双系统装完ubuntu16.04后的一系列工作+部署深度学习开发环境
安装完Ubuntu16.04就开始捣鼓该如何进行深度学习了。在此之前还需要经历以下过程:
1、更换国内镜像源
安装完Ubuntu 系统后第1件事就是更换为国内源:
我试过了阿里云不行,中科大可!
解决方法:[judygeng] sudo apt-get update 报错 ubuntu xenial InRelease 明文签署文件不可用,结果为‘NOSPLIT’(您的网络需要认证吗?)解决
2、更新软件列表
输入
sudo apt-get update
不更新的话可能下不了软件包
3、安装中文输入法
我最先开始下谷歌拼音,发现好难用不习惯,最后还是下了个搜狗
参考:
Ubuntu16.04系统安装搜狗输入法详细教程
4、安装vim
因为gedit修改文件时会出现warning,用vim打开文件就没事
参考:
(gedit:20620): WARNING **: Set document metadata failed: Setting
但是我发现虽然用gedit编辑文件会出现warning,但它好用啊!可以直接复制粘贴,也能鼠标定位。vim就很难了。所以就算装了vim我还是没用╮(╯_╰)╭
※※※部署深度学习环境
最近在学目标检测,看到了一本书《MXNext深度学习实战》,里面讲得超级详细,从一开始的环境配置到最后的实战都写得清清楚楚。所以以下配置都和书里面的内容基本一致。
其实我本来是打算用tensorflow框架的,但书本说MXNext框架也很好,而且各种操作真的写得很详细,我跟着一步步做就不怕出现太大的问题。
这十多天来我用win10,caffe、tensorflow框架想跑网上目标检测的demo没一个成功的!!环境配置搞得我头都大。各种版本要对应好,从github上download下来的有些还需要自己配置编译,这又要用到vs,cmake。真真真的缺太多东西了,所以最后我只能装个双系统用Ubuntu16.04了。我太难了。
这里是用Pycharm+Docker搭建的深度学习环境。
Docker是一个环境隔离工具,采用这种方式不用安装CUDA,cuDNN,MXNet,只需安装Docker,然后通过Docker这个工具从镜像(image)库中拉取对于版本镜像就可以直接使用了,这样就不需要每次都在本地安装。
接下来就开始配置吧~过程很曲折,结果很美好
1、安装驱动
1、在桌面左侧打开system settings
2、点击software&update

3、点击additional drivers,选择第一个,点击apply changes
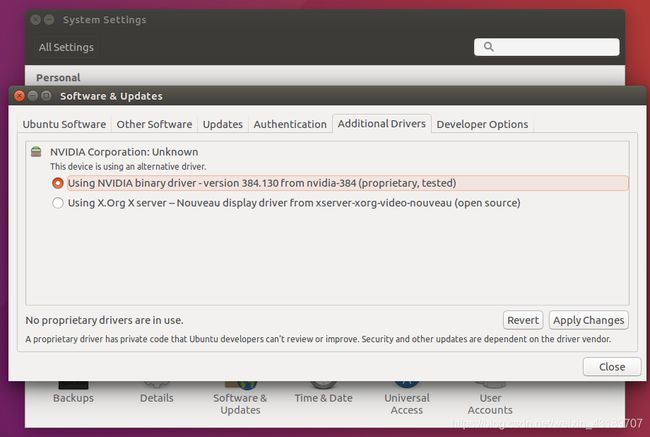
4、最后点击restart重启就可以了
2、下载pycharm专业版(2018.3.7)
官网:https://www.jetbrains.com/pycharm/download/other.html
安装方法参考:
Ubuntu下安装Pycharm专业版并激活
专业版需要花费,学生党暂没经费,所以就在网上找了激活码。
亲测好用!!找了好久,只有这个行:
https://www.cnblogs.com/codehome/p/8342430.html
这里显示2021/2/19到期,过期后应该还可以用上面的链接获取新的激活码

3、下载安装Docker(版本18.03.1)
下载地址
选择docker-ce_18.03.1-ce-0~ubuntu_amd64.deb
 进入下载docker的文件夹,我的是默认下到了~/Downloads文件夹下
进入下载docker的文件夹,我的是默认下到了~/Downloads文件夹下
所以输入以下命令:
cd ~/Downloads
再输入:
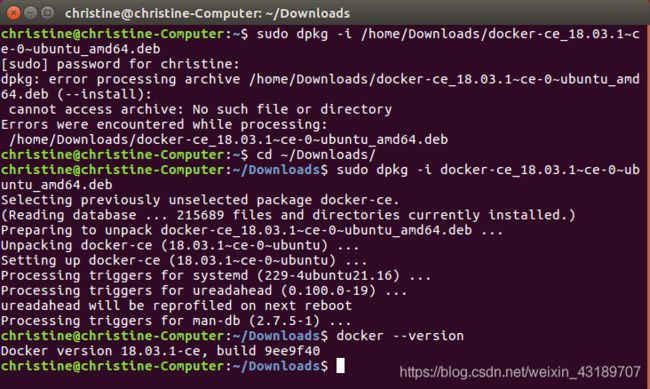
sudo -dpkg -i docker-ce_18.03.1~ce-0~ubuntu_amd64.deb
验证Docker是否安装成功:
docker --version
出现Docker version 18.03.1-ce, build 9ee9f40 就说明成功了
4、安装NVIDIA-docker
接下来的操作都是以root用户进行,否则可能会出现一些问题。
切换root时我遇到了一个问题,解决方法:
linux使用su切换用户提示 Authentication failure的解决方法
1、先安装curl:
curl是一个命令行工具,通过指定的URL来上传或下载数据,并将数据展示出来。
apt install curl
2、添加gpg key并创建一个仓库:
先输入:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | apt-key add -
出现OK时再输入:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
再输入:
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | tee /etc/apt/sources.list.d/nvidia-docker.list
结果如下
![]()
最后再输入:
apt-get update
结果如下

3、安装nvidia-docker2
输入:
apt-get install -y nvidia-docker2
这里出现一个问题:
E: Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
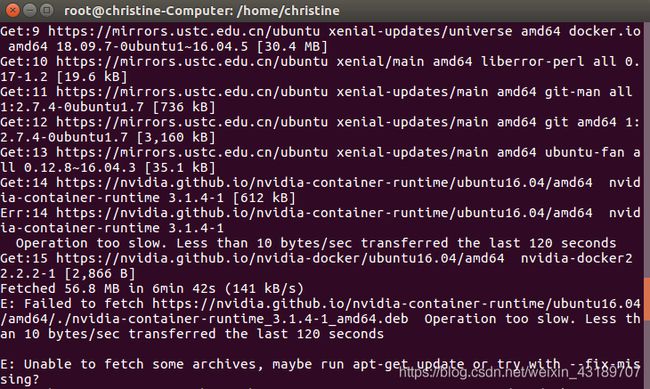
按照提示输入:
apt-get install -y nvidia-docker2 --fix-missing
就完美解决,如图:
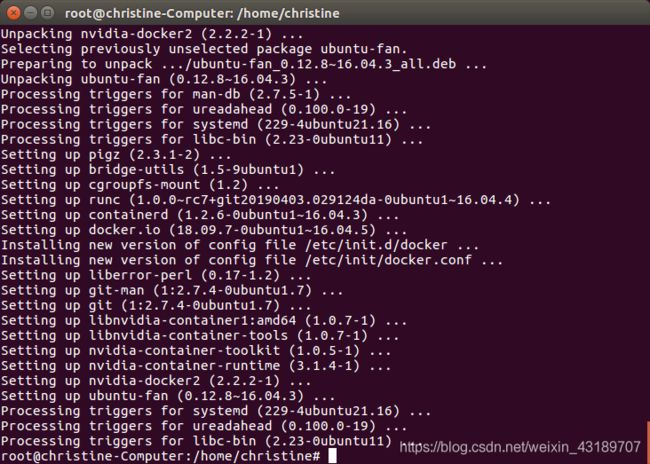
安装完成后需要重新导入Docker配置文件:
pkill -SIGHUP dockerd
4、测试
这里启动一个名为nvidia/cuda的镜像,如果机器中没有该镜像,那么run命令在启动前会自动拉取该镜像),然后在镜像中运行nvidia-smi命令,这条命令是用来查看显卡信息的。
输入:
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
这里又报错了:

解决方法参考:
[程序羊的自我修养 ]在执行Dockerfile时出现Get https://registry-1.docker.io/v2/错误的解决方案
我用的是以下解决方法:
修改docker镜像源:
docker默认的源为国外官方源,下载速度较慢,可改为国内源加速,我用了阿里云的
修改或新增配置文件,输入:
gedit /etc/docker/daemon.json
添加如下参数:逗号不要漏了
"registry-mirrors": ["https://aeckruos.mirror.aliyuncs.com"],

再重启一下docker服务:
systemctl daemon-reload
systemctl restart docker
解决了一个又来一个……
报错:

解决办法参考:nvidia-docker 安装报错记录
正确的命令是需要加上cuda的版本号:
docker run --runtime=nvidia --rm nvidia/cuda:8.0-devel nvidia-smi
在这个过程中因为有一些源不太行,下到最后一点总是报错报错报错,试了好几个源,最后只有改成阿里云才行,阿里云强!!!
搞定这个bug用了我好几个小时。终于可以了,既气又喜!
如果可以成功看到如下图所示的显卡信息就可以在镜像中使用GPU了。

5、修改配置文件
为了免得每次运行docker镜像时都要加上–runtime=nvidia这个参数,可以在配置文件中配置这个参数。
打开配置文件
gedit /etc/docker/daemon.json
添加
"default-runtime":"nvidia",
如下图所示:

保存文件,重启一下docker服务:
service docker restart
最后就可以使用以下命令在镜像中看到显卡驱动信息了:
docker run --rm nvidia/cuda:8.0-devel nvidia-smi
10、拉取MXNet镜像
接下来在镜像库中拉取MXNet镜像,Docker官方仓库提供了多种多样的MXNet镜像:
https://hub.docker.com/r/mxnet/
这里选择python api对应的mxnet/python。
在docker中可以通过docker pull命令来拉取镜像,镜像名的命名规则一般是”仓库名:标签“,比如”mxnet/python:gpu“,这里是按照《MXNet深度学习实战》这本书采用的是MXNet1.3.1、CUDA8.0和Python3.x,可以通过以下命令拉取镜像名为mxnet/python:1.3.1_gpu_cu80_py3的镜像:
这里也需要切换到root操作,开始时没有用root就报错了。
docker pull mxnet/python:1.3.1_gpu_cu80_py3
拉取镜像一般需要几分钟时间,如下图拉取成功。
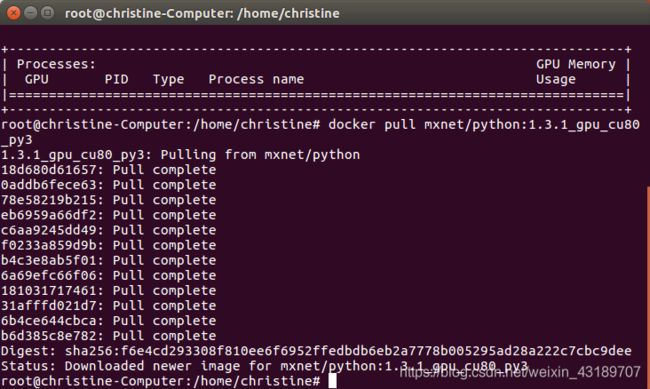
接下来通过docker的run命令进入指定镜像启动容器并开始一些简单的操作。
进入指定镜像:
docker run --rm -it mxnet/python:1.3.1_gpu_cu80_py3 bash
其中,”–rm“参数表示退出容器后自动删除该容器,”-it“参数表示指定镜像名称。
如果成功启动了容器,则命令行的前缀如下所示:
root@cc341fa59510:/#
符号@后面的字符串表示启动的容器的ID。
接下来的所有操作都会在这个容器环境中,不会影响机器环境。
然后通过输入
python3
进入python环境,在该镜像中默认使用python3.5.2
接着输入
import mxnet as mx
没有报错就可以正常使用mxnet了。
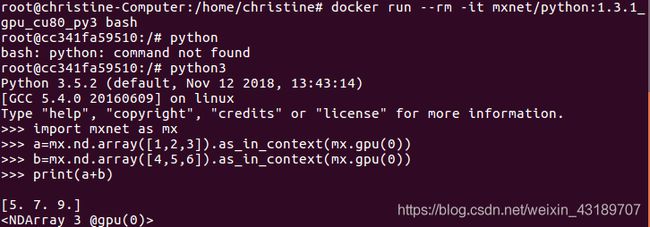
接下来可以执行一些简单的操作:
a=mx.nd.array([1,2,3]).as_in_context(mx.gpu(0))
b=mx.nd.array([4,5,6]).as_in_context(mx.gpu(0))
print(a+b)
以上操作如下图所示:
太兴奋啦!!!!搞了一天终于把环境搭建好了,接下来就可以好好跑模型了~
在某个环节出错了不要慌,网上有很多解决方法,一个不行试多几个,总有一个是可以的,不要放弃啊,想想成功后的欣喜,这一切都是值得的。