Spring、MyBatis 面试题,java架构师教程百度云
-
1.4 Spring 事务
-
2 Spring MVC
-
3 MyBatis
1 Spring
===========================================================================
1.1 控制反转思想
介绍一下 Spring 的 IoC
控制反转指的是在程序中,原本需要我们手动创建的对象现在可以由 Spring 的 IoC 容器帮助创建和注入依赖对象,我们只需要告诉容器什么时候创建对象、创建什么对象,完全不用考虑对象是怎么创建出来的。
2 传统程序设计与 IoC 模式的区别
传统程序设计流程如下图所示,是主动去创建相关对象然后再组合起来:
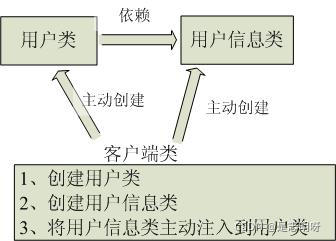
当有了 IoC 的容器后,在客户端类中不再主动去创建这些对象了,而是告诉 IoC 容器我们想要什么,如下图所示:
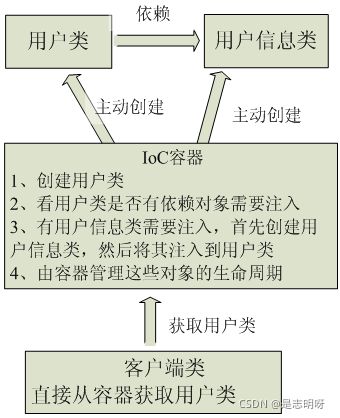
3 介绍一下 Spring IoC 容器的初始化过程
这个过程包括 BeanDefinition 的资源定位、载入和注册三个基本过程。具体分别如下:
-
第一个过程是 Bean 的资源定位。这个定位过程类似于容器寻找数据的过程,就像用水桶装水先要把水找到一样;
-
第二个过程是 BeanDefinition 的载入。这个载入过程是将用户定义好的 Bean 表示成 IoC 容器内部的数据结构,而这个容器内部的数据结构就是 BeanDefinition;
-
第三个过程是向 IoC 容器注册这些 BeanDefinition。这个注册过程就是将在 IoC 容器内部将 BeanDefinition 注入到一个 HashMap 中去的过程。
参考文献:传送门
4 介绍一下依赖注入(DI)
依赖注入是控制反转的一种实现方式,指的是程序所依赖的组件在运行时会动态地加载到程序中。
依赖注入的案例:
汽车是一个复杂对象,其中包含许多的组件,如发动机、轮子等。当我们想要创建两辆不同的汽车时,有两种方案:
-
在 car 类中实例化一个 wheel 对象,然后实例化这个 car 对象;
-
在外部创建 wheel 对象,然后将其传入到 car 类中。
5 依赖注入的方式有哪些
-
构造器注入;
-
Setter 方法注入;
-
属性(p)命名空间或者构造器(c)命名空间注入。
1.2 面向切面编程(AOP)
1 介绍一下 AOP
面向切面编程是面向对象编程的补充,它将面向对象编程产生的各个业务模块所共同调用的部分封装起来,达到与主业务逻辑解耦的目的。
同时,AOP 可以在不改变原来的代码的情况下,实现对原有功能的增强。(代理模式,开闭原则)
2 介绍一下 Spring AOP 中创建代理的方式
Spring AOP 就是基于动态代理的,Spring 中的 AOP 目前支持 JDK 动态代理和 Cglib 代理。
如果要代理的对象,实现了某个接⼝,那么 Spring AOP 会使⽤ JDK Proxy,去创建代理对象,⽽对于没有实现接⼝的对象,就⽆法使⽤ JDK Proxy 去进⾏代理了,这时候Spring AOP 会使⽤ Cglib ,这时候 Spring AOP 会使⽤ Cglib ⽣成⼀个被代理对象的⼦类来作为代理。
3 说一下 JDK 动态代理和 Cglib 代理的区别
-
JDK 动态代理本质上是实现了被代理对象的接口,而 Cglib 本质上是继承了被代理对象,覆盖其中的方法;
-
JDK 动态代理只能对实现了接口的类生成代理,Cglib 则没有这个限制。但是 Cglib 因为使用继承实现,所以 Cglib 无法代理被 final 修饰的方法或类;
-
在调用代理方法上,JDK 动态代理是通过反射机制调用,Cglib 是通过 FastClass 机制直接调用。FastClass 简单的理解,就是使用 index 作为入参,可以直接定位到要调用的方法直接进行调用;
-
在性能上,JDK1.7 之前,由于使用了 FastClass 机制,Cglib 在执行效率上比 JDK 快,但是随着 JDK 动态代理的不断优化,从 JDK 1.7 开始,JDK 动态代理已经明显比 Cglib 更快了。
JDK 动态代理只能对实现了接口的类生成代理的根本原因是通过 JDK 动态代理生成的类已经继承了 Proxy 类,所以无法再使用继承的方式去对类实现代理。
4 说一下 Spring AOP 和 AspectJ AOP 的区别
-
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强;
-
Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation);
-
Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单;
-
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比Spring AOP 快很多。
1.3 Spring bean
1 什么是 Spring bean 容器
Spring 官方文档对 bean 的解释是:
In Spring, the objects that form the backbone of your application and that are managed by the Spring IoC container are called beans. A bean is an object that is instantiated, assembled, and otherwise managed by a Spring IoC container.
翻译过来就是:
在 Spring 中,构成应用程序主干并由 Spring IoC 容器管理的对象称为 bean。bean 是一个由 Spring IoC 容器实例化、组装和管理的对象。
概念简单明了,我们提取处关键的信息:
-
bean 是对象,一个或者多个不限定;
-
bean 由 Spring 中一个叫 IoC 的东西管理;
-
我们的应用程序由一个个 bean 构成。
2 将⼀个类声明为 Spring 的 bean 的注解有哪些
我们⼀般使⽤ @Autowired 注解⾃动装配 bean,要想把类标识成可⽤于 @Autowired 注解⾃动装配的 bean 的类,采⽤以下注解可实现:
-
@Component :通⽤的注解,可标注任意类为 Spring 组件,如果⼀个Bean不知道属于哪个层,可以使⽤ @Component 注解标注;
-
@Repository : 对应持久层即 Dao 层,主要⽤于数据库相关操作;
-
@Service : 对应服务层,主要涉及⼀些复杂的逻辑;
-
@Controller : 对应 Spring MVC 控制层,主要⽤户接受⽤户请求并调⽤ Service 层返回数据给前端⻚⾯。
参考文献:传送门
3 将⼀个类声明为 Spring 的 bean 的代码实现
//将User类中的set方法去掉,使用@Autowired注解
// 这样 Spring 便会自动装配了
public class User {
@Autowired
private Cat cat;
@Autowired
private Dog dog;
private String str;
public Cat getCat() {
return cat;
}
public Dog getDog() {
return dog;
}
public String getStr() {
return str;
}
}
context:annotation-config/
4 Spring bean 的生命周期
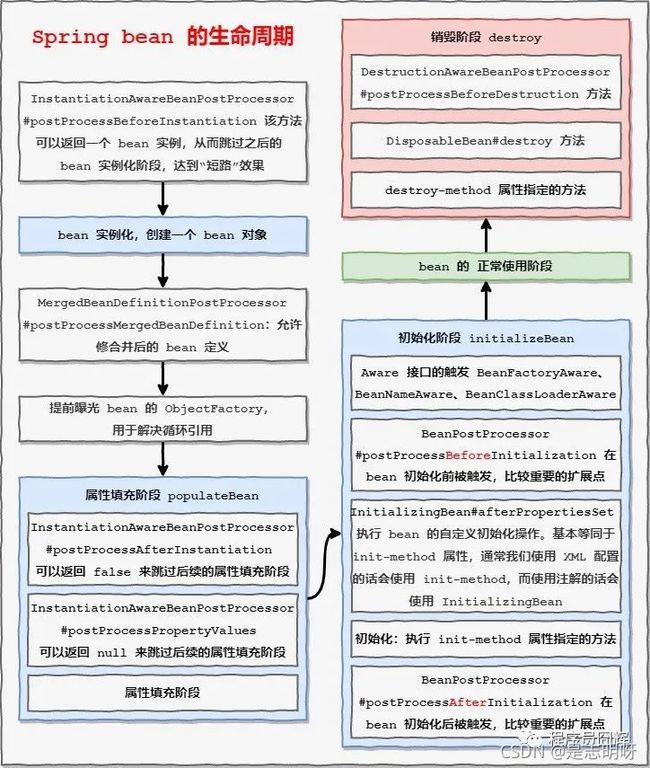
其中有颜色的部分是重要的,口语化的表达,其生命周期为:
-
首先是 bean 的实例化,创建一个 bean 对象;
-
然后是进行属性的填充;
-
然后是 bean 的初始化阶段,其中包括 Aware 接口的触发、执行 init-method 属性指定的方法等;
-
再是 bean 的正常使用阶段;
-
最后是 bean 的销毁阶段。
详细来说就是:
-
Bean 容器找到配置文件中 Spring Bean 的定义。
-
Bean 容器利用 Java Reflection API 创建一个Bean的实例。
-
如果涉及到一些属性值 利用
set()方法设置一些属性值。 -
如果 Bean 实现了
BeanNameAware接口,调用setBeanName()方法,传入Bean的名字。 -
如果 Bean 实现了
BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 -
如果Bean实现了
BeanFactoryAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 -
与上面的类似,如果实现了其他
*.Aware接口,就调用相应的方法。 -
如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法 -
如果Bean实现了
InitializingBean接口,执行afterPropertiesSet()方法。 -
如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
-
如果有和加载这个 Bean的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessAfterInitialization()方法 -
当要销毁 Bean 的时候,如果 Bean 实现了
DisposableBean接口,执行destroy()方法。 -
当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
5 bean 的作用域

6 Spring 中的单例 bean 的线程安全问题了解吗?
大部分时候我们并没有在系统中使用多线程,所以很少有人会关注这个问题。单例 bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。
常见的有两种解决办法:
-
在Bean对象中尽量避免定义可变的成员变量(不太现实);
-
在类中定义一个 ThreadLocal 成员变量,将需要的可变成员变量保存在 ThreadLocal 中(推荐的一种方式)。
7 @Component 和 @Bean 的区别
-
作⽤对象不同: @Component 注解作⽤于类,⽽ @Bean 注解作⽤于⽅法;
-
@Component 通常是通过类路径扫描来⾃动侦测并⾃动装配到 Spring 容器中(我们可以使⽤ @ComponentScan 注解定义要扫描的路径从中找出标识了需要装配的类⾃动装配到 Spring 的 bean 容器中)。 @Bean 注解通常是我们在标有该注解的⽅法中定义产⽣这个 bean,@Bean 告诉了Spring 这是某个类的示例,当我需要⽤它的时候还给我;
-
@Bean 注解⽐ Component 注解的⾃定义性更强,⽽且很多地⽅我们只能通过 @Bean 注解来注册 bean,⽐如当我们引⽤第三⽅库中的类需要装配到 Spring 容器时,则只能通过 @Bean 来实现。
1.4 Spring 事务
1 说一下 Spring 管理事务的方式
-
编程式事务,在代码中硬编码(不推荐使用);
-
声明式事务,在配置文件中配置(推荐使用);
声明式事务又分为两种:
-
基于 XML 的声明式事务;
-
基于注解的声明式事务;
2 事务的实现原理
Spring 事务的底层实现主要使用的技术:AOP(动态代理) + ThreadLocal + try/catch。
-
动态代理:基本所有要进行逻辑增强的地方都会用到动态代理,AOP 底层也是通过动态代理实现;
-
ThreadLocal:主要用于线程间的资源隔离,以此实现不同线程可以使用不同的数据源、隔离级别等等;
-
try/catch:最终是执行 commit 还是 rollback,是根据业务逻辑处理是否抛出异常来决定。
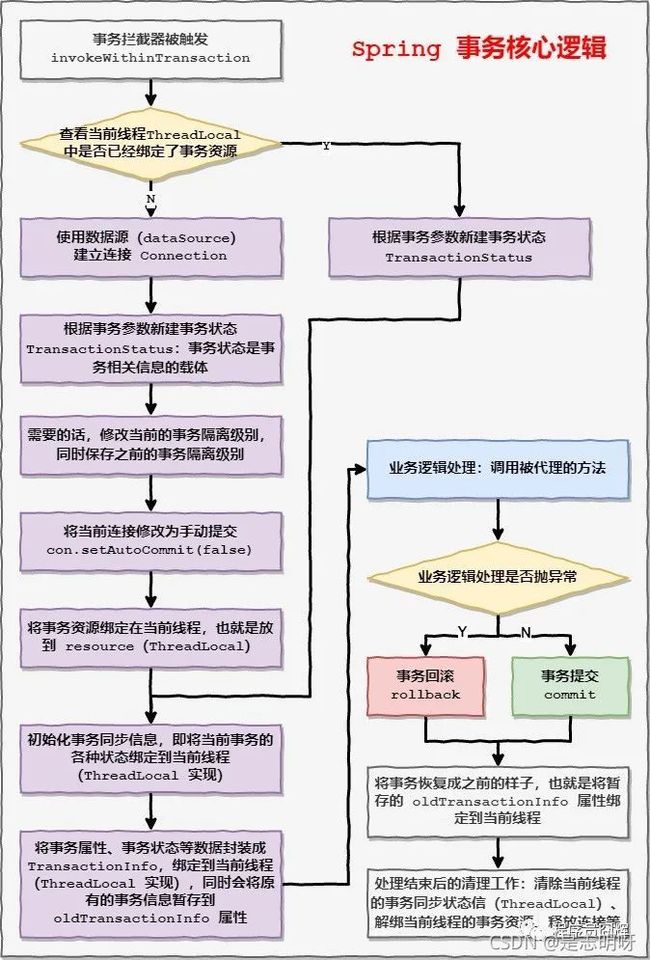
Spring 事务的核心逻辑伪代码如下:
public void invokeWithinTransaction() {
// 1.事务资源准备
try {
// 2.业务逻辑处理,也就是调用被代理的方法
} catch (Exception e) {
// 3.出现异常,进行回滚并将异常抛出
} finally {
// 现场还原:还原旧的事务信息
}
// 4.正常执行,进行事务的提交
// 返回业务逻辑处理结果
}
详细流程如下图所示:
3 说一下 Spring 事务中的隔离级别
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
-
TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ 隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别;
-
TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读;
-
TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生;
-
TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生;
-
TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
4 Spring 事务中有哪几种事务传播行为
一共是七种,按照是否支持当前事务,可以分为以下情况:
支持当前事务的情况:
-
TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务;
-
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
-
TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不支持当前事务的情况:
-
TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
-
TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
-
TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
5 Spring 的事务隔离级别是如何做到和数据库不一致的
比如数据库是可重复读,Spring 是读已提交,这是怎么实现的?
**Spring 的事务隔离级别本质上还是通过数据库来控制的,具体是在执行事务前先执行命令修改数据库隔离级别,**命令格式如下:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED
2 Spring MVC
===============================================================================
1 什么是 MVC
还记得之前的 JavaWeb 的项目中,里面的 Web 层、Service 层以及 Dao 层是否还有印象。
在 Spring MVC 下,我们⼀般把后端项⽬分为 Service层(处理业务)、Dao层(数据库操作)、Entity层(实体类)、Controller层(控制层,返回数据给前台⻚⾯)。
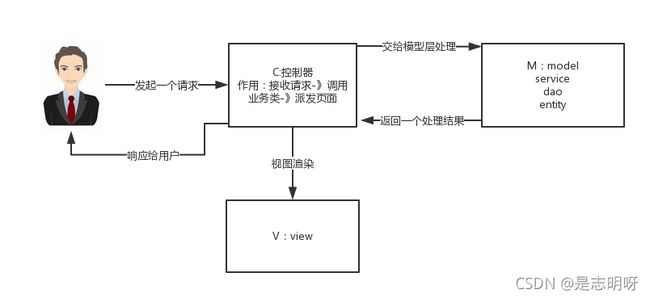
接下来,我们就开始学习 SSM 框架,即 Spring + Spring MVC + MyBatis。它们与模型层次分别一一对应。
拓展:过去的 MVC 模型就是 jsp + servlet + javabean 模式,其中:
-
JavaBean 作为模型,既可以作为数据模型来封装业务数据,又可以作为业务逻辑模型来包含应用的业务操作。其中,数据模型用来存储或传递业务数据,而业务逻辑模型接收到控制器传过来的模型更新请求后,执行特定的业务逻辑处理,然后返回相应的执行结果;
-
JSP 作为视图层,负责提供页面为用户展示数据,提供相应的表单(Form)来用于用户的请求,并在适当的时候(点击按钮)向控制器发出请求来请求模型进行更新;
-
Serlvet 作为控制器,用来接收用户提交的请求,然后获取请求中的数据,将之转换为业务模型需要的数据模型,然后调用业务模型相应的业务方法进行更新,同时根据业务执行结果来选择要返回的视图;
2 SpringMVC 的核心入口类是什么
DispatchServlet。
3 SpringMVC 的控制器是不是单例模式,如果是,有什么问题,怎么解决
是单例模式,所以在多线程访问的时候有线程安全问题,不过不能使用同步,因为会影响性能的,解决方案是在控制器里面不能写字段。
4 SpingMVC 中的控制器的注解一般用哪个,有没有别的注解可以替代
一般用 @Conntroller 注解,不能用别的注解代替。
5 @RequestMapping 注解用在类上面有什么作用
其用于类上,表示类中的所有请求与响应的方法都是以该地址作为父路径。
6 怎么样把某个请求映射到特定的方法上面
直接在方法上面加上注解 @RequestMapping,并且在这个注解里面写上要拦截的路径。
7 直接在方法上面加上注解 @RequestMapping,并且在这个注解里面写上要拦截的路径。
可以在 @RequestMapping 注解里面加上 params=”type=test”
8 如果前台有很多个参数传入,并且这些参数都是一个对象的,那么怎么样快速得到这个对象
直接在方法中声明这个对象,SpringMVC 就自动会把属性赋值到这个对象里面。
3 MyBatis
============================================================================
1 说一说什么是 MyBatis
Mybatis 是一个半 ORM(对象关系映射)的持久层框架,它内部封装了JDBC、加载驱动、创建连接、创建 statement 等繁杂的过程,开发者开发时只需要关注如何编写 SQL 语句,可以严格控制 SQL 执行性能,灵活度高。
它可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 实体类(POJO) 【Plain Old Java Objects】映射成数据库中的记录,几乎避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集的过程。
2 那什么是持久化
持久化是将程序数据在持久状态和瞬时状态间转换的机制,即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)的机制。
之所以需要持久化,是因为内存本生是不可靠的,可能会导致某些数据丢失。同时,也会因为内存的容量限制不能一直呆在内存中,需要持久化来缓存到外存。
参考文献:传送门
3 为什么说 MyBatis 是半自动的 ORM 映射工具
Hibernate 属于全⾃动 ORM 映射⼯具,使⽤ Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全⾃动的。**而 Mybatis 在查询关联对象或关联
《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》
【docs.qq.com/doc/DSmxTbFJ1cmN1R2dB】 完整内容开源分享
集合对象时,需要⼿动编写 sql 来完成,所以,称之为半⾃动 ORM 映射⼯具**。
4 #{} 和 ${} 的区别是什么
#{} 是预编译处理,${} 是字符串替换。MyBatis 在处理 #{} 时,会将 SQL 中的 #{} 替换为 ? 号,使用 PreparedStatement 的 setter 方法来赋值,MyBatis在处理 ${ } 时,就是把 ${ } 替换成变量的值。
同时,使用 #{} 可以有效的防止 SQL 注入,提高系统安全性。
5 MyBatis 的配置解析
MyBatis 的配置就相当于配置其的配置文件。
MyBatis 具有如下的配置信息:
-
properties(属性)
-
settings(设置)
-
typeAliases(类型别名)
-
typeHandlers(类型处理器)
-
objectFactory(对象工厂)
-
plugins(插件)
-
environments(环境配置)
-
environment(环境变量)
-
transactionManager(事务管理器)
-
dataSource(数据源)
-
databaseIdProvider(数据库厂商标识)
-
mappers(映射器)