![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第1张图片](http://img.e-com-net.com/image/info8/9c71f7ae1f1f4e82b1e362f8e9aba2cd.jpg)
今天分享一篇华为在连续特征处理方面的工作,提出了一种高模型容量、端到端训练、每个特征值具有单独embedding的框架,称作AutoDis,一起来学习一下。
1、背景
目前大多数的CTR模型采用的是Embedding和Feature Interaction(以下简称FI)架构,如下图所示:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第2张图片](http://img.e-com-net.com/image/info8/e01cb495f6044d48880b3039c7d1067f.jpg)
当前大多数的研究主要集中在设计新颖的网络架构来更好的捕获显式或隐式的特征交互,如Wide & Deep的Wide部分、DCN中的CrossNet、DIN中的注意力机制等等。而另一个主要的部分,即Embedding模块同样十分重要,出于以下两个原因:
1)Embedding模块是FI模块的上游模块,直接影响FI模块的效果;
2)CTR模型中的大多数参数集中在Embedding模块,对于模型效果有十分重要的影响。
但是,Embedding模块却很少有工作进行深入研究,特别是对于连续特征的embedding方面。接下来,首先简单介绍下CTR模型中连续特征几种常见的处理方式,然后对论文提出的AutoDis框架进行介绍。
2、连续特征处理
CTR预估模型的输入通常包含连续特征和离散特征两部分。对于离散特征,通常通过embedding look-up操作转换为对应的embedding;而对于连续特征的处理,可以概括为三类:No Embedding, Field Embedding和Discretization(离散化)。
2.1 No Embedding
第一类是不对连续特征进行embedding操作,如Wide & Deep直接使用原始值作为输入,而在Youtube DNN中,则是对原始值进行变换(如平方,开根号)后输入:

这类对连续特征不进行embedding的方法,由于模型容量有限,通常难以有效捕获连续特征中信息。
2.2 Field Embedding
第二类是进行 Field Embedding,也就是同一field(一个连续特征可以看作是一个field)的特征无论取何值,共享同一个embedding,随后将特征值与其对应的embedding相乘作为模型输入:
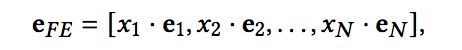
由于同一field的特征共享同一个embedding,并基于不同的取值对embedding进行缩放,这类方法的表达能力也是有限的。
2.3 Discretization
Discretization即将连续特征进行离散化,是工业界最常用的方法。这类方法通常是两阶段的,即首先将连续特征转换为对应的离散值,再通过look-up的方式转换为对应的embedding。首先探讨一个问题,为什么需要对连续特征进行离散化呢?或者说离散化为什么通常能够带来更好的效果呢?关于这个问题的探讨,可以参考知乎问题:
https://www.zhihu.com/question/31989952/answer/54184582
总的来说,将连续特征进行离散化给模型引入了非线性,能够提升模型表达能力,而对于离散化的方式,常用的有以下几种:
1) EDD/EFD (Equal Distance/Frequency Discretization):即等距/等频离散化。对于等距离散化,首先基于特征的最大值和最小值,以及要划分的桶的个数Hj,计算桶之间的间距:
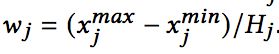
随后基于特征值、最小值以及间距计算对应的分桶:
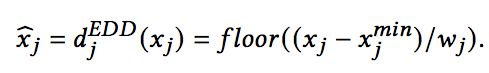
对于等频离散化,则是基于数据中特征的频次进行分桶,每个桶内特征取值的个数是相同的。
2)LD (Logarithm Discretization):对数离散化,其计算公式如下:
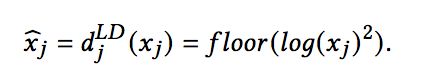
3) TD (Tree-based Discretization):基于树模型的离散化,如使用GBDT。具体的做法可以参考论文中的提及的相关工作,这里不进行具体介绍。
尽管离散化在工业界广泛引用,但仍然有以下三方面的缺点:
1)TPP (Two-Phase Problem):将特征分桶的过程一般使用启发式的规则(如EDD、EFD)或者其他模型(如GBDT),无法与CTR模型进行一起优化,即无法做到端到端训练;
2)SBD (Similar value But Dis-similar embedding):对于边界值,两个相近的取值由于被分到了不同的桶中,导致其embedding可能相差很远;
3)DBS (Dis-similar value But Same embedding):对于同一个桶中的边界值,两边的取值可能相差很远,但由于在同一桶中,其对应的embedding是相同的。
上述的三种局限可以通过下图进一步理解:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第3张图片](http://img.e-com-net.com/image/info8/2a909b3c63d2483db76a91fa8c405e4f.jpg)
2.4 总结
上述三种对于连续特征的处理方式的总结如下表所示:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第4张图片](http://img.e-com-net.com/image/info8/e602287c7cb242d2828c9e3ea6a703cc.jpg)
可以看到,无论是何种方式,都存在一定的局限性。而本文提出了AutoDis框架,具有高模型容量、端到端训练,每个特征取值具有独立表示的特点,接下来对AutoDis进行介绍。
3、AutoDis介绍
为了实现高模型容量、端到端训练,每个特征取值具有独立表示,AutoDis设计了三个核心的模块,分别是meta- embeddings、automatic discretization和 aggregation模块,其整体架构如下图所示:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第5张图片](http://img.e-com-net.com/image/info8/77163eed2f8140f59be14a5a51e4d02c.jpg)
接下来,对三个核心模块进行分别介绍。
3.1 Meta-Embeddings
为了提升模型容量,一种朴素的处理连续特征的方式是给每一个特征取值赋予一个独立的embedding。显然,这种方法参数量巨大,无法在实践中进行使用。另一方面,Field Embedding对同一域内的特征赋予相同的embedding,尽管降低了参数数量,但模型容量也受到了一定的限制。为了平衡参数数量和模型容量,AutoDis设计了Meta-embeddings模块。
对于第j个域的连续特征,对应Hj个meta-embeddings(Hj可以看作是分桶的个数,每一个桶对应一个embedding)。对于连续特征的一个具体取值,则是通过一定方式将这Hj个embedding进行聚合。相较于Field Embedding方法,每一个Field对应Hj个embedding,提升了模型容量,同时,参数数量也可以通过Hj进行很好的控制。
3.2 Automatic Discretization
Automatic Discretization模块可以对连续特征进行自动的离散化,实现了离散化过程的端到端训练。具体来说,对于第j个连续特征的具体取值xj,首先通过两层神经网络进行转换,得到Hj长度的向量:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第6张图片](http://img.e-com-net.com/image/info8/cc24baf9b406434393a9e88322fa25a4.jpg)
那么,该特征取值被分到第h个桶的概率计算如下:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第7张图片](http://img.e-com-net.com/image/info8/c840da4e595a4315ba9d605d70225435.jpg)
传统的离散化方式是将特征取值分到某一个具体的桶中,即对每个桶的概率进行argmax,但这是一种无法进行梯度回传的方式。而上式可以看作是一种soft discretization,通过调节温度系数????,可以达到近似argmax的效果,同时也可以实现梯度回传,实现了离散化过程的端到端训练(这种方式也称为softargmax,最近工作中也经常使用)。
对于温度系数????,当其接近于0时,得到的分桶概率分布接近于one-hot,当其接近于无穷时,得到的分桶概率分布近似于均匀分布。对于不同的连续特征,特征取值分布是不同的,那么应该如何对不同特征选择合适的温度系数????呢?论文给出了如下的方法,将连续特征的分布情况和特征的具体取值进行综合考虑,同时将温度系数????的计算过程与模型训练进行结合:
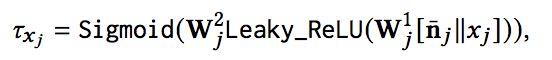
上式中,nj是第j个连续特征的统计值,包括均值和累积概率分布的统计值(我理解的是累积概率为某个值如0.1或0.2时对应的连续特征取值)
3.3 Aggregation Function
根据前两个模块,已经得到了每个分桶的embedding,以及某个特征取值对应分桶的概率分布,接下来则是如何选择合适的Aggregation Function对二者进行聚合。论文提出了如下几种方案:
1)Max-Pooling:这种方式即hard selection的方式,选择概率最大的分桶对应的embedding。前面也提到,这种方式会遇到SBD和DBS的问题。
2)Top-K-Sum:将概率最大的K个分桶对应的embedding,进行sum-pooling。这种方式不能从根本上解决DBS的问题,同时得到的最终embedding也没有考虑到具体的概率取值。
3)Weighted-Average:根据每个分桶的概率对分桶embedding进行加权求和,这种方式确保了每个不同的特征取值都能有其对应的embedding表示。同时,相近的特征取值往往得到的分桶概率分布也是相近的,那么其得到的embedding也是相近的,可以有效解决SBD和DBS的问题。
3.4 模型训练
模型的训练过程同一般的CTR过程相似,采用二分类的logloss指导模型训练,损失如下:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第8张图片](http://img.e-com-net.com/image/info8/ca20e8136f3f49d18ae19e9fb5d32fb2.jpg)
最后再来总结一下整个AutoDis框架,Meta-Embeddings模块将每个连续特征赋予Hj个分桶,每个分桶对应一个单独的embedding;Automatic Discretization模块实现了端到端的分桶,每个具体的特征取值得到分桶的概率分布;Aggregation Function模块通过Weighted-Average的方式得到每个特征取值对应的embedding,并有效解决SBD和DBS的问题。
4、实验结果及分析
最后来看一下实验结果,离线和线上均取得了不错的提升:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第9张图片](http://img.e-com-net.com/image/info8/d6aabf27b4594cb2a8c2ecf552015e40.jpg)
那么,AutoDis是否有效解决了SBD和DBS的问题呢?实验结果也印证了这一点:
![推荐系统遇上深度学习(一一八)-[华为]一种CTR预估中连续特征的Embedding学习框架..._第10张图片](http://img.e-com-net.com/image/info8/c8ac96a0ab1c403eaa72252e3acc7cd5.jpg)
好了,论文就介绍到这里,本文不仅对于连续特征的处理进行了比较详尽的总结,还提出了一种端到端的连续特征离散化处理方式,比较值得阅读~~