python区域掩膜白话,显示目标区域
def shp2clip(originfig,ax,shpfile,region):
sf = shp.Reader(shpfile)
vertices = []
codes = []
for shape_rec in sf.shapeRecords():
if shape_rec.record[2] in region: # 对应数字要找到
pts = shape_rec.shape.points
prt = list(shape_rec.shape.parts) + [len(pts)]
for i in range(len(prt) - 1):
for j in range(prt[i], prt[i + 1]):
vertices.append((pts[j][0], pts[j][1]))
codes += [Path.MOVETO]
codes += [Path.LINETO] * (prt[i + 1] - prt[i] - 2)
codes += [Path.CLOSEPOLY]
clip1 = Path(vertices, codes)
clip2 = PathPatch(clip1, transform=ax.transData)
for contour in originfig.collections:
contour.set_clip_path(clip2)
return clip2这是选择shp文件的代码
import shapefile as shp
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
from matplotlib.path import Path
from matplotlib.patches import PathPatch
def shp2clip(originfig,ax,shpfile,region):
sf = shp.Reader(shpfile)
vertices = []
codes = []
for shape_rec in sf.shapeRecords():
if shape_rec.record[2] in region: # 对应数字要找到
pts = shape_rec.shape.points
prt = list(shape_rec.shape.parts) + [len(pts)]
for i in range(len(prt) - 1):
for j in range(prt[i], prt[i + 1]):
vertices.append((pts[j][0], pts[j][1]))
codes += [Path.MOVETO]
codes += [Path.LINETO] * (prt[i + 1] - prt[i] - 2)
codes += [Path.CLOSEPOLY]
clip1 = Path(vertices, codes)
clip2 = PathPatch(clip1, transform=ax.transData)
for contour in originfig.collections:
contour.set_clip_path(clip2)
return clip2
# 进行绘图
plt.rcParams.update({'font.size': 20})
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号乱码问题
plt.rcParams['axes.unicode_minus'] = False
# 设置画布和绘画区
fig = plt.figure(figsize=[12, 18])
ax = fig.add_subplot(111)
yazhouguojia=["China", "Mongolia", "North Korea", "South Korea", "Japan",
"Philippines", "Vietnam", "Laos", "Cambodia", "Myanmar", "Thailand", "Malaysia", "Malaysia", "Singapore",
"Indonesia", "east Timor",
"Nepal", "Bhutan", "Bengal", "India", "Pakistan", "SriLanka", "Maldives",
"Kazakhstan", "Kyrgyzstan", "Tajikistan", "Uzbekistan", "Uzbekistan",
"Afghanistan", "Iraq", "Iraq", "Syria", "Jordan", "Lebanon", "Israel", "Palestine", "SaudiArabia",
"Bahrain", "Qatar", "Kuwait", "United ArabEmirates", "Oman", "Yemen", "Georgia", "Armenia", "Azerbaijan",
"Turkey", "Cypru" ]
filename = r"D:\lunwen\lunwenshuju\各种作业数据\air.2m.mon.mean.nc"
f = xr.open_dataset(filename)
air = f["air"][0, 0, :, :]
lon = f["lon"][:]
lat = f["lat"][:]
time = f["time"]
lon, lat = np.meshgrid(lon, lat)
cs = ax.contourf(lon, lat, air, cmap='Spectral_r')
fig.colobar = fig.colorbar(cs, orientation='vertical', shrink=0.75)
# 已经将全球的温度分布图画出来了,下面对中国区域的温度分布图进行掩膜路径绘画
shp2clip(cs, ax, r'D:\lunwen\lunwenshuju\Shp\Python完美白化_测试数据及脚本\country1', yazhouguojia) #调用函数
ax.set_title("亚洲国家气温填色图")
plt.show()一个简单的使用,就是读取文件,然后设定一个目标区域(我代码中设定的是亚洲区域),然后进行填色图绘制,shp2clip函数需要防止,填色好的区域,ax,以及大的shp地图文件,最后是目标区域,从大的shp文件中裁剪。
需要注意的是if shape_rec.record[2] in region:这个代码中的2需要修改可以,
sf = shapefile.Reader(r'D:\lunwen\lunwenshuju\Shp\Python完美白化_测试数据及脚本\country1')
# sf.shapeRecords()里面放了各个国家地区的信息
# 循环的目的是单个拿出来,找到中国 shape_rec是单个
for shape_rec in sf.shapeRecords():
print(shape_rec.record) #进行查看
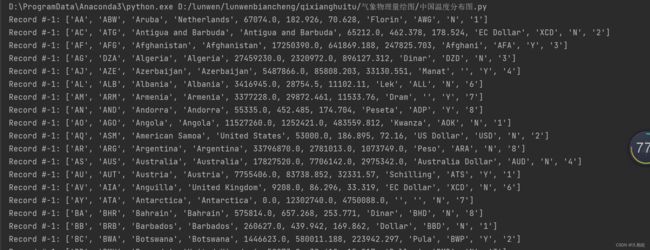
查看的结果如下,因为不同shp文件里的排列顺序不同,图中是第三个位置是国家名字,所以是record[2],要是第四个是国家名字,就把2改成3!不改出不了图。
region:只想要一个区域就只放一个区域名字,想要多个区域就放多个区域名字,非常简单好用。region一定要在record列表里面,大shp文件没有的region不会显示,就是裁剪出目标区域。