遗传算法求解背包问题(python)
其实遗传算法是一种处理问题的思想,因为遗传算法整个体系都是在说对于一种问题的处理思路和原则,而不是一个具体的代码编写过程。
1. 算法过程
关键步骤如下:
(1)基因编码:在这个过程中,尝试对一些个体的基因做一个描述,构造这些基因的结构,有点像确定函数自变量的过程。
(2)设计初始群体:在这里需要造一个种群出来,这些种群有很多生物个体但基因不同。
(3)适应度计算(剪枝):这里对那些不符合要求的后代进行剔除,不让他们产生后代。否则他们产生的后代只会让计算量更大而对逼近目标没有增益。
(4)产生下一代:有3种方法,即:直接选择,基因重组,基因突变
而后回到步骤(3)进行循环,适应度计算,产生下一代,这样一代一代找下去,直到找到最优解为止。
遗传算法的应用领域:如TSP问题(旅行商问题),九宫问题,生产调度问题,背包问题等。
2. 背包问题
这里用一个具体的示例来说明遗传算法的应用。
背包问题是一种组合优化的NP(多项式复杂程度的非确定性问题)完全问题,这类问题的特点很明显,即“生成问题的一个解通常比验证一个给定的解需要花更多的时间”。
背包问题的大意是,有N件物品和一个容量为V的背包,第i件物品的重量是w[i]w[i],价值是v[i]v[i],求解将哪些物品装入背包可使这些物品的重量总和不超过背包容量,且价值的总和最大。
这种问题就是典型的NP问题,验证一个猜想的解比算出一组解要快的多。
例:假设有一个背包,可以放置80公斤的物品,此外还有表:
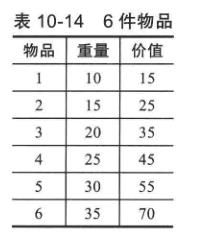
这时如果用普通的算法就有一种是穷举法,这里还可以实施,但如果有128种物品的话,就不能再用穷举法了,这时遗传算法就派上用场了。
(1)基因编码:一共有6种物品,每种物品的有无可以作为一个独立的基因片段,如:

假如只有物品2,3,6,这时的染色体是:011001
(2)设计初始群体:
为了计算方便设置初始群体为4个初始生物个体,随机产生。注意:这里的初始个数的选择要视具体情况而定,如果初始数量太少可能会导致在向量空间中覆盖面积过小而导致收敛到了非最优解就终止了算法。
(3)适应度计算:首先适应度计算要用一个适应函数来做标尺,设计适应度的函数为物品的总价值。这里同时还要计算物品的重量,超过80公斤的直接淘汰。然后对剩下的染色体进行一个用类似轮盘赌来进行遴选的过程,每次轮盘转动中奖的基因组就允许繁殖一次,如果一次都没中的基因组将无法得到延续。而遴选的原则是从生物多样化中进行挑选,淘汰比较弱的是可以的,但不建议淘汰的比例太大。
(4)生产下一代
被轮盘赌选中的基因需要进行基因重组产生下一代,计算过程如下:
其实就是把基因片段从中间的某个地方断开,然后交叉进行组合来形成新的基因,如:
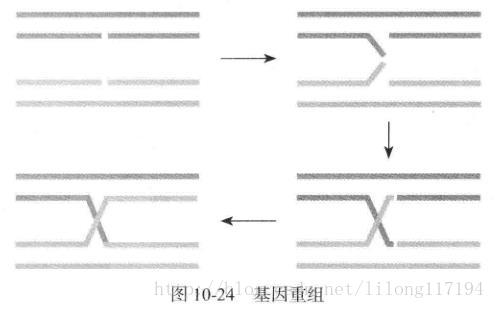
这里基因重组的断开的位置是可以随意进行的,同时注意不要一个基因自身和自身去做重组,没有意义,因为怎样重组还是自己。
这里先暂不考虑基因突变的情况。。。
(5)迭代计算
这里一代一代用这种规则做下去,直接求重量和价值。这里可以发现一个现象,就是适应度函数的值比上一代的适应度更好了。在迭代的过程中如果发现连续几代的适应度函数值基本不增加或者甚至减少的情况,那说明函数已经收敛了。其实收敛的速度会受到很多因素而变化,如基因的长度,基因重组时的方案,基因变异的程度,每一代产生个体的数量等。
3. 代码实现
# coding=utf-8
import random
#背包问题
# 物品 重量 价格
X = {
1: [10, 15],
2: [15, 25],
3: [20, 35],
4: [25, 45],
5: [30, 55],
6: [35, 70]}
#终止界限
FINISHED_LIMIT = 5
#重量界限
WEIGHT_LIMIT = 80
#染色体长度
CHROMOSOME_SIZE = 6
#遴选次数
SELECT_NUMBER = 4
max_last = 0
diff_last = 10000
#判断退出
def is_finished(fitnesses):
global max_last
global diff_last
max_current = 0
for v in fitnesses:
if v[1] > max_current:
max_current = v[1]
print 'max_current:',max_current # 得到当前最大的价值
diff = max_current - max_last # 价值差,也就是适应度的改变的大小
# 这里判断连续两代的改变量如果都小于5,则停止迭代
if diff < FINISHED_LIMIT and diff_last < FINISHED_LIMIT:
return True
else:
diff_last = diff
max_last = max_current
return False
#初始染色体样态
def init():
chromosome_state1 = '100100'
chromosome_state2 = '101010'
chromosome_state3 = '010101'
chromosome_state4 = '101011'
chromosome_states = [chromosome_state1,
chromosome_state2,
chromosome_state3,
chromosome_state4]
return chromosome_states
#计算适应度
def fitness(chromosome_states):
fitnesses = []
for chromosome_state in chromosome_states: # 遍历所有的染色体
value_sum = 0 # 物品重量
weight_sum = 0 # 物品价值
# 将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标
for i, v in enumerate(chromosome_state):
# 对染色体中的1,即存在的物品体重和价格求和
if int(v) == 1:
weight_sum += X[i + 1][0]
value_sum += X[i + 1][1]
fitnesses.append([value_sum, weight_sum])
return fitnesses
#筛选
def filter(chromosome_states, fitnesses):
#重量大于80的被淘汰
index = len(fitnesses) - 1
while index >= 0:
index -= 1
if fitnesses[index][1] > WEIGHT_LIMIT:
chromosome_states.pop(index) # 弹出不符合条件的染色体
fitnesses.pop(index) # 弹出不符合条件的适应度
#print chromosome_states,'\n',fitnesses
#遴选
selected_index = [0] * len(chromosome_states) # 如果[0]*3得到的是[0,0,0]
for i in range(SELECT_NUMBER):
# 随机选择染色体,然后得到相应的索引
j = chromosome_states.index(random.choice(chromosome_states))
selected_index[j] += 1
return selected_index
# 交叉产生下一代
def crossover(chromosome_states, selected_index):
chromosome_states_new = []
index = len(chromosome_states) - 1
#print 'index:',index
while index >= 0: # 遍历完所有的染色体组的染色体(其中下标-1代表最后一个染色体的索引)
print 'index:',index
index -= 1
chromosome_state = chromosome_states.pop(index)
print 'chromosome_states_3:',chromosome_states # 弹出后的染色体组
print 'chromosome_state:',chromosome_state # 弹出的染色体
for i in range(selected_index[index]):
chromosome_state_x = random.choice(chromosome_states) # 随机选择一个染色体
print 'chromosome_state_x:',chromosome_state_x
pos = random.choice(range(1, CHROMOSOME_SIZE - 1)) # 随机[1, 2, 3, 4]其中的一个数
print 'pos:',pos
chromosome_states_new.append(chromosome_state[:pos] + chromosome_state_x[pos:])
print 'chromosome_states_new:',chromosome_states_new
chromosome_states.insert(index, chromosome_state) # 恢复原染色体组
print 'chromosome_states_4:', chromosome_states
return chromosome_states_new # 返回得到的新的染色体组
if __name__ == '__main__':
# 初始群体
chromosome_states = init() # 是全局的
print 'chromosome_states:',chromosome_states
n = 100 # 迭代次数
while n > 0:
n -= 1
#适应度计算
fitnesses = fitness(chromosome_states)
#print 'fitnesses:',fitnesses
if is_finished(fitnesses):
break # 如果符合条件,立刻停止循环
print '1:', fitnesses
#遴选
selected_index = filter(chromosome_states, fitnesses)
print '2:', selected_index
print 'chromosome_states_2:',chromosome_states
#产生下一代
chromosome_states = crossover(chromosome_states, selected_index)
print '3:', chromosome_states
print str(n)+'..................................' # 迭代次数
fitnesses = fitness(chromosome_states)
print 'fitnesses:',fitnesses
print chromosome_states
运行结果:
chromosome_states: ['100100', '101010', '010101', '101011']
max_current: 95
1: [[60, 35], [105, 60], [140, 75], [175, 95]]
2: [1, 2, 1]
chromosome_states_2: ['100100', '101010', '010101']
index: 2
chromosome_states_3: ['100100', '010101']
chromosome_state: 101010
chromosome_state_x: 010101
pos: 4
chromosome_states_new: ['101001']
chromosome_state_x: 100100
pos: 1
chromosome_states_new: ['101001', '100100']
chromosome_states_4: ['100100', '101010', '010101']
index: 1
chromosome_states_3: ['101010', '010101']
chromosome_state: 100100
chromosome_state_x: 010101
pos: 4
chromosome_states_new: ['101001', '100100', '100101']
chromosome_states_4: ['100100', '101010', '010101']
index: 0
chromosome_states_3: ['100100', '101010']
chromosome_state: 010101
chromosome_state_x: 101010
pos: 2
chromosome_states_new: ['101001', '100100', '100101', '011010']
chromosome_states_4: ['100100', '010101', '101010']
3: ['101001', '100100', '100101', '011010']
99..................................
max_current: 70
1: [[120, 65], [60, 35], [130, 70], [115, 65]]
2: [1, 2, 0, 1]
chromosome_states_2: ['101001', '100100', '100101', '011010']
index: 3
chromosome_states_3: ['101001', '100100', '011010']
chromosome_state: 100101
chromosome_states_4: ['101001', '100100', '100101', '011010']
index: 2
chromosome_states_3: ['101001', '100101', '011010']
chromosome_state: 100100
chromosome_state_x: 011010
pos: 2
chromosome_states_new: ['101010']
chromosome_state_x: 011010
pos: 2
chromosome_states_new: ['101010', '101010']
chromosome_states_4: ['101001', '100100', '100101', '011010']
index: 1
chromosome_states_3: ['100100', '100101', '011010']
chromosome_state: 101001
chromosome_state_x: 100100
pos: 2
chromosome_states_new: ['101010', '101010', '100100']
chromosome_states_4: ['101001', '100100', '100101', '011010']
index: 0
chromosome_states_3: ['101001', '100100', '100101']
chromosome_state: 011010
chromosome_state_x: 100101
pos: 4
chromosome_states_new: ['101010', '101010', '100100', '011001']
chromosome_states_4: ['101001', '100100', '011010', '100101']
3: ['101010', '101010', '100100', '011001']
98..................................
max_current: 70
fitnesses: [[105, 60], [105, 60], [60, 35], [130, 70]]
['101010', '101010', '100100', '011001']
从运行结果可以看出详细的运行过程,但每次的运行结果不同,如果基于代码中的各种条件设置,最终的效果应该是最大的适应度(总价值)为130,即物品2,3,6的组合。
这里用的收敛条件是连续两代的适应函数最大值不再增加,出现这种情况则判断为收敛。