dataframe两个表合并_什么才是真正的DataFrame
今天要介绍的 paper 是 Towards Scalable Dataframe Systems,目前还是预印本。作者 Devin Petersohn 来自 Riselab,该实验室的前身是大名鼎鼎的 APMLab,诞生了 Apache Spark、Apache Mesos 等一系列著名开源项目。

本篇文章会大致分三部分:
什么是真正的 DataFrame?
为什么现在的所谓 DataFrame 系统,典型的如 Spark DataFrame,有可能正在杀死 DataFrame 的原本含义。
从 Mars DataFrame 的角度来看这个问题。
 DataFrame数据模型 DataFrame 的需求来源于把数据看成矩阵和表。但是,矩阵中只包含一种数据类型,未免过于受限;同时,关系表要求数据必须要首先定义 schema。对于 DataFrame 来说,它的列类型可以在运行时推断,并不需要提前知晓,也不要求所有列都是一个类型。因此,DataFrame 可以理解成是关系系统、矩阵、甚至是电子表格程序(典型如 Excel)的合体。
DataFrame数据模型 DataFrame 的需求来源于把数据看成矩阵和表。但是,矩阵中只包含一种数据类型,未免过于受限;同时,关系表要求数据必须要首先定义 schema。对于 DataFrame 来说,它的列类型可以在运行时推断,并不需要提前知晓,也不要求所有列都是一个类型。因此,DataFrame 可以理解成是关系系统、矩阵、甚至是电子表格程序(典型如 Excel)的合体。 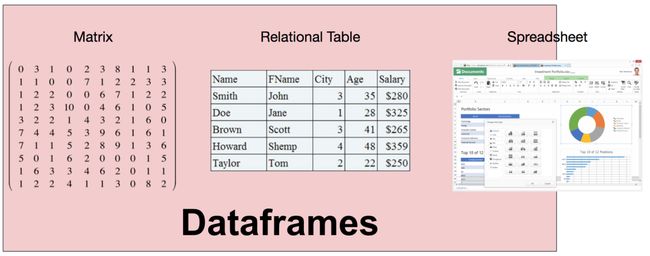 跟关系系统相比,DataFrame 有几个特别有意思的属性,让 DataFrame 因此独一无二。
跟关系系统相比,DataFrame 有几个特别有意思的属性,让 DataFrame 因此独一无二。
保证顺序,行列对称
首先,无论在行还是列方向上,DataFrame 都是有顺序的;且行和列都是一等公民,不会区分对待。 拿 pandas 举例子,当创建了一个 DataFrame 后,无论行和列上数据都是有顺序的,因此,在行和列上都可以使用位置来选择数据。1]: In [丰富的 API
DataFrame 的 API 非常丰富,横跨关系(如 filter、join)、线性代数(如 transpose、dot)以及类似电子表格(如 pivot)的操作。 还是以 pandas 为例,一个 DataFrame 可以做转置操作,让行和列对调。[10]: df2 = df.copy()直观的语法,适合交互式分析
用户可以对 DataFrame 数据不断进行探索,查询结果可以被后续的结果复用,可以非常方便地用编程的方式组合非常复杂的操作,很适合交互式的分析。
列中允许异构数据
DataFrame 的类型系统允许一列中有异构数据的存在,比如,一个 int 列中允许有 string 类型数据存在,它可能是脏数据。这点看出 DataFrame 非常灵活。
[10]: df2 = df.copy() 数据模型
现在我们可以对什么是真正的 DataFrame 正式下定义: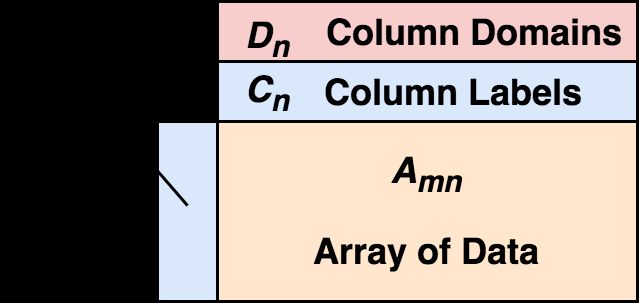 DataFrame 由二维混合类型的数组、行标签、列标签、以及类型(types 或者 domains)组成。在每列上,这个类型是可选的,可以在运行时推断。从行上看,可以把 DataFrame 看做行标签到行的映射,且行之间保证顺序;从列上看,可以看做列类型到列标签到列的映射,同样,列间同样保证顺序。 行标签和列标签的存在,让选择数据时非常方便。
DataFrame 由二维混合类型的数组、行标签、列标签、以及类型(types 或者 domains)组成。在每列上,这个类型是可选的,可以在运行时推断。从行上看,可以把 DataFrame 看做行标签到行的映射,且行之间保证顺序;从列上看,可以看做列类型到列标签到列的映射,同样,列间同样保证顺序。 行标签和列标签的存在,让选择数据时非常方便。
13]: df.17]: df3 = df.shift( 那么会有同学说 Koalas 呢?Koalas 提供了 pandas API,用 pandas 的语法就可以在 spark 上分析了。实际上,因为 Koalas 也是将 pandas 的操作转成 Spark DataFrame 来执行,因为 Spark DataFrame 内核本身的特性,注定 Koalas 只是看上去和 pandas 一致。 为了说明这点,我们使用 数据集(Hourly Ridership by Origin-Destination Pairs),只取 2019 年的数据。 对于 pandas,我们按天聚合,并按 30 天滑动窗口来计算平均值。
那么会有同学说 Koalas 呢?Koalas 提供了 pandas API,用 pandas 的语法就可以在 spark 上分析了。实际上,因为 Koalas 也是将 pandas 的操作转成 Spark DataFrame 来执行,因为 Spark DataFrame 内核本身的特性,注定 Koalas 只是看上去和 pandas 一致。 为了说明这点,我们使用 数据集(Hourly Ridership by Origin-Destination Pairs),只取 2019 年的数据。 对于 pandas,我们按天聚合,并按 30 天滑动窗口来计算平均值。
[22]: df = pd.read_csv(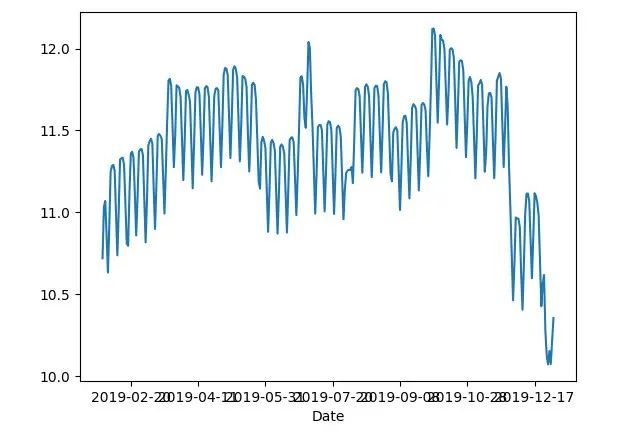 如果是 Koalas,因为它的 API 看上去和 pandas 一致,因此,我们按照 Koalas 的文档做 import 替换。
如果是 Koalas,因为它的 API 看上去和 pandas 一致,因此,我们按照 Koalas 的文档做 import 替换。
1]: 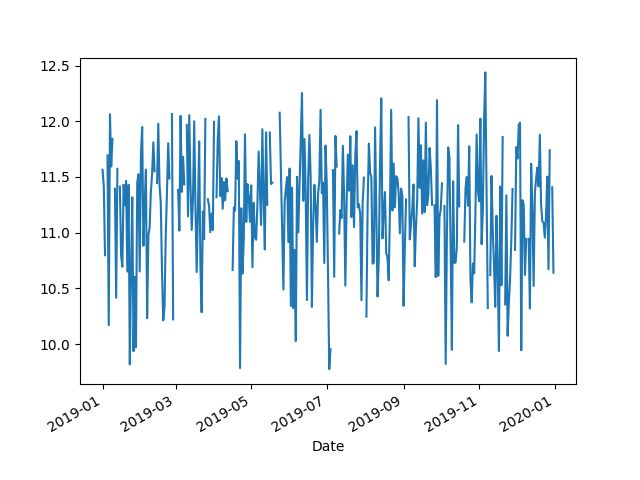 然后令人惊讶的是,结果并不一致。大费周章后才查到,原因是顺序问题,聚合的结果后并不保证排序,因此要得到一样的结果需要在 rolling 前加 sort_index(),确保 groupby 后的结果是排序的。
然后令人惊讶的是,结果并不一致。大费周章后才查到,原因是顺序问题,聚合的结果后并不保证排序,因此要得到一样的结果需要在 rolling 前加 sort_index(),确保 groupby 后的结果是排序的。
In In [6]: df.shift(1)
---------------------------------------------------------------------------In 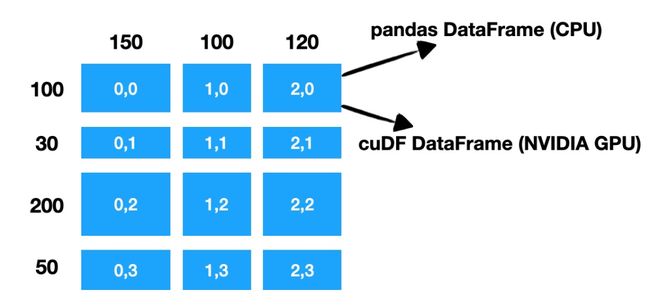 图里的示例中,一个行数 380、列数 370 的 DataFrame,被 Mars 分成 3x3 一共 9 个 chunk,根据计算在 CPU 还是 NVIDIA GPU 上进行,用 pandas DataFrame 或者 cuDF DataFrame 来存储数据和执行真正的计算。可以看到,Mars 既会在行上,也会在列上进行分割,这种在行上和列上的对等性,让 DataFrame 的矩阵本质能得以发挥。 在单机真正执行时,根据初始数据的位置,Mars 会自动把数据分散到多核或者多卡执行;对于分布式,会将计算分散到多台机器执行。 Mars DataFrame 保留了行标签、列标签和类型的概念。因此能够想象如同 pandas 一样,可以在比较大的数据集上根据标签进行筛选。
图里的示例中,一个行数 380、列数 370 的 DataFrame,被 Mars 分成 3x3 一共 9 个 chunk,根据计算在 CPU 还是 NVIDIA GPU 上进行,用 pandas DataFrame 或者 cuDF DataFrame 来存储数据和执行真正的计算。可以看到,Mars 既会在行上,也会在列上进行分割,这种在行上和列上的对等性,让 DataFrame 的矩阵本质能得以发挥。 在单机真正执行时,根据初始数据的位置,Mars 会自动把数据分散到多核或者多卡执行;对于分布式,会将计算分散到多台机器执行。 Mars DataFrame 保留了行标签、列标签和类型的概念。因此能够想象如同 pandas 一样,可以在比较大的数据集上根据标签进行筛选。
1]: import mars.dataframe 6]: 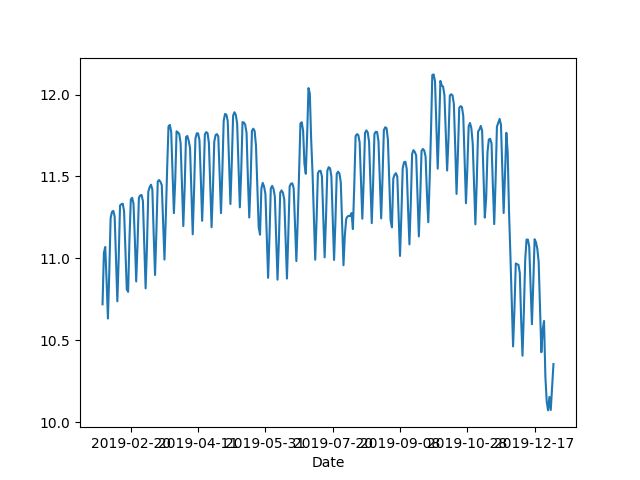 对于 shift,不光结果正确,而且执行时能利用多核、多卡和分布式的能力。
对于 shift,不光结果正确,而且执行时能利用多核、多卡和分布式的能力。
In 1]: Mars 开源项目地址:
https://github.com/mars-project/mars
Mars 中文文档:
https://docs.pymars.org/zh_CN/latest/
