Multimodal End-to-End Sparse Model for Emotion Recognition论文阅读
Multimodal End-to-End Sparse Model for Emotion Recognition论文阅读
作者:
Wenliang Dai *, Samuel Cahyawijaya *, Zihan Liu, Pascale Fung
实验室:
Center for Artificial Intelligence Research (CAiRE)
Department of Electronic and Computer Engineering
The Hong Kong University of Science and Technology, Clear Water Bay, Hong Kong
发布时间:2021
论文链接:https://arxiv.org/abs/2103.09666v1#:~:text=%EE%80%80Multimodal%20End-to-End%20Sparse%20Model%20for%20Emotion%20Recognition%EE%80%81.%20Existing,then%20performing%20%EE%80%80end-to-end%EE%80%81%20learning%20with%20the%20extracted%20features.
github链接:https://github.com/wenliangdai/Multimodal-End2end-Sparse
数据集链接:https://hkustconnect-my.sharepoint.com/:u:/g/personal/wdaiai_connect_ust_hk/EbEzVnCduqVNuT_LvuRApVQBagraPx7nGqIEHgdnGPjN7g?e=zeMtct
论文框架:
论文数据集解读:
重组后的CMU-MOSEI数据集
- 参考论文?官网?建库团队?
参考论文:Multimodal End-to-End Sparse Model for Emotion Recognition
官网:https://sail.usc.edu/iemocap/
建库团队:Center for Artificial Intelligence Research (CAiRE)、Department of Electronic and Computer Engineering、The Hong Kong University of Science and Technology, Clear Water Bay, Hong Kong - 有几种模态?分别是哪些?给出示例图?模态间的对齐关系?
模态数量:3
模态:采样率为 44.1 kHz 的音频数据、文本副本和从视频中以 30 Hz 采样的图像帧 - 哪些标签?如何标注的?
6个情感类别:快乐、悲伤、愤怒、恐惧、厌恶和惊讶 - 如何得到这些数据集的?
在原数据的基础上做两处修改:
(1)执行数据清理以去除未对齐的样本,总共产生 20477 个剪辑
(2)在情感分类任务的 CMUMOSEI 拆分之后创建一个新的数据集拆分 - 数据集大小?单个视频时长?
数据集信息如下:
- 数据集内容topic
数据集一共包含6个主题(快乐、悲伤、愤怒、恐惧、厌恶和惊讶) - 建库年代?
2021年 - 被试
Github上29star,4fork
如何重组的?具体步骤要清楚。与原数据集有何区别?(见4)
重组后的IEMOCAP数据集
- 参考论文?官网?建库团队?
参考论文:Multimodal End-to-End Sparse Model for Emotion Recognition
官网:https://sail.usc.edu/iemocap/
建库团队:Center for Artificial Intelligence Research (CAiRE)、Department of Electronic and Computer Engineering、The Hong Kong University of Science and Technology, Clear Water Bay, Hong Kong - 有几种模态?分别是哪些?给出示例图?模态间的对齐关系?
模态数量:3
模态:采样率为 16 kHz 的音频数据、文本转录和从视频中以 30 Hz 采样的图像帧 - 哪些标签?如何标注的?
标签:愤怒、快乐、兴奋、悲伤、沮丧和中性
标注方式:人工标注者 - 如何得到这些数据集的?
在原数据的基础上,在三个方面进行修改:
(1)从原始九个情绪中选取了六个主要类别:愤怒、快乐、兴奋、悲伤、沮丧和中性。
(2)由于对话是在话语级别进行注释的,本文从提供的文本转录时间中剪裁了每个话语的数据,总共产生了 7380 个数据样本。
(3)现有工作中提供的预处理数据没有为每个数据样本提供标识符,这使得无法从原始数据中复制它。为了解决这个问题,本文通过将 70%、10% 和 20% 的数据分别随机分配到训练、验证和测试集来为数据集创建一个新的分割。 - 数据集大小?单个视频时长?
数据集信息如下:

- 数据集内容topic
数据集一共包含6个主题(愤怒、快乐、兴奋、悲伤、沮丧和中性) - 建库年代?
2021年 - 被试
Github上29star,4fork
**如何重组的?具体步骤要清楚。与原数据集有何区别?(见4)
论文翻译:
Multimodal End-to-End Sparse Model for Emotion Recognition
用于情感识别的多模态端到端稀疏模型
摘要
现有的多模态情感计算任务,如情感识别,一般采用两阶段流水线,首先用手工算法为每个单模态提取特征表示,然后用提取的特征进行端到端学习。 然而,提取的特征是固定的,不能在不同的目标任务上进一步微调,手动寻找特征提取算法不能很好地泛化或扩展到不同的任务,这可能导致次优的性能。 在本文中,我们开发了一个完全端到端的模型,将两个阶段连接起来并共同优化它们。 此外,我们重构了当前的数据集以实现完全端到端的训练。此外,为了减少端到端模型带来的计算开销,我们为特征提取引入了稀疏跨模态注意机制。 实验结果表明,我们的完全端到端模型显着超越了当前基于两阶段管道的最先进模型。此外,通过添加稀疏跨模态注意力,我们的模型可以在特征提取部分以大约一半的计算量保持性能。
1.引言
人类不仅通过他们使用的词,而且通过他们说话的方式和他们的面部表情来展示他们的特征。 因此,在情感识别等多模态情感计算任务中,通常存在三种模态:文本、声学和视觉。 这些任务的主要挑战之一是如何对不同模式之间的交互进行建模,因为它们包含补充和补充信息(Baltrušaitis 等,2018)。
在现有工作中,我们发现通常使用两相管道(Zadeh 等人,2018a,b;Tsai 等人,2018 年,2019 年;Rahman 等人,2020 年)。 在第一阶段,给定原始输入数据,使用手工算法分别为每个模态提取特征表示,而在第二阶段,使用提取的特征执行端到端的多模态学习。 但是,这种两阶段流水线存在三大缺陷:1)特征提取后是固定的,不能在目标任务上进一步微调; 2)针对不同的目标任务,需要手动搜索合适的特征提取算法; 3)手工制作的模型只考虑很少的数据点来表示更高级别的特征,这可能无法捕获所有有用的信息。 这些缺陷可能导致次优性能。
在本文中,我们提出了一个完全端到端的模型,将两个阶段连接在一起并共同优化它们。 换句话说,模型接收原始输入数据并生成输出预先词典,它允许通过端到端的训练自动学习特征。 然而,目前用于多模态情感识别的数据集不能直接用于完全端到端的训练,因此我们进行了数据重组以使这种训练成为可能。 端到端训练的好处是特征针对特定目标任务进行了优化,无需手动选择特征提取算法。 尽管端到端训练具有优势,但与两阶段流水线相比,它确实带来了更多的计算开销,并且详尽地处理所有数据点使其计算成本高昂且容易过拟合。因此,为了减轻这些副作用,我们还提出了一种多模态端到端稀疏模型,即稀疏跨模态注意机制和稀疏卷积神经网络 (CNN) 的组合(Graham 和 van der Maaten,2017 年), 为任务选择最相关的特征并减少视频和音频中的冗余信息和噪声。
实验结果表明,简单的端到端训练模型能够始终优于现有的基于两阶段管道的最先进模型。 此外,稀疏跨模态注意力和稀疏CNN的结合能够大大降低计算成本并保持性能。
我们总结了我们的贡献如下:
- 据我们所知,我们是第一个将完全端到端的可训练模型应用于多模态情感识别任务的。
- 我们重构了现有的多模态情感识别数据集,以实现基于原始数据的端到端训练和跨模态注意力。
- 我们表明完全端到端的训练显着优于当前最先进的两阶段模型,并且所提出的稀疏模型可以在保持端到端训练性能的同时大大减少计算开销。 我们还进行了彻底的分析和案例研究,以提高我们方法的可解释性。
2.相关工作
人类情感识别是一个流行且广泛研究的研究课题(Mirsamadi 等人,2017 年;张和刘,2017; 徐等人,2020; 戴等人,2020b)。 近年来,有一种趋势是利用多模态信息来解决这些研究任务,例如情绪识别 (Busso等, 2008)、情感分析 (Zadeh等, 2016, 2018b)、人格特质识别 (Nojavanasghari等,2016) 等,受到越来越多的关注。 已经提出了不同的方法来提高性能和跨模式交互。 在早期的工作中,模态的早期融合(Morency 等,2011;Pérez-Rosas 等,2013)和晚期融合(Zadeh 等,2016;Wang 等,2017)被广泛采用。后来,提出了更复杂的方法。例如,Zadeh等人(2017) 介绍了张量融合网络,通过执行笛卡尔积来模拟三种模态的相互作用,而 (Wang 等人,2019) 使用注意门来使用视觉和声学特征来移动单词。 此外,基于 Transformer(Vaswani 等人,2017),Tsai 等人(2019) 引入了 Multimodal Transformer 以提高给定未对齐多峰数据的性能,Rahman 等人(2020) 引入了一种多模态适应门,将视觉和声学信息整合到一个大型的预训练语言模型中。 然而,与使用完全端到端学习的其他一些多模态任务(Chen 等人,2017;Yu 等人,2019 年;Li 等人,2019 年)不同,所有这些方法都需要使用手动特征提取阶段. 精心设计的算法(详见第 5.2 节),这使得整个方法成为一个两阶段的流程。
3.数据集重组
完全端到端的多模态模型要求输入是三种模态(视觉、文本和声学)的原始数据。 由于两个主要原因,现有的多模态情感识别数据集不能直接应用于完全端到端的训练。 首先,数据集为手工制作的特征提供训练、验证和测试数据的分割作为模型的输入,情感或情感标签作为模型的输出。 但是,此数据集拆分无法直接映射到原始数据,因为拆分索引无法与原始数据匹配。 其次,数据样本的标签与文本模态对齐。 然而,视觉和听觉模态与原始数据中的文本模态不一致,这使得完全端到端训练。 为了使现有数据集可用于完全端到端的训练和评估,我们需要根据两个步骤对其进行重组:1)对齐文本、视觉和声学模态; 2) 将对齐的数据拆分为训练、验证和测试集。
在这项工作中,我们重组了两个情绪识别数据集:交互式情绪二元运动捕捉 (IEMOCAP) 和 CMU 多模态观点情绪和情绪强度 (CMUMOSEI)。两者都有用于多模态情感识别的多类和多标记数据,通过生成原始话语级数据、对齐三种模态并在对齐的数据上创建新的分割来获得。 在下一节中,我们将首先介绍现有的数据集,然后我们将详细描述我们如何重新组织它们。
3.1 IEMOCAP
IEMOCAP (Busso et al., 2008) 是一个包含 151 个视频的多模态情感识别数据集。在每个视频中,两位专业演员用英语进行二元对话。 该数据集由九个情绪类别标记,但由于数据不平衡问题,我们选取了六个主要类别:愤怒、快乐、兴奋、悲伤、沮丧和中性。 由于对话是在话语级别进行注释的,我们从提供的文本转录时间中剪裁了每个话语的数据,总共产生了 7380 个数据样本。 每个数据样本由三种模式组成:采样率为 16 kHz 的音频数据、文本转录和从视频中以 30 Hz 采样的图像帧。现有工作中提供的预处理数据 (Busso et al., 2008) 没有为每个数据样本提供标识符,这使得无法从原始数据中复制它。 为了解决这个问题,我们通过将 70%、10% 和 20% 的数据分别随机分配到训练、验证和测试集来为数据集创建一个新的分割。 我们的分割数据集的统计数据如表 1 所示。
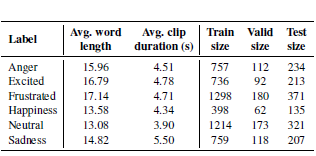
表 1: IEMOCAP 数据集拆分的统计数据。
3.2 CMU-MOSEI
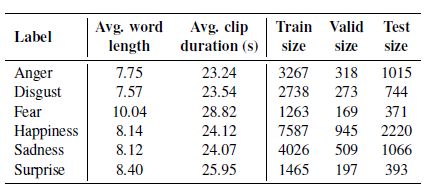
CMU-MOSEI (Zadeh et al., 2018b) 来自 1000 个不同说话者的 3837 个视频,具有六种情感类别:快乐、悲伤、愤怒、恐惧、厌恶和惊讶。在话语级别进行注释,总共 23259样本。CMU-MOSEI 中的每个数据样本由三种模态组成:采样率为 44.1 kHz 的音频数据、文本副本和从视频中以 30 Hz 采样的图像帧。 我们从可公开访问的原始 CMU-MOSEI 数据集生成话语级数据。生成的话语与现有工作(Zadeh 等人,2018b)的预处理数据完美匹配,但现有数据集存在两个问题:1)包含许多未对齐的数据样本; 2) 许多样本不存在于生成的数据中,反之亦然,在从 CMU MultiModal SDK 提供的标准拆分中。为了解决第一个问题,我们执行数据清理以去除未对齐的样本,总共产生 20477 个剪辑。 然后,我们在情感分类任务的 CMUMOSEI 拆分之后创建一个新的数据集拆分。新数据集拆分设置的统计数据如表 2 所示。

表 2:CMU-MOSEI 数据集拆分的统计数据。
4.方法论
4.1 问题定义
我们将 I I I多模态数据样本定义为 X = { ( t i , a i , v i ) } i = 1 I X = {\{(t_i,a_i,v_i)\}}_{i =1}^I X={(ti,ai,vi)}i=1I,其中 t i t_i ti 是单词序列, a i a_i ai 是来自音频, v i v_i vi 是视频中的 RGB 图像帧序列。 Y = { y i } i = 1 I Y = {\{y_i\}}_{i=1}^I Y={yi}i=1I表示每个数据样本的注释。
4.2 完全端到端的多模态建模
我们构建了一个完全端到端的模型,它联合优化了两个独立的阶段(特征提取和多模态建模)。
对于视觉和声学模式中的每个频谱块和图像帧,我们首先使用预训练的 CNN 模型(11层VGG(Simonyan 和 Zisserman,2014)模型)来提取输入特征,然后将其展平为向量使用线性变换表示。 之后,我们可以获得视觉和声学模式的一系列表示。 然后,我们使用 Transformer (Vaswani et al., 2017) 模型对顺序表示进行编码,因为它包含位置嵌入来对时间信息进行建模。最后,我们在“CLS”标记处获取输出向量并应用前馈网络(FFN)来获得分类分数。
此外,为了减少 GPU 内存并与从人脸提取视觉特征的两阶段基线对齐,我们使用 MTCNN (Zhang et al., 2016) 模型来获取图像帧的人脸位置,然后再将它们输入 VGG。 对于文本模态,直接使用 Transformer 模型来处理单词序列。 与视觉和声学模态类似,我们考虑在“CLS”标记作为输出特征并将其输入 FFN 以生成分类分数。 我们对每个模态的分类分数进行加权求和,以得出最终的预测分数。
4.3 多模态端到端稀疏模型
虽然完全端到端模型相对于两阶段流水线有很多优势,但也带来了很大的计算开销。 为了在不降低性能的情况下减少这种开销,我们引入了多模态端到端稀疏模型 (MESM)。 图 2 展示了 MESM 的整体架构。 与完全端到端模型相比,我们用 N 个跨模态稀疏 CNN 块替换了原始 CNN 层(除了第一个用于低级特征捕获的层)。 一个跨模态稀疏 CNN 块由两部分组成,一个跨模态注意力层和一个包含两个稀疏 VGG 层和一个稀疏最大池化层的稀疏 CNN 模型。
 图 2:我们的多模态端到端稀疏模型 (MESM) 的架构。 在左边,我们展示了一般的架构流程。 在中间和右侧,我们展示了跨模态稀疏 CNN 块的细节,尤其是跨模态注意力层,这是使 CNN 模型稀疏的关键。
图 2:我们的多模态端到端稀疏模型 (MESM) 的架构。 在左边,我们展示了一般的架构流程。 在中间和右侧,我们展示了跨模态稀疏 CNN 块的细节,尤其是跨模态注意力层,这是使 CNN 模型稀疏的关键。
4.3.1 跨模态注意力层
跨模态注意力层接受两个输入:一个查询向量 q ∈ R d q \in \mathbb{R}^d q∈Rd和一堆特征图 M ∈ R C ∗ S ∗ H ∗ W M\in \mathbb{R}^{C*S*H*W} M∈RC∗S∗H∗W,其中 C C C, S S S, H H H和 W W W分别是通道数、序列长度、高度和宽度。 然后,使用查询向量对特征图执行跨模态空间注意。 跨模态空间注意力可以通过以下步骤进行公式化:
M q = t a n h ( ( W m M + b m ) ⊕ W q q ) (1) M_q = tanh((W_mM+b_m)\oplus W_qq)\tag{1} Mq=tanh((WmM+bm)⊕Wqq)(1)
M i = s o f t m a x ( W i M q + b i ) (2) M_i = softmax(W_iM_q+b_i)\tag{2} Mi=softmax(WiMq+bi)(2)
M n s = N u c l e u s S a m p l i n g ( M i ) (3) M_{ns}=Nucleus Sampling(M_i)\tag{3} Mns=NucleusSampling(Mi)(3)
M o = M n s ⊕ M (4) M_o = M_ns\oplus M\tag{4} Mo=Mns⊕M(4)
其中 M m ∈ R k ∗ C M_m\in \mathbb{R}^{k*C} Mm∈Rk∗C、 M q ∈ R k ∗ d M_q\in \mathbb{R}^{k*d} Mq∈Rk∗d和 M i ∈ R k M_i\in \mathbb{R}^{k} Mi∈Rk是线性变换权重, b m ∈ R k b_m\in \mathbb{R}^{k} bm∈Rk和 b i ∈ R I b_i\in \mathbb{R}^{I} bi∈RI是偏差,其中 k k k是预定义的超参数, ⊕ \oplus ⊕代表广播张量和向量的加法运算。 在Eq.2中,softmax函数应用于(H W)维度, M i ∈ R S ∗ H ∗ W M_i\in \mathbb{R}^{S*H*W} Mi∈RS∗H∗W是每个特征图对应的空间注意力分数的张量。最后,为了在保留重要信息的同时使输入特征图 M M M稀疏,首先,我们对 M i M_i Mi 执行 Nucleus Sampling (Holtzman等, 2019) 以获得每个注意力得分图中概率质量的 top- p p p 部分( p p p 是 一个在 (0; 1] 范围内的预定义超参数。在 M n s M_{ns} Mns 中,核采样选择的点设置为 1,其他点设置为零。然后,我们在之间进行广播逐点乘法 M n s M_{ns} Mns和 M M M 生成输出 M o M_o Mo。因此, M o M_o Mo 是一个稀疏张量,某些位置为零,稀疏程度由 p p p 控制。
4.3.2 稀疏 CNN
我们在跨模式注意层之后使用子流形稀疏 CNN(Graham 和 van der Maaten,2017)。 它用于处理位于高维空间中的低维数据。 在多模态情感识别任务中,我们假设只有部分数据与情感识别相关(图 1 给出了一个直观的例子),这使得它与稀疏设置保持一致。 在我们的模型中,稀疏 CNN 层接受来自 crossmodal attention 层的输出,并且仅在活动位置进行卷积计算。 理论上,就单个位置的计算量(FLOPs)而言,标准卷积需要 z2mn FLOPs,稀疏卷积需要 a m n amn amnFLOPs,其中 z z z是内核大小, m m m 是输入通道数, n n n是 输出通道数, a a a是该位置的活动点数。 因此,考虑到所有位置和所有层,稀疏 CNN 可以帮助显着减少计算量。
5.实验
5.1 评估指标
根据先前的工作(Tsai 等人,2018;Wang 等人,2019;Tsai 等人,2019;Dai 等人,2020a),在 IEMOCAP 数据集上,我们使用准确性和 F1 分数来评估模型。 在 CMUMOSEI 数据集上,我们使用加权精度而不是标准精度。 此外,根据 Dai 等(2020a)的说法,我们使用标准二进制F1而不是加权版本。
加权精度:与现有工作(Zadeh 等人,2018b;Akhtar 等人,2019 年)类似,我们使用加权精度(WAcc)(Tong 等人,2017 年)来评估 CMU-MOSEI 数据集,其中包含更多 在每个情感类别上,负样本多于正样本。 如果使用正常精度,模型在预测所有样本为负时仍然会得到很好的分数。 加权精度的公式为
W A c c . = T p ∗ N / P + T N T N WA_{cc.}=\frac{Tp*N/P+TN}{TN} WAcc.=TNTp∗N/P+TN
其中P表示总阳性,TP真阳性,N总阴性,TN真阴性。
5.2 基线
对于我们的基线,我们使用两阶段管道,它由特征提取步骤和端到端学习步骤组成。
特征提取:我们遵循之前作品中的特征提取程序(Zadeh 等人,2018b;Tsai 等人,2018 年,2019 年;Rahman 等人,2020 年)。 对于视觉数据,我们使用 OpenFace 库 (Baltrušaitis 等人,2015 年;Baltrusaitis 等人,2018 年)为视频中的图像帧提取了 35 个面部动作单元(FAU),用于捕捉面部肌肉的运动(Ekman 等人,1980 年)。 对于声学数据,我们提取了总共 142 维特征,包括 12 维树bark band energy(BBE) 特征、22 维梅尔频率倒谱系数 (MFCC) 特征和来自 18 个语音类别的 108 个统计特征。 我们使用 DisVoice 库 (Vásquez-Correa 等人,2018 年,2019 年)提取每 400 毫秒时间帧的特征。 对于文本数据,我们使用预训练的GloVe (Pennington et al., 2014) 词嵌入 (glove.840B.300d)。
多模态学习:由于不同的模态在数据中是未对齐的,我们无法将我们的方法与只能处理对齐输入数据的现有工作进行比较。 我们使用四种多模态学习模型作为基线:后期融合 LSTM (LF-LSTM) 模型、后期融合变换器 (LF-TRANS) 模型、情感嵌入 (EmoEmbs) 模型 (Dai et al., 2020a) 和 Multimodal Transformer (MulT) 模型(Tsai 等人,2019 年)。 他们接收从第一步中提取的手工特征作为输入并给出分类决策。
5.3 训练细节
我们使用 Adam 优化器(Kingma 和 Ba,2014)来训练我们使用的每个模型。 对于损失函数,我们使用二元交叉熵损失,因为这两个数据集都是多类和多标签的。此外,正样本的损失由正负样本数量的比率加权,以减轻不平衡问题。 对于所有模型,我们执行详尽的超参数搜索以确保我们进行可靠的比较。 最佳超参数在附录 A 中报告。我们的实验在 Nvidia 1080Ti GPU 上运行,我们的代码在 PyTorch (Paszke et al., 2019) 框架 v1.6.0 中实现。 我们对文本和音频模式进行预处理。 对于文本模态,我们对基线执行单词标记化,并为端到端模型执行子词标记化。我们将文本的长度限制为最多 50 个标记。对于音频模态,我们使用窗口大小为 25 毫秒、步幅为 12.5 毫秒的梅尔频谱图,然后每 400 毫秒时间窗口对频谱图进行分块。
6.分析
6.1 结果分析
在表 3 中,我们展示了在 IEMOCAP 数据集上的结果。 与基线相比,完全端到端 (FE2E) 模型在所有评估指标上都大大超过了它们。 从经验上看,这表明 FE2E 模型优于两相管道。 此外,我们的 MESM 获得了与 FE2E 模型相当的结果,同时在特征提取中需要的计算量要少得多。 在这里,我们仅显示具有最佳核采样 p 值的 MESM 的结果。在 6.3 节中,我们对 top-p 值的影响进行了更详细的讨论。 我们进一步评估了 CMU-MOSEI 数据集上的方法和结果如表 4 所示。我们在这个数据集上观察到类似的趋势。
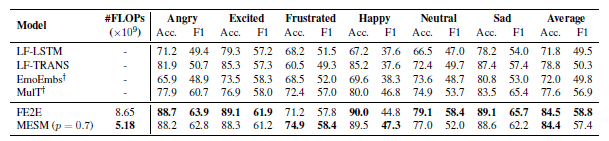
表 3:IEMOCAP 数据集的结果。 #FLOPs 是每秒浮点运算次数。 我们报告了六种情绪类别的准确性 (Acc.) 和 F1 分数:愤怒、兴奋、沮丧、快乐、中立和悲伤。 我们重新运行由 † \dag †标记的模型,因为我们使用了另外两个类别并且分割不同。
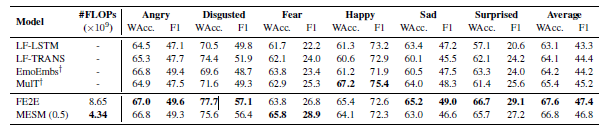
表 4:CMU-MOSEI 数据集的结果。 WAcc 代表加权精度。 我们报告了六种情绪类别的准确性和 F1 分数:愤怒、厌恶、恐惧、快乐、悲伤和惊讶。 我们重新运行由 † \dag †标记的模型,因为我们使用的数据沿序列长度维度未对齐并且拆分不同。
6.2 案例研究
为了提高可解释性并从我们的模型中获得更多见解,我们将稀疏跨模态注意力机制的注意力图可视化为六种基本情绪:快乐、悲伤、愤怒、惊讶、恐惧和厌恶。 如图 3 所示,一般来说,模型会关注几个感兴趣的区域,例如嘴巴、眼睛、眉毛以及嘴巴和眼睛之间的面部肌肉。 我们通过比较我们的模型基于面部动作编码系统(FACS)(Ekman,1997)捕获的区域来验证我们的方法。 在将 FACS 映射到人类情感类别(Basori,2016 年;Ahn 和 Chung,2017 年)之后,我们进行了实证分析以验证对每个情感类别的稀疏跨模态注意力。例如,快乐的情绪受双唇上扬的影响很大,而悲伤则与双唇下垂和眼睑向下运动有关。 愤怒是由缩小的眼睛之间的缝隙和变薄的嘴唇决定的,而惊讶是通过张开嘴和扬起眉毛和眼睑来表达。 恐惧表现为眉毛和上眼睑的隆起,以及张开的嘴巴,嘴唇的末端略微向脸颊移动。对于厌恶情绪,鼻子附近的皱纹和上唇区域的运动是决定因素。

图 3:MESM 对六种基本情绪类别(快乐、悲伤、愤怒、惊讶、恐惧、厌恶)的案例研究。从左到右,我们在每个注意力层中的点上显示原始图像和核采样 ( p = 0.6 p = 0.6 p=0.6) 结果。 红色区域表示为下一层计算的点。
基于图 3 中视觉数据上注意力图的可视化,MESM 可以捕获六个情感类别的大部分指定感兴趣区域。 对于愤怒的情绪,稀疏的跨模态注意力可以很好地检索唇部区域的特征,但有时无法捕捉到眼睛之间的间隙。 令人惊讶的是,MESM 可以成功捕获眼睑和嘴巴区域,但有时模型未能考虑眉毛区域。对于声学模态,很难根据情感标签来分析注意力。 我们展示了图 4 中音频数据上注意力图的一般可视化。该模型关注早期注意力层中具有高频谱值的区域,经过进一步的跨模态注意力层后过滤掉更多的点。 附录 B 中提供了更多可视化示例。
 图 4:声学模态跨模态注意力的可视化。 我们只在每个图像中显示最高 10% 的 mel-spectrogram 值。 从左到右,我们在每个注意力层中的点上显示原始图像和核采样 ( p = 0.6 p = 0.6 p=0.6) 结果。红色区域代表将进入下一个稀疏 CNN 层的活动点。
图 4:声学模态跨模态注意力的可视化。 我们只在每个图像中显示最高 10% 的 mel-spectrogram 值。 从左到右,我们在每个注意力层中的点上显示原始图像和核采样 ( p = 0.6 p = 0.6 p=0.6) 结果。红色区域代表将进入下一个稀疏 CNN 层的活动点。
6.3 核采样的影响
为了深入了解核采样对 MESM 的影响,我们使用从 0 到 1 的不同 top-p 值进行了更多的实验,步长为 0.1。如图 5 所示,根据经验,计算量随着 top-p 值的减少而不断减少。 在性能方面,top-p 值从 0.9 到 0.5,评估性能没有明显下降。 从 0.5 到 0.1,我们可以看到性能明显下降,这意味着一些对识别情绪有用的信息被排除在外。 这条肘形趋势线的拐点可以作为一个指标,帮助我们对 top-p 的值做出决定。 具体来说,在 top-p 为 0.5 的情况下,MESM 可以实现与 FE2E 模型相当的性能,在特征提取中使用大约一半的 FLOP。
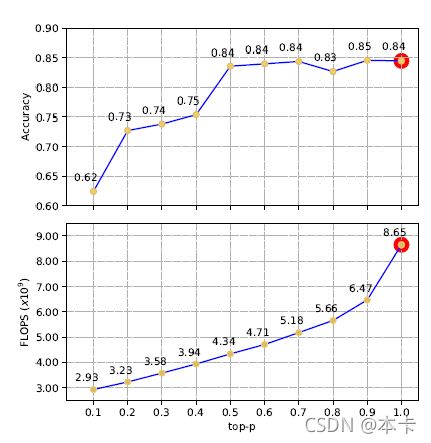 图 5:MESM 的顶部:加权精度和底部:FLOPs (x109)) 的趋势线,在 Nucleus Sampling 中使用了不同的 top-p 值。黄点代表 MESM 的性能,而红点代表 FE2E 模型的性能
图 5:MESM 的顶部:加权精度和底部:FLOPs (x109)) 的趋势线,在 Nucleus Sampling 中使用了不同的 top-p 值。黄点代表 MESM 的性能,而红点代表 FE2E 模型的性能
7.消融研究
我们进行了全面的消融研究,以进一步研究模型在缺少一种或多种模态时的表现。 结果如表 5 所示。首先,我们观察到模态越多,性能的提高就越多。TAV 代表所有三种模态的存在,导致两种模型的最佳性能,这表明拥有更多模态的有效性。 其次,仅使用单一模态,文本模态的性能优于其他两种,这与之前多模态作品的结果相似。 这种现象进一步验证了在我们的跨模式注意机制中使用文本 (T) 来关注声学 (A) 和视觉 (V) 是一个合理的选择。最后,通过两种模态,MESM 仍然可以实现与 FE2E 模型相当甚至更好的性能。

表 5:我们的完全端到端模型 (FE2E) 和多模态端到端稀疏模型 (MESM) 在 IEMOCAP 数据集上的消融研究结果。 在模组中。 (模态)列中,T/A/V 表示文本 (T)、声学 (A) 和视觉 (V) 模态的存在。
8.结论和未来工作
在本文中,我们首先比较和对比多模态情感识别任务的两阶段管道和完全端到端(FE2E)建模。 然后,我们提出了我们新颖的多模态端到端稀疏模型(MESM)来减少完全端到端模型带来的计算开销。 此外,我们重组了两个现有的数据集,以实现完全端到端的训练。实证结果表明FE2E模型在特征学习方面具有优势并超越了当前基于两阶段管道的最先进模型。 此外,与 FE2E 相比,MESM 能够将特征提取部分的计算量减半,同时保持其性能。 在我们的案例研究中,我们提供了视觉和声学数据上的交叉模式注意力图的可视化。 这表明我们的方法是可解释的,跨模态注意力可以根据不同的情感类别成功选择重要的特征点。 对于未来的工作,我们认为将更多模态纳入稀疏跨模态注意机制值得探索,因为它可能会增强稀疏性(特征选择)的鲁棒性。
致谢
这项工作由香港特别行政区政府创新科技委员会的 MRP/055/18 资助。