keras深度学习之猫狗分类二(数据增强)
在上一篇博客中,讲述了对猫狗采用二分类方法进行模型训练,最终得到的模型在测试数据上的准确率为79%。在这里我们采用数据增强的方法进一步提高识别率。
数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加(augment)样本。其目标是,模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力。
例如有如下一张图像:

对这个狗的图像进行数据增强,代码如下:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from PIL import Image
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing import image as kimage
'''
进行数据增强
'''
#设置数据增强
'''
rotation_range 是角度值(在 0~180 范围内),表示图像随机旋转的角度范围。
width_shift 和 height_shift 是图像在水平或垂直方向上平移的范围(相对于总宽
度或总高度的比例)。
shear_range 是随机错切变换的角度。
zoom_range 是图像随机缩放的范围。
horizontal_flip 是随机将一半图像水平翻转。如果没有水平不对称的假设(比如真
实世界的图像),这种做法是有意义的。
fill_mode是用于填充新创建像素的方法,这些新像素可能来自于旋转或宽度/高度平移。
'''
datagen=ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
img=kimage.load_img(path='./dataset/training_set/dogs/dog.2.jpg',target_size=(150,150))
img.show()
#形状变为(150,150,3)
x=kimage.img_to_array(img)
#形状变为(1,150,150,3)
x=x.reshape((1,)+x.shape)
i=0
for batch in datagen.flow(x,batch_size=1):
plt.figure(i)
imgplot = plt.imshow(kimage.array_to_img(batch[0]))
i+=1
if i%4==0:
break
plt.show()
数据增强后的图像如下所示:

可以看到,数据增强后生成的几张图片和原始图像均不一样,采用数据增强的方法相当于能够变向增加样本,但数据增强的使用场景还是用于图像分类中比较适合,用于其它的场景,例如字符识别,就不应该采用数据增强了。
采用数据增强的训练代码如下:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from PIL import Image
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import optimizers
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing import image as kimage
'''
ImageDataGenerator可完成读取图像数据
读取图像文件
将jpeg图像解码为RGB像素网络
将这些像素转换到为浮点型张量并缩放到0~1之间
'''
#训练样本的目录
train_dir='./dataset/training_set/'
#验证样本的目录
validation_dir='./dataset/validation_set/'
#测试样本目录
test_dir='./dataset/test_set/'
#训练样本生成器
#注意数据增强只能用于训练数据,不能用于验证数据和测试数据
'''
进行数据增强
'''
#设置数据增强
'''
rotation_range 是角度值(在 0~180 范围内),表示图像随机旋转的角度范围。
width_shift 和 height_shift 是图像在水平或垂直方向上平移的范围(相对于总宽
度或总高度的比例)。
shear_range 是随机错切变换的角度。
zoom_range 是图像随机缩放的范围。
horizontal_flip 是随机将一半图像水平翻转。如果没有水平不对称的假设(比如真
实世界的图像),这种做法是有意义的。
fill_mode是用于填充新创建像素的方法,这些新像素可能来自于旋转或宽度/高度平移。
'''
train_datagen=ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
train_generator=train_datagen.flow_from_directory(
directory=train_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
#验证样本生成器
validation_datagen=ImageDataGenerator(rescale=1./255)
validation_generator=train_datagen.flow_from_directory(
directory=validation_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
#测试样本生成器
test_datagen=ImageDataGenerator(rescale=1./255)
test_generator=train_datagen.flow_from_directory(
directory=test_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
if __name__=='__main__':
data,lables=next(train_generator)
print(data.shape)#(20, 128, 128, 3)
print(lables.shape)#(20,)
#查看其中一张图像以及其标签
img_test=Image.fromarray((255*data[0]).astype('uint8'))
# img_test.show()
# print(lables[0])
#构建训练网络
model=models.Sequential()
model.add(layers.Conv2D(filters=32,kernel_size=(3,3),activation='relu',input_shape=(150,150,3)))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Flatten())
#添加一个dropout层可进一步提高识别率
model.add(layers.Dropout(rate=0.5))
model.add(layers.Dense(units=512,activation='relu'))
model.add(layers.Dense(units=1,activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
model.summary()
#拟合模型
history=model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50
)
#测试测试集的准确率
test_eval=model.evaluate_generator(test_generator)
print(test_eval)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
训练的准确率变化如图所示:

训练的损失函数变化如下:
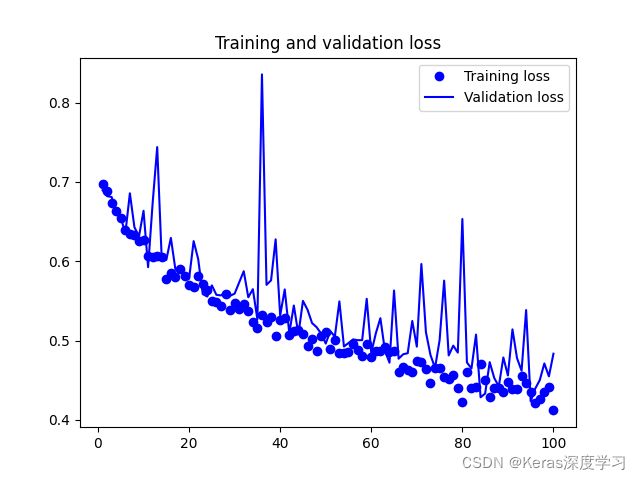
从图像上看到,增大训练次数,并没有发生过拟合,当我们把训练批次设置成200时,在测试集上的准确率可以达到85%。