GIKT:A Graph-based Interaction Model for Knowledge Tracing
论文地址:[2009.05991] GIKT: A Graph-based Interaction Model for Knowledge Tracing (arxiv.org)
代码地址:
ApexEDM/GIKT: GIKT: A Graph-based Interaction Model for Knowledge Tracing (github.com)
个人理解:本篇文章使用图神经网络继续知识追踪,简单来说,就是借由图来得到更加合适的exercise和concept嵌入向量,然后送入后续的网络进行预测。
摘要:GIKT的提出主要是为了解决两个问题:一,难以捕获长距离的序列依赖关系;二,难以建模问题之间,知识点之间的潜在联系。GIKT在进行预测时,使用了上一层传递过来的隐层状态,过往的历史问题向量,当前的问题向量,和相关的知识点向量。在三个数据集上的实验表明,GIKT能够达到SOTA效果。
一,introduction
现有的很多KT模型都是基于知识点序列的,而非题目本身,就很难衡量相同知识点下不同题目的个性化。如下图所示,有的题目不知含有一个知识点,有的知识点也不知包含一道题目,因此我们需要考虑不同题目或知识点之间的潜在联系。比如,当学生对于知识点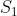 的更新有可能会涉及到知识点
的更新有可能会涉及到知识点![]() ,因此必须要考虑潜在的知识点或题目的内在联系。
,因此必须要考虑潜在的知识点或题目的内在联系。

GCN能够聚合该节点与相邻节点,因此使用GCN来嵌入题目和知识点向量,使其包含更多的语义信息。除此之外,还需要考虑题目序列之内的长期依赖关系,作者提出了以一个reacp module来选择与当前问题最相关的hidden state 或者 exercise。在recap module后是interaction module,使用注意力机制来加权和四种信息(current hidden state,current question embedding,skill embedding,relevant exercise)来进行预测。
二,related work
2.1 knowledge tracing
介绍了两种知识追踪模型类型:传统机器学习方法,深度学习方法。
2.2 图神经网络
主要介绍了GCN,在这里推荐去学习李沐的视频:
零基础多图详解图神经网络(GNN/GCN)【论文精读】_哔哩哔哩_bilibili
李老师,讲的很好。
三,Preliminarilies
这里我的理解是,创建一个![]() 的矩阵来存储知识点与题目之间的关系。
的矩阵来存储知识点与题目之间的关系。
四,The proposed method GIKT
4.1 总结构
首先讲一下,这是一个端到端的模型,看了李沐大神的视频应该知道图卷积神经网络是起到什么作用,这里我也用箭头指出来了,作者也对这里的GCN层数做了消融实验。
4.2 embedding propagation

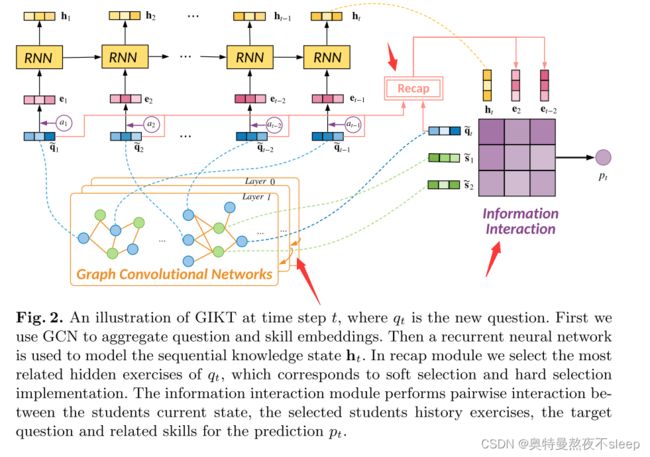
其中,l代表卷积神经网络的第几层,求和的下标表示与该节点相邻的节点。作者在下文的论述中也对层数进行了消融实验,结果如下:
4.3 state evolution
可以看到,模型在更新学生的知识点掌握程度时,使用的是RNN。

4.4 recap module
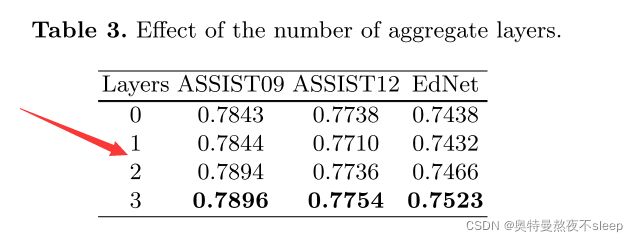
这里有两种不同的选择方式,hard selection,soft selection 。其中hard selection 选择与该题目包含相同知识点的题目,soft selection根据注意力机制来进行选择,并设置选择阈值。
筛选出与当前预测题目最合适的history exercise 或者 hiddden state 。在这里分为两种:一种是hard selection ;另一种是soft selection。hard selection选择过往序列中与当前题目含有相同知识点的exercise或hidden state embedding ,而soft selection选择过往序列中与当前exercise进行注意力计算后的top-k个embedding(且需要满足注意力值在阈值以上)。作者筛选过往embedding的过程中,特意区别开了exercise 和 hidden state embedding,并且也在文章后面进行了消融实验来研究每一种的区别。
4.5 interaction module
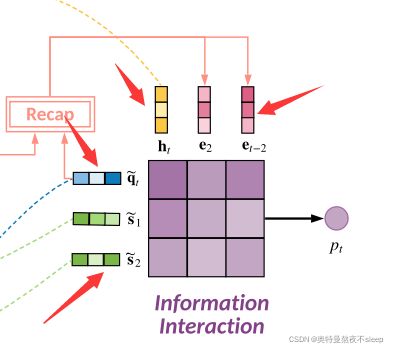
这里的交互模块,可以看到一共有四种颜色的向量,即作者要进行交互加权的向量。分别是:current exercise embedding,related skill embedding,current hidden state,history exercise embedding。作者在这里对这四种向量进行了加权处理,处理步骤如下:
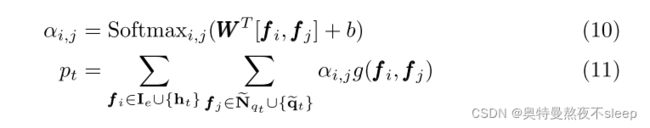
可以看到,两个加权符号下分别对应着图中矩阵的行列,我认为作者这样加权处理的方式来源于实验尝试,并无理论依据。包括这里作者也进行了消融实验,包括去掉一些interaction向量或者去掉注意力机制,结果如下:
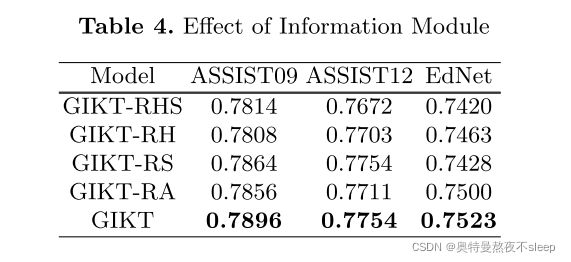
具体每个模型对应哪一种处理方式可以参照论文中的叙述。
4.6 optimization
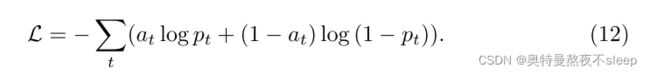
在这里还是使用的交叉熵损失函数来进行反向传播求梯度。
5,experiment
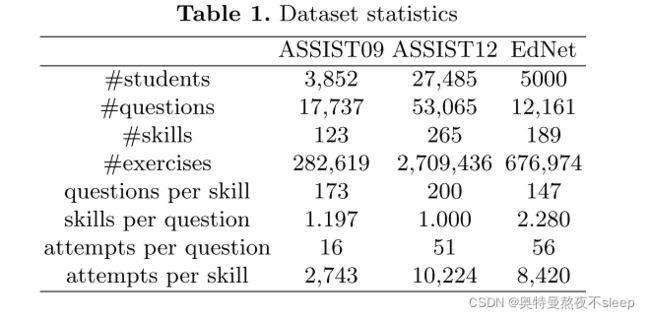
在这里首先看一下数据集,我们看论文的时候往往观察数据集使用的是不是一样,但是也忽略了作者对数据集的处理。在这里作者明显是对数据集做了处理的,去除了一些过短的题目序列。此外,训练集与测试集的划分是按照80%训练集与20%测试集划分的。实验指标使用的是AUC,而不是ACC,其实都可以。
凡是实验,肯定是作者的模型是最棒的,我们可以把结果贴出来看一下:
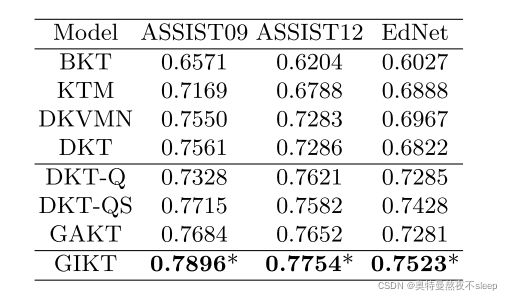
可以看到,大概是1%左右的进步,相对于和作者使用的方法相似的基线模型