密、计算机病毒的分析和防治,以及程序的调试和错误分析等各个方面。
5.4.通过学习汇编语言,能够加深对计算机原理和操作系统等课程的理解。通过学习和使用汇编语言,能够感知、体会和理解机器的逻辑功能,向上为理解各种软件系统的原理,打下技术理论基础;向下为掌握硬件系统的原理,打下实践应用基础。
注意:这儿的汇编是指从 .s 到 .o 即编译后的文件到生成机器语言二进制程序的过程。
4.2 在Ubuntu下汇编的命令
命令:as hello.s -o hello.o
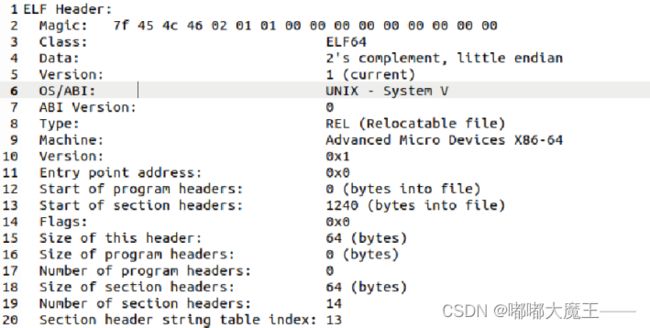
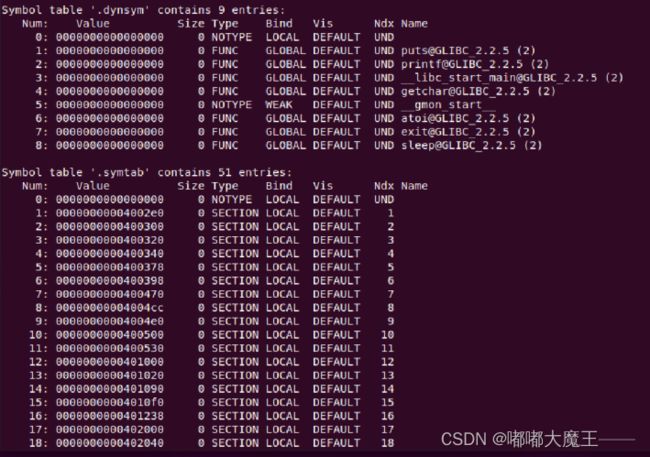
4.3 可重定位目标elf格式
1.ELF头
ELF头由16字节的Magic序列开始,描述了生成该文件的系统的字的大小和字节顺序。ELF头剩下的部分包含帮助连接器语法分析和解释目标文件的信息。其中包括ELF头的大小、目标文件类型、机器类型、字节头部表的文件偏移,以及节头部表中条目的大小和数量等信息。
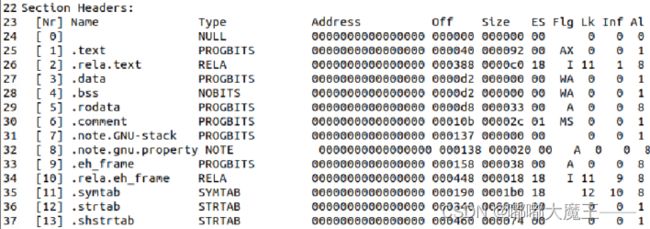
2.节头部表
节头部表包含了文件中出现的各个节的含义,包括各节名称、类型、地址、偏移量、大小、全体大小、旗标、连接、信息、对齐信息。
3…rela.text节
一个.text节中位置的列表,包含.text节中需要进行重定位的信息,当链接器把这个目标文件和其他文件组合时,需要修改这些位置。调用本地函数的指令则不需要修改。

4…symtab节
符号表.symtab包含了程序中的函数、全局变量的名称、类型、大小、vis等信息。
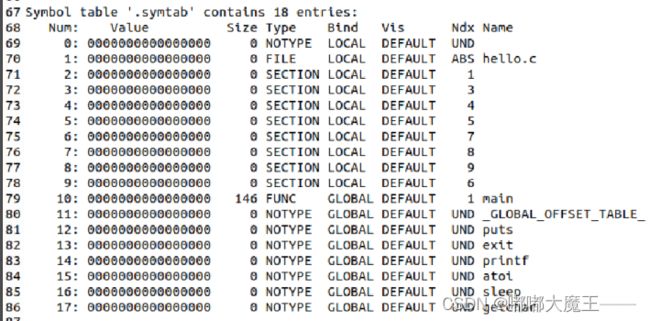
4.4 Hello.o的结果解析
反汇编指令:objdump -d -r hello.o > hello1.txt
1.分支转移:反汇编得到的代码中,跳转指令的操作数使用的不再是如hello.s中的.L2、.L3之类的代码段名称,而是具体的地址,因为这类名称只是在编写hello.s时为了便于编写所使用的一些符号,这些符号在汇编成机器语言之后不再存在,变成了语句地址,所以跳转指令的操作数也随之发生了变化。
2.函数调用:在hello.s中,调用函数的形式是call指令加调用的函数名,而在反汇编文件中是call加下一条指令的地址。由于hello.c所调用的函数都是函数共享库中的函数,所以在调用这类函数时会产生重定位条目,这些条目在动态链接时会被修改为运行时的执行地址,而在汇编成的机器语言中,对于这些函数调用的相对地址全部被设置成0,所以call后面加的是下一条指令,而它的重定位信息则会被添加到.rela.text节,等链接后再确定。
3.访问字符串常量:在hello.s中,使用.L0(%rip)的形式访问,而在反汇编文件中使用0x0(%rip)的方式访问。因为.rodata节中的地址也是没有确定的,在运行的时才会确定,所以需要重定位,同函数调用的处理方式一样,也是将其设置为0,并把重定位信息则会被添加到.rela.text节,等链接后再确定。
4.5 本章小结
本章介绍了从.s到.o的过程。通过汇编文件和elf格式与.s比较了解机器语言和汇编语言的映射关系。
(第4章1分)
第5章 链接
5.1 链接的概念与作用
概念:链接是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载到内存并执行。链接可以执行于编译时,也将就是在源代码被翻译成机器代码时;也可以执行于加载时,也就是在程序被加载器加载到内存并执行时;甚至执行于运行时,也就是有应用程序来执行。
作用:链接可以执行于编译时,也就是在源代码被编译成机器代码时;也可以执行于加载时,也就是在程序被加载器加载到内存并执行时;甚至于运行时,也就是由应用程序来执行。链接是由叫做链接器的程序执行的。链接器使得分离编译成为可能。
注意:这儿的链接是指从 hello.o 到hello生成过程。
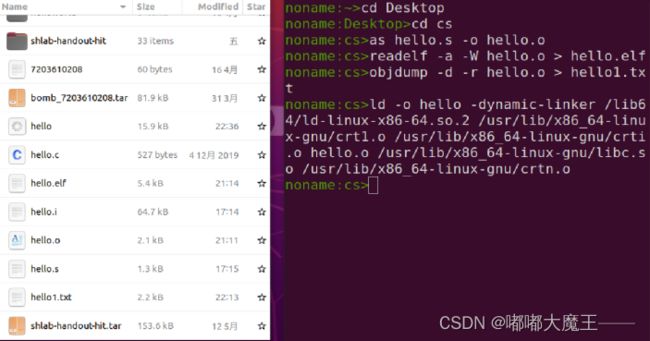
5.2 在Ubuntu下链接的命令
命令:
ld -o hello -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o hello.o /usr/lib/x86_64-linux-gnu/libc.so /usr/lib/x86_64-linux-gnu/crtn.o
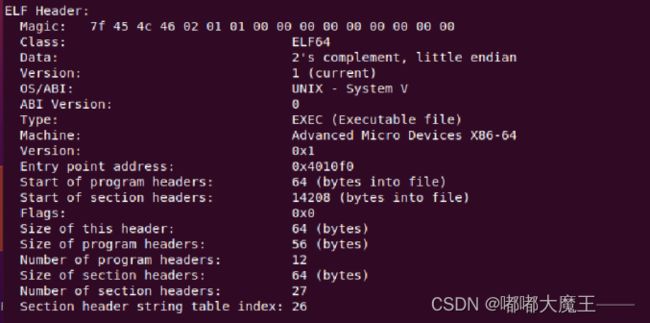
5.3 可执行目标文件hello的格式
1.ELF表头:
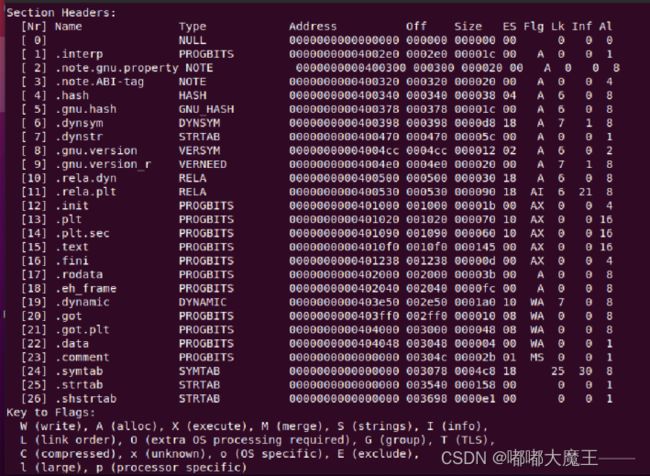
2.节头表:记录了各个节的信息,Address是程序被载入到虚拟地址的起始地址,off是在程序中的偏移量,size是节的大小。
3.符号表:存放了程序中引用的函数和全局变量信息。
5.4 hello的虚拟地址空间
使用edb加载hello,查看本进程的虚拟地址空间各段信息,并与5.3对照分析说明。


ELF表头从0x00400000到0x00400ff0
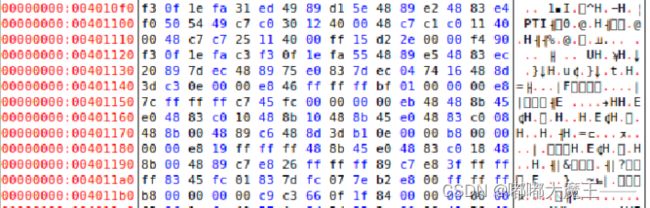
.text段

.rodata段
5.5 链接的重定位过程分析
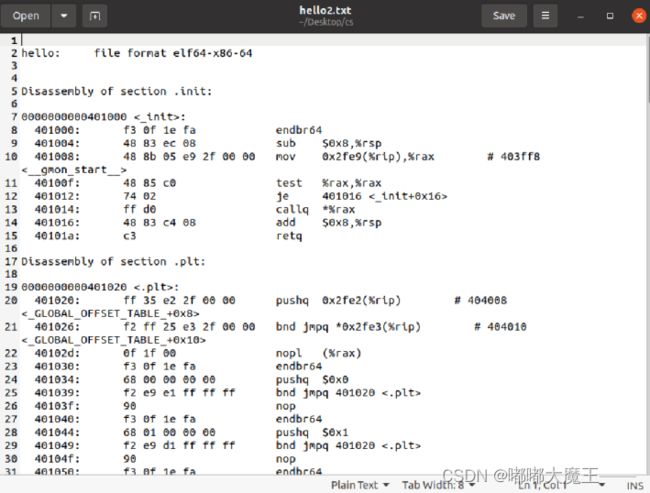
生成反汇编文件hello.txt
1.重定位节和符号定义链接器将所有类型相同的节合并在一起后,这个节就作为可执行目标文件的节。然后链接器把运行时的内存地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号,当这一步完成时,程序中每条指令和全局变量都有唯一运行时的地址。
2.重定位节中的符号引用这一步中,连接器修改代码节和数据节中对每个符号的引用,使他们指向正确的运行时地址。执行这一步,链接器依赖于可重定位目标模块中称为的重定位条目的数据结构。
3.重定位条目当编译器遇到对最终位置未知的目标引用时,它就会生成一个重定位条目。代码的重定位条目放在.rela.txt
重定位算法:
foreach section s{
foreach relocation entry r{
refptr = s + r.offset;/ptr to reference to be relocated/
/Relocate a PC-relative reference/
if(r.type == R_X86_64_PC32){//PC相对寻址的引用
refaddr = ADDR(s) + r.offset;/ref’s run-time address/
*refptr = (unsigned) (ADDR(r.symbol) + r.addend - refaddr);
}
/Relocate an absolute reference/
if( r.type == R_X86_64_32)//使用32位绝对地址
*refptr = (unsigned)(ADDR(r.symbol) + r.addend);
}
}
5.6 hello的执行流程
子程序名:
ld-2.27.so!_dl_start
ld-2.27.so!_dl_init
hello!_start
libc-2.27.so!__libc_start_main
libc-2.27.so!__cxa_atexit
libc-2.27.so!__libc_csu_init
libc-2.27.so!_setjmp
hello!main
hello!puts@plt
hello!exit@plt
hello!printf@plt
hello!sleep@plt
hello!getchar@plt
ld-2.27.so!_dl_runtime_resolve_xsave
ld-2.27.so!_dl_fixup
ld-2.27.so!_dl_lookup_symbol_x
libc-2.27.so!exit
使用edb执行hello,说明从加载hello到_start,到call main,以及程序终止的所有过程。请列出其调用与跳转的各个子程序名或程序地址。
5.7 Hello的动态链接分析
在程序中动态链接是通过延迟绑定来实现的,延迟绑定的实现依赖全局偏移量表GOT和过程连接表PLT实现。GOT是数据段的一部分,PLT是代码段的一部分。
PLT数组中每个条目时16字节,PTL[0]是一个特殊的条目,可以跳转到动态链接器中。每个可被执行程序调用的库函数都有自己的PLT条目。PLT[1]调用__libc_start_main函数负责初始化。
GOT数组中每个条目八个字节。GOT[0]和GOT[1]中包含动态链接器解析地址时会用的信息,GOT[2]时动态练级去在ld-linux.so模块的入口点。其余的每一个条目对应一个被调用的函数。

根据上图可以看到hello里,GOT表的初始位置为0x00403ff0

由上图可以看到程序还未启动时,GOT表的内容

点击启动后,GOT表发生了改变。
5.8 本章小结
本章介绍了链接的概念和作用,对链接后生成的可执行文件hello的elf格式文件进行了分析,分析了hello的虚拟地址空间、重定位过程、执行过程的各种处理操作。
(第5章1分)
第6章 hello进程管理
6.1 进程的概念与作用
进程的概念:一个执行中的程序的实例,同时也是系统进行资源分配和调度的基本单位。一般情况下,包括文本区域、数据区域和堆栈。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。
进程的作用:提供一个假象,好像我们的程序独占地使用内存系统,处理器好像是无间断的执行我们程序中的指令,我们程序中的代码和数据好像是系统内存中唯一的对象。
6.2 简述壳Shell-bash的作用与处理流程
shell-bash的作用:shell-bash是一个C语言程序,它代表用户执行进程,它交互性地解释和执行用户输入的命令,能够通过调用系统级的函数或功能执行程序、建立文件、进行并行操作等。同时它也能够协调程序间的运行冲突,保证程序能够以并行形式高效执行。bash还提供了一个图形化界面,提升交互的速度。
shell-bash的处理流程:
1.终端进程读取用户由键盘输入的命令行。
2.分析命令行字符串,获取命令行参数,并构造传递给execve的argv向量
3.检查第一个命令行参数是否是一个内置的shell命令
4.如果不是内部命令,调用fork()创建新进程/子进程
5.在子进程中,用步骤2获取的参数,调用execve()执行指定程序。
6.如果用户没要求后台运行(命令末尾没有&号)否则shell使用waitpid等待作业终止后返回。
7.如果用户要求后台运行(如果命令末尾有&号),则shell返回;
6.3 Hello的fork进程创建过程
终端程序通过调用fork()函数创建一个子进程,子进程得到与父进程完全相同但是独立的一个副本,包括代码段、段、数据段、共享库以及用户栈。子进程还获得与父进程任何打开文件描述符相同的副本,这就意味着,当父进程调用fork时,子进程可以读写父进程中打开的任何文件。父进程与子进程之间的区别在于它们拥有不同的PID。
以hello为例,当输入 ./hello 7203610208 李隽 1 的时候,首先shell对输入的命令进行解析,由于输入的命令不是一个内置的shell命令,因此shell会调用fork()创建一个新的子进程。
6.4 Hello的execve过程
在fork之后,子进程调用execve函数,execve函数在新创建的子进程的上下文中加载并运行hello程序。execve函数加载并运行可执行目标文件filename,且带参数列表argv和环境变量列表envp。只有发生错误时execve才会返回到调用程序。所以,execve调用一次且从不返回。
加载并运行hello需要以下几个步骤:
(1)删除已存在的用户区域。删除当前进程虚拟地址的用户部分中已存在的区域结构。
(2)映射私有区域。为新程序的代码、数据、bss和栈区域创建新的区域结构。所有这些新的区域都是私有的、写时复制的。代码和数据区被映射为hello文件中的.text和.data区。bss区域是请求二进制零的,映射到匿名文件,其大小包含在hello中。栈和堆区域也是请求二进制零的,初始长度为零。
(3)映射共享区域。如果hello程序与共享对象链接,那么这些对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。
(4)设置程序计数器。设置当前进程上下文中的程序计数器,使之指向代码区域的入口点。下一次调度这个进程时,它将从这个入口点开始执行。
6.5 Hello的进程执行
上下文信息:
上下文就是内核重新启动一个被抢占的进程所需要的状态,它由通用寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈和各种内 核数据结构等对象的值构成。
上下文切换:
当内核选择一个新的进程运行时,则内核调度了这个进程。在内核调度了一个新的进程运行后,它就抢占当前进程,并使用一种称为上下文切换的机制来将控制转移到新的进程:1.保存以前进程的上下文;
2.恢复新恢复进程被保存的上下文;
3.将控制传递给这 个新恢复的进程 ,来完成上下文切换。
进程时间片:
一个进程执行它的控制流的一部分的每一时间段叫做时间片。
逻辑控制流:
一系列程序计数器 PC 的值的序列叫做逻辑控制流。由于进程是轮流使用处理器的,同一个处理器每个进程执行它的流的一部分后被抢占,然后轮到其他进程。
用户模式和内核模式:
处理器通常是用某个控制寄存器中的一个模式位提供两种模式的区分功能,该寄存器描述了进程当前享有的特权。
1.当设置模式位时,进程处于内核模式,该进程可以执行指令集中的任何命令,并且可以访问系统中的任何内存位置;
2.当没有设置模式位时,进程就处于用户模式中,用户模式的进程不允许执行特权指令,也不允许直接引用地址空间中内核区内的代码和数据。
6.6 hello的异常与信号处理
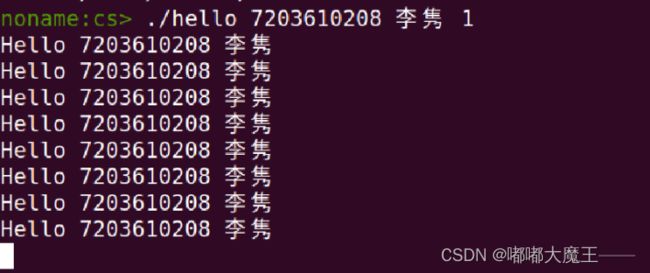
Ctrl-c

Ctrl-Z
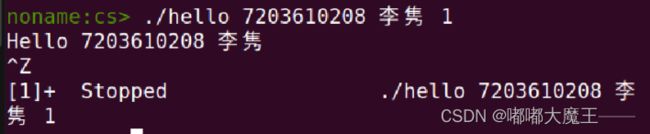
Ctrl-Z + ps
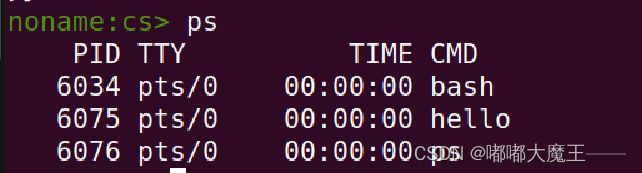
Ctrl-Z + jobs

Ctrl-Z 和 pstree

Ctrl-z +kill
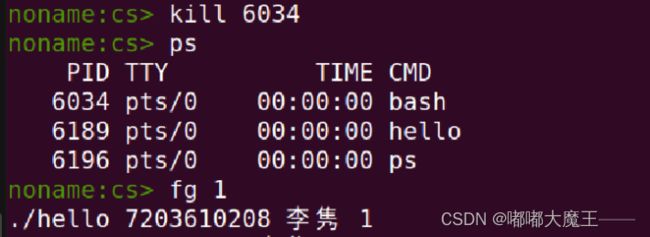
随便按
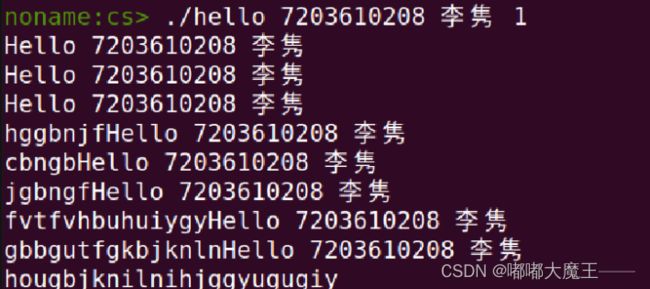
6.7本章小结
本章主要介绍了进程的概念与作用,阐述了shell的作用和处理流程以及hello的fork进程的创建过程和execve的过程,最后分析了hello的执行过程和过程中出现的异常的处理。
(第6章1分)
第7章 hello的存储管理
7.1 hello的存储器地址空间
逻辑地址(Logical Address) 是指由程序产生的与段相关的偏移地址部分。例如,在进行C语言指针编程中,可以读取指针变量本身值(&操作),实际上这个值就是逻辑地址,它是相对于当前进程数据段的地址,不和绝对物理地址相干。只有在Intel实模式下,逻辑地址才和物理地址相等(因为实模式没有分段或分页机制,CPU不进行自动地址转换);逻辑也就是在Intel 保护模式下程序执行代码段限长内的偏移地址(假定代码段、数据段如果完全一样)。应用程序员仅需与逻辑地址打交道,而分段和分页机制是完全透明的,仅由系统编程人员涉及。应用程序员虽然自己可以直接操作内存,那只能在操作系统给你分配的内存段操作。
线性地址(Linear Address) 是逻辑地址到物理地址变换之间的中间层。程序代码会产生逻辑地址,或者说是段中的偏移地址,加上相应段的基地址就生成了一个线性地址。如果启用了分页机制,那么线性地址可以再经变换以产生一个物理地址。若没有启用分页机制,那么线性地址直接就是物理地址。Intel 80386的线性地址空间容量为4G(2的32次方即32根地址总线寻址)。
物理地址(Physical Address) 是指出现在CPU外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果地址。如果启用了分页机制,那么线性地址会使用页目录和页表中的项变换成物理地址。如果没有启用分页机制,那么线性地址就直接成为物理地址了。
虚拟内存(Virtual Memory) 是指计算机呈现出要比实际拥有的内存大得多的内存量。因此它允许程序员编制并运行比实际系统拥有的内存大得多的程序。这使得许多大型项目也能够在具有有限内存资源的系统上实现。在Linux 0.11内核中,给每个程序(进程)都划分了总容量为64MB的虚拟内存空间。因此程序的逻辑地址范围是0x0000000到0x4000000。
7.2 Intel逻辑地址到线性地址的变换-段式管理
逻辑地址的表示形式为[段标识符:段内偏移量],这个表示形式包含完成逻辑地址到虚拟地址(线性地址)映射的信息。
逻辑地址实际是由48位组成的,前16位是段选择符,后32位是段内偏移量。通过段选择符,我们可以获得段基地址,再与段内偏移量相加,即可获得最终的线性地址。
段标识符又名段选择符,是一个16位的字段,包括一个13位的索引字段,1位的TI字段和2位的RPL字段。
通过段标识符的前13位,可以直接在段描述符表中索引到具体的段描述符。每个段描述符中包含一个Base字段,它描述了一个段的开始位置的线性地址。将Base字段和逻辑地址中的段内偏移量连接起来就得到转换后的线性地址。全局的段描述符,放在全局段描述符表中,每个进程自己的段描述符,放在局部段描述符表中。全局段描述符表存放在gdtr控制寄存器中,而局部段描述符表存放在ldtr寄存器中。
逻辑地址到线性地址的变换过程为:给定逻辑地址,看段选择符的最后一位是0还是1,从而判断选择全局段描述符表还是局部段描述符表。通过段标识符的前13位,得到Base字段,和段内偏移量连接起来最终得到转换后的线性地址。
7.3 Hello的线性地址到物理地址的变换-页式管理
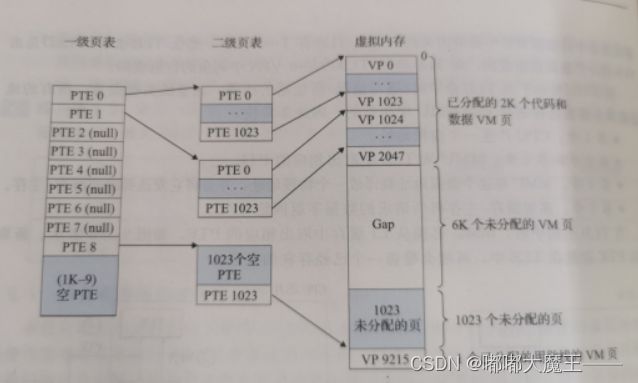
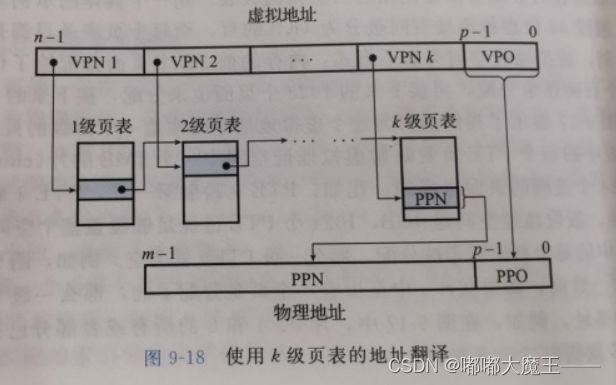
将程序的逻辑地址空间划分为固定大小的页,而物理内存划分为同样大小的页框。程序加载时,可将任意一页放入内存中任意一个页框,这些页框不必连续,从而实现了离散分配。该方法需要CPU的硬件支持,来实现逻辑地址和物理地址之间的映射。在页式存储管理方式中地址结构由两部构成,前一部分是VPN(虚拟页号),后一部分是VPO(虚拟页偏移量)。
在页式系统中进程建立时,操作系统为进程中所有的页分配页框。当进程撤销时收回所有分配给它的页框。在程序的运行期间,如果允许进程动态地申请空间,操作系统还要为进程申请的空间分配物理页框。操作系统为了完成这些功能,必须记录系统内存中实际的页框使用情况。操作系统还要在进程切换时,正确地切换两个不同的进程地址空间到物理内存空间的映射。这就要求操作系统要记录每个进程页表的相关信息。为了完成上述的功能,—个页式系统中,一般要采用如下的数据结构。
页表:页表将虚拟内存映射到物理页。每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。页表是一个页表条目(PTE)的数组。虚拟地址空间的每个页在页表中一个固定偏移量处都有一个PTE。假设每个PTE是由一个有效位和一个n位地址字段组成的。有效位表明了该虚拟页当前是否被缓存在DRAM中。如果设置了有效位,那么地址字段就表示DRAM中相应的物理页的起始位置,这个物理页中缓存了该虚拟页。如果没有设置有效位,那么一个空地址表示这个虚拟页还未被分配。否则,这个地址就指向该虚拟页在磁盘上的起始位置。
MMU利用VPN来选择适当的PTE,将列表条目中PPN和虚拟地址中的VPO串联起来,就得到相应的物理地址。
7.4 TLB与四级页表支持下的VA到PA的变换
7.5 三级Cache支持下的物理内存访问
MMU发送物理地址PA给L1 缓存,L1缓存从物理地址中抽取出缓存偏移CO、 缓存组索引CI以及缓存标记CT。高速缓存根据CI找到缓存中的一组,并通过CT判断是否已经缓存地址对应的数据,若缓存命中,则根据偏移量直接从缓存中读取数据并返回;若缓存不命中,则继续从L2、L3缓存中查询,若仍未命中,则从主存中读取数据。
7.6 hello进程fork时的内存映射
当fork函数被shell调用时,内核为hello进程创建各种数据结构,并分配给它一个唯一的PID。为了给hello进程创建虚拟内存,它创建了hello进程的mm_struct、区域结构和页表的原样副本。它将两个进程中的每个页面都标记为只读,并将两个进程中的每个区域结构都标记为私有的写时复制。
当fork在hello进程中返回时,hello进程现在的虚拟内存刚好和调用fork时存在的虚拟内存相同。当这两个进程中的一个在后来进行写操作时,写时复制机制就会创建新页面,因此,也就为每个进程保持了私有地址空间的抽象概念。
7.7 hello进程execve时的内存映射
exceve()函数在当前进程的上下文中加载并运行我们需要的hello程序。execve函数加载并运行可执行文件filename,且带参数列表argv和环境变量envp。只有当出现错误时,例如找不到filename,execve才会返回到调用程序。
execve函数用hello程序有效替代当前程序,需要以下几个步骤:
(1)删除已存在的用户区域。删除当前进程虚拟地址的用户部分中的已存在的区域结构。
(2)映射私有区域。为新程序(即hello)的代码、数据、bss和栈区域等创建新的区域结构。所有这些区域都是私有的、写时复制的。代码和数据区域被映射为hello文件中的.text和.data区。bss区域是请求二进制零的,映射到匿名文件,其大小包含在hello中。栈和堆区域也是请求二进制零的,初始长度为零。
(3)映射共享区域。如果hello程序与共享对象(或目标)链接,那么这些对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。
(4)设置程序计数器。最后设置当前进程上下文中的程序计数器,使之指向代码区域的入口点。
当内核调度这个进程时,它就将从这个入口点开始执行。Linux根据需要换入代码和数据页面。
7.8 缺页故障与缺页中断处理
缺页故障是一种常见的故障,当指令引用一个虚拟地址,在MMU中查找页表时发现与该地址相对应的物理地址不在内存中,因此必须从磁盘中取出的时候就会发生故障。其处理流程遵循图7.12所示的故障处理流程。
缺页中断处理:缺页处理程序是系统内核中的代码,选择一个牺牲页面,如果这个牺牲页面被修改过,那么就将它交换出去,换入新的页面并更新页表。当缺页处理程序返回时,CPU重新启动引起缺页的指令,这条指令再次发送VA到MMU,这次MMU就能正常翻译VA了。
7.9动态存储分配管理
1.动态内存分配器的基本原理
在程序运行时程序员使用动态内存分配器(比如malloc)获得虚拟内存。动态内存分配器维护者一个进程的虚拟内存区域,称为堆。分配器将堆视为一组不同大小的块的集合来维护,每个块要么是已分配的,要么是空闲的。已分配的块显式地保留为供应用程序使用。空闲块可用来分配。空闲块保持空闲,直到它显式地被应用所分配。一个已分配的块保持已分配状态,直到它被释放,这种释放要么是应用程序显式执行的,要么是内存分配器自身隐式执行的。
分配器的类型有两种:显式分配器和隐式分配器。
显式分配器:要求应用显式地释放任何已分配的块。例如,C语言中的malloc函数申请了一块空间之后需要free函数释放这个块
隐式分配器:应用检测到已分配块不再被程序所使用,就释放这个块。比如Java,ML和Lisp等高级语言中的垃圾收集。
2.带边界标签的隐式空闲链表分配器原理
带边界标签的隐式空闲链表的堆块结构如图7.13。一个块是由一个字的头部、有效载荷、可能的一些额外的填充,以及在块的结尾处的一个字的脚部组成的。头部编码了这个块的大小(包括头部和所有的填充),以及这个块是已分配的还是空闲的。如果我们强加一个双字的对齐约束条件,那么块大小就总是8的倍数,且块大小的最低3位总是0。因此,我们只需要内存大小的29个高位,释放剩余的3位来编码其他信息。在这种情况中,我们用其中的最低位(已分配位)来指明这个块是已分配的还是空闲的。
寻找一个空闲块的方式有三种:
(1)首次适配:从头开始搜索空闲链表,选择第一个合适的空闲块:可以取总块数(包括已分配和空闲块)的线性时间,但是会在靠近链表起始处留下小空闲块的“碎片”。
(2)下一次适配:和首次适配相似,只是从链表中上一次查询结束的地方开始,优点是比首次适应更快:避免重复扫描那些无用块。但是一些研究表明,下一次适配的内存利用率要比首次适配低得多。
(3)最佳适配:查询链表,选择一个最好的空闲块适配,剩余最少空闲空间,优点是可以保证碎片最小——提高内存利用率,但是通常运行速度会慢于首次适配。
3.关于堆块的合并有如图7.14的四种情况。在情况1中,两个邻接的块都是已分配的,因此不可能进行合并。所以当前块的状态只是简单地从已分配变成空闲。在情况2中,当前块与后面的块合并。用当前块和后面块的大小的和来更新当前块的头部和后面块的脚部。在情况3中,前面的块和当前块合并。用两个块大小的和来更新前面块的头部和当前块的脚部。在情况4中,要合并所有的三个块形成一个单独的空闲块,用三个块大小的和来更新前面块的头部和后面块的脚部。在每种情况中,合并都是在常数时间内完成的。
3.显式空间链表的基本原理
显式空间链表的堆块结构如图7.15。将空闲块组织成链表形式的数据结构。堆可以组织成一个双向空闲链表,在每个空闲块中,都包含一个pred(前驱)和succ(后继)指针。
使用双向链表而不是隐式空闲链表,使首次适配的分配时间从块总数的线性时间减少到了空闲块数量的线性时间。不过,释放一个块的时间可以使线性的,也可以是一个常数,这取决于我们选择的空闲链表中块的排序策略。
链表的维护方式有两种:一种方法是用后进先出(LIFO)的顺序维护链表,将新释放的块放置在链表的开始处。使用LIFO的顺序和首次适配的放置策略,分配器会先检查最近使用过的块。在这种情况下,释放一个块可以在常数时间内完成。如果使用了边界标记,那么合并也可以在线性时间内完成。另一种方法是按照地址顺序来维护链表,其中链表中每个块的地址都小于它后继的地址。在这种情况下,释放一个块需要线性时间的搜索来定位合适的前驱。平衡点在于,按照地址排序的首次适配比LIFO排序的首次适配有更高的内存利用率,接近最佳适配的利用率。
一般而言,显示链表的缺点是空闲块必须足够大,以包含所有需要的指针,以及头部和可能的脚部,这就导致了更大的最小块大小,也潜在地提高了内部碎片的程度。
7.10本章小结
本章总结了hello运行过程中有关内存管理的内容。简述了TLB、多级页表支持下的地址翻译、cache支持下的内存访问、缺页的处理、fork+execve过程的内存映射以及动态存储分配的过程。
(第7章 2分)
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
设备的模型化:文件
设备管理:unix io接口
8.2 简述Unix IO接口及其函数
打开文件。一个应用程序通过要求内核打开相应的文件,来宣告它想要访问一个 I/O
设备。内核返回一个小的非负整数,叫做描述符。描述符在后续对此文件的所有操作中标识这个文件,内核记录有关这个打开文件的所有信息。
Shell 创建的每个进程都有三个打开的文件:标准输入,标准输出,标准错误。
改变当前的文件位置:内核保持着每个打开的文件的一个文件位置k。k初始为0。这个文件位置k表示的是从文件开头起始的字节偏移量。
读写文件:
读操作就是从文件复制n>0个字节到内存。
写操作就是从内存中复制n>0个字节到一个文件。
关闭文件:内 核 释 放 文件打开时创建的数据结构,无论一个进程以何种原因终止时,内核都会关闭所有打开的文件,并且释放他们的内存资源。
函数:
int open (cahr *filename, int flags, mode_t mode);
int close (int fd);
ssize_t read (int fd, void *buf, size_t n);
ssize_t write (int fd, const *buf, size_t n);
8.3 printf的实现分析
从vsprintf生成显示信息,到write系统函数,到陷阱-系统调用 int 0x80或syscall等.
字符显示驱动子程序:从ASCII到字模库到显示vram(存储每一个点的RGB颜色信息)。
显示芯片按照刷新频率逐行读取vram,并通过信号线向液晶显示器传输每一个点(RGB分量)。
8.4 getchar的实现分析
异步异常-键盘中断的处理:键盘中断处理子程序。接受按键扫描码转成ascii码,保存到系统的键盘缓冲区。
getchar等调用read系统函数,通过系统调用读取按键ascii码,直到接受到回车键才返回。
8.5本章小结
本章主要探究了Linux的IO设备管理方法、Unix IO接口及其函数,分析了printf函数和getchar函数的实现。
(第8章1分)
结论
hello所经历的过程:
源程序:在文本编辑器或IDE中编写C语言代码,得到最初的hello.c源程序。
预处理:预处理器解析宏定义、文件包含、条件编译等,生成ASCII码的中间文件hello.i。
编译:编译器将C语言代码翻译成汇编指令,生成一个ASCII汇编语言文件hello.s。
汇编:汇编器将汇编指令翻译成机器语言,并生成重定位信息,生成可重定位目标文件hello.o。
链接:链接器进行符号解析、重定位、动态链接等创建一个可执行目标文件hello。此时,hello才真正地可以被执行。
fork创建进程:在shell中运行hello程序时,shell会调用fork函数创建子进程,供之后hello程序的运行。
execve加载程序:子进程中调用execve函数,加载hello程序,进入hello的程序入口点,hello终于要开始运行了。
运行阶段:内核负责调度进程,并对可能产生的异常及信号进行处理。MMU、TLB、多级页表、cache、DRAM内存、动态内存分配器相互协作,共同完成内存的管理。Unix I/O使得程序与文件进行交互。
终止:hello进程运行结束,shell负责回收终止的hello进程,内核删除为hello进程创建的所有数据结构。hello的一生到此结束,没有留下一丝痕迹。
对计算机系统的设计与实现的感悟:
hello从诞生到结束,经历了千辛万苦,在硬件、操作系统、软件的相互协作配合下,终于完美地完成了它的使命。我认识到,一个复杂的系统需要多方面协作配合才能更好地实现功能,同样,对于社会生活也是这样。同时,计算机系统提供的一系列抽象使得实际应用与具体实现相互分离,可以很好地隐藏实现的复杂性,降低了程序员的负担,使得程序更加容易地编写、分析、运行。
(结论0分,缺失 -1分,根据内容酌情加分)
附件
列出所有的中间产物的文件名,并予以说明起作用。
hello.i:C预处理器产生的一个ASCII码的中间文件,用于分析预处理过程。
hello.s:C编译器产生的一个ASCII汇编语言文件,用于分析编译的过程。
hello.o:汇编器产生的可重定位目标程序,用于分析汇编的过程。
hello:链接器产生的可执行目标文件,用于分析链接的过程。
hello.txt:hello.o的反汇编文件,用于分析可重定位目标文件hello.o。
hello1.txt:hello的反汇编文件,用于分析可执行目标文件hello。
hello2.txt:hello.o的ELF格式,用于分析可重定位目标文件hello.o。
hello.elf:hello的ELF格式,用于分析可执行目标文件hello。
(附件0分,缺失 -1分)
参考文献
为完成本次大作业你翻阅的书籍与网站等
[1] 哈工大计算机系统大作业: 程序人生-Hello’s P2P/ hello 的一生_当然小健的博客-CSDN博客
[2] 2021哈工大计算机系统大作业——程序人生-Hello’s P2P_Liuxc12的博客-CSDN博客
[3] [HITICS]大作业——程序人生Hello‘s P2P_桂花鱼_的博客-CSDN博客
[4] [HITICS] 哈工大2019秋CSAPP大作业-程序人生-Hello’s P2P_北言栾生的博客-CSDN博客
[5] 兰德尔 E.布莱恩特. 深入理解计算机系统. 龚奕利 译.
[6] CSDN. 编译器工作流程详解. 2014:04-27.
https://blog.csdn.net/u012491514/article/details/24590467
(参考文献0分,缺失 -1分)