世界杯数据可视化分析
目录
1.数据来源
2.字段解释
世界杯成绩信息表:WorldCupsSummary
世界杯比赛比分汇总表:WorldCupMatches.csv
世界杯球员信息表:WorldCupPlayers.csv
3.数据分析及可视化
世界杯已经告一段落,作为一个学习大数据的学生,就像借此来做做分析玩,本次数据来源于天池大赛官网,大家可以去天池大赛官网自己下载,也可以通过我的网盘,链接放下面了。
1.数据来源
天池大赛官网链接:
https://tianchi.aliyun.com/competition/entrance/532045/information
百度网盘下载链接:
python源代码也放入进去了(现在只有一个表的分析,后面会更新剩下两个表的分析)
https://pan.baidu.com/s/1GuiqtTLCwdR-yfobdhnX6w?pwd=zytt 提取码:zytt
2.字段解释
世界杯成绩信息表:WorldCupsSummary
包含了所有21届世界杯赛事(1930-2018)的比赛主办国、前四名队伍、总参赛队伍、总进球数、现场观众人数等汇总信息,包括如下字段:
- Year: 举办年份
- HostCountry: 举办国家
- Winner: 冠军队伍
- Second: 亚军队伍
- Third: 季军队伍
- Fourth: 第四名队伍
- GoalsScored: 总进球数
- QualifiedTeams: 总参赛队伍数
- MatchesPlayed: 总比赛场数
- Attendance: 现场观众总人数
- HostContinent: 举办国所在洲
- WinnerContinent: 冠军国家队所在洲
世界杯比赛比分汇总表:WorldCupMatches.csv
包含了所有21届世界杯赛事(1930-2014)单场比赛的信息,包括比赛时间、比赛主客队、比赛进球数、比赛裁判等信息。包括如下字段:
- Year: 比赛(所属世界杯)举办年份
- Datetime: 比赛具体日期
- Stage: 比赛所属阶段,包括 小组赛(GroupX)、16进8(Quarter-Final)、半决赛(Semi-Final)、决赛(Final)等
- Stadium: 比赛体育场
- City: 比赛举办城市
- Home Team Name: 主队名
- Away Team Name: 客队名
- Home Team Goals: 主队进球数
- Away Team Goals: 客队进球数
- Attendance: 现场观众数
- Half-time Home Goals: 上半场主队进球数
- Half-time Away Goals: 上半场客队进球数
- Referee: 主裁
- Assistant 1: 助理裁判1
- Assistant 2: 助理裁判2
- RoundID: 比赛所处阶段ID,和Stage字段对应
- MatchID: 比赛ID
- Home Team Initials: 主队名字缩写
- Away Team Initials: 客队名字缩写
世界杯球员信息表:WorldCupPlayers.csv
- RoundID: 比赛所处阶段ID,同比赛信息表的RoundID字段
- MatchID: 比赛ID
- Team Initials: 队伍名
- Coach Name: 教练名
- Line-up: 首发/替补
- Shirt Number: 球衣号码
- Player Name: 队员名
- Position: 比赛角色,包括:C=Captain, GK=Goalkeeper
- Event: 比赛事件,包括进球、红/黄牌等
3.数据分析及可视化
在这里,我是对一个表一个表分析可视化来的,首先对世界杯成绩信息表:WorldCupsSummary进行分析。
我们先导入所需要用到的库
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts.charts import Map然后导入数据
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
df=pd.read_csv('WorldCupsSummary.csv',index_col=0)#将第一列作为索引列,即将时间作为索引
首先,我先分析进入半决赛的国家次数,夺冠次数,获得亚军次数,获得季军次数,获得第四名次数,由于给的数据都比较规则,不存在什么缺失值和异常值,故这里没怎么进行数据处理,但是在国家这里,国家名称存在着问题,如Germany FR 与Germany,这里需要对其进行合并,最终代码如下
#国家获得冠军数量
groupbyed=df.groupby(['Winner']).groups
for i in groupbyed :
groupbyed[i]=len(groupbyed[i])
groupbyed['Germany']=groupbyed['Germany FR']+groupbyed['Germany']#合并Germany与Germany FR
del groupbyed['Germany FR']
groupbyed=pd.DataFrame([groupbyed]).T
groupbyed.columns=['nums']
#获得亚军数量
Second=df.groupby('Second').groups
for i in Second :
Second[i]=len(Second[i])
Second['Germany']=Second['Germany FR']+Second['Germany']
del Second['Germany FR']
Second=pd.DataFrame([Second]).T
Second.columns=['nums']
#获得季军数
Third=df.groupby('Third').groups
for i in Third :
Third[i]=len(Third[i])
Third['Germany']=Third['Germany FR']+Third['Germany']
del Third['Germany FR']
Third=pd.DataFrame([Third]).T
Third.columns=['nums']
#第四名数
Fourth=df.groupby('Fourth').groups
for i in Fourth :
Fourth[i]=len(Fourth[i])
Fourth['Germany']=Fourth['Germany FR']
del Fourth['Germany FR']
Fourth=pd.DataFrame([Fourth]).T
Fourth.columns=['nums']
groupbyed.reset_index(inplace=True)
Second.reset_index(inplace=True)
Third.reset_index(inplace=True)
Fourth.reset_index(inplace=True)
groupbyed=pd.merge(groupbyed,Second,how='outer',on='index')
groupbyed=pd.merge(groupbyed,Third,how='outer',on='index')
groupbyed=pd.merge(groupbyed,Fourth,how='outer',on='index')
groupbyed.columns=['国家','冠军数','亚军数','季军数','第四名数']
groupbyed.fillna(0,inplace=True)
groupbyed['总数']=groupbyed['冠军数']+groupbyed['亚军数']+groupbyed['季军数']+groupbyed['第四名数']
groupbyed.sort_values(by='总数',inplace=True,ascending=False)
print(groupbyed)
c = (
Bar(init_opts=opts.InitOpts(width='1500px'))
.add_xaxis(list(groupbyed['国家']))
.add_yaxis("冠军数", list(groupbyed['冠军数']),category_gap='15%')
.add_yaxis("亚军数", list(groupbyed['亚军数']),category_gap='15%')
.add_yaxis("季军数", list(groupbyed['季军数']),category_gap='15%')
.add_yaxis("第四名数", list(groupbyed['第四名数']),category_gap='15%')
.add_yaxis('总数',list(groupbyed['总数']),category_gap='15%')
.set_global_opts(title_opts=opts.TitleOpts(title="按照获奖总数排序",pos_left='20%'),
xaxis_opts=opts.AxisOpts(name='国家',axispointer_opts={'interval':'0'},axislabel_opts=opts.LabelOpts(rotate=35,font_size=12)),
yaxis_opts=opts.AxisOpts(name='数量'),
legend_opts=opts.LegendOpts(textstyle_opts=opts.TextStyleOpts(font_size=15)))
.render("前四名.html")
)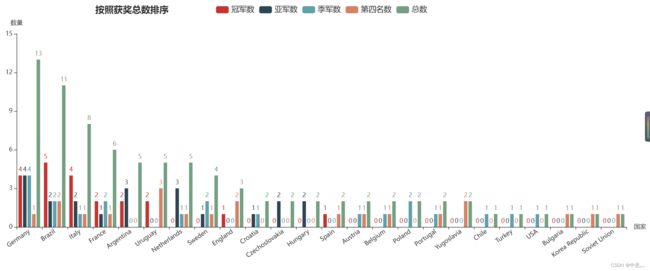
从上述可看出,进入半决赛最多的是德国队,其次就是巴西队、意大利队等,想不到韩国也进过半决赛,懂得都懂。
然后我们分析一下举办年份,按照四年一届世界杯,看看中间是否有过缺席
#统计未举办年份
Year=list(df.index)
count={}
for i in range(1930,2019,4):
count[str(i)]=Year.count(i)
count=pd.DataFrame([count]).T
count.columns=['是否举办']
print(count[count['是否举办']==0])
发现1942年和1946年未举办,估计这是由于正在打二战所导致的
然后我们统计分析一波,总进球数,总比赛场数,总参赛队伍数,并简单计算一下场均进球数
GoalsScored=df.loc[:,'GoalsScored']
changjun=np.array(GoalsScored)/np.array(df.loc[:,'MatchesPlayed'])
changjun=[round(i,1) for i in changjun]
# print(changjun)
bar = (
Bar(init_opts=opts.InitOpts(width='1500px'))
.add_xaxis(list(GoalsScored.index))
.add_yaxis("总进球数", GoalsScored.tolist(),category_gap='15%',z=0)
.add_yaxis('总参赛队伍数',list(df.loc[:,'QualifiedTeams']),category_gap='15%',z=0)
.add_yaxis("总比赛场数",list(df.loc[:,'MatchesPlayed']),category_gap='15%',z=0)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axispointer_opts={'interval':'0'},axislabel_opts=opts.LabelOpts(rotate=35,font_size=12),name='Time'),
yaxis_opts=opts.AxisOpts(name='Numbers'),
legend_opts=opts.LegendOpts(textstyle_opts=opts.TextStyleOpts(font_size=15))))
line=(
Line(init_opts=opts.InitOpts(width='1500px'))
.add_xaxis(GoalsScored.index.tolist())
.add_yaxis("场均进球数",y_axis=changjun,is_smooth=True,is_symbol_show=True)
.set_global_opts(title_opts=opts.TitleOpts(title="折线图-基本示例"))
)
bar.overlap(line)
bar.render('场均进球.html')
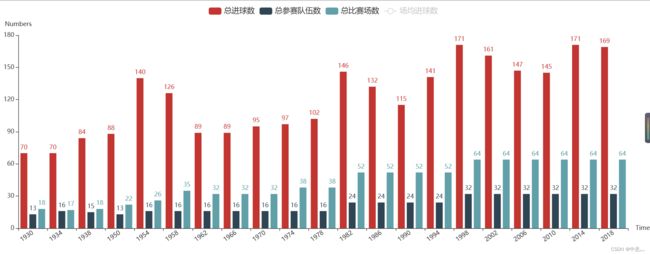
 可看出参赛队伍从1930年的13支增加到了18年的32支,这么多支队伍,中国都进不去啧啧啧,参赛队伍的增加,导致了总进球数和比赛场次的增加,但54年和58年像是个意外,队伍不多,进的球还不少,难不成刚二战结束,踢球都带有民族情绪,而场均进球数,从1930年到2018年呈下降趋势,这可能与早期足球参赛队伍少,比赛场次少有关吧,数量少了,偶然性就大嘛,而54年的场均进球数最高,平均每场都得进5、6个,搞得我还去百度了一下54年世界杯发生啥了,踢的这么激烈。
可看出参赛队伍从1930年的13支增加到了18年的32支,这么多支队伍,中国都进不去啧啧啧,参赛队伍的增加,导致了总进球数和比赛场次的增加,但54年和58年像是个意外,队伍不多,进的球还不少,难不成刚二战结束,踢球都带有民族情绪,而场均进球数,从1930年到2018年呈下降趋势,这可能与早期足球参赛队伍少,比赛场次少有关吧,数量少了,偶然性就大嘛,而54年的场均进球数最高,平均每场都得进5、6个,搞得我还去百度了一下54年世界杯发生啥了,踢的这么激烈。
接着咱们看看世界杯现场观众数量的变化
people=[round(i,2) for i in df.loc[:,'Attendance']/10000]
c = (
Line(init_opts=opts.InitOpts(width='1150px'))
.add_xaxis(df.index.tolist())
.add_yaxis("现场观众总人数", people, is_smooth=True,
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkLineItem(type_='max',symbol_size = [80,50],name='max'),opts.MarkLineItem(type_='min',symbol_size = [80,50],name='min')]))
.set_global_opts(
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),
xaxis_opts=opts.AxisOpts(
name='Time',
type_="category",
axispointer_opts=opts.AxisPointerOpts(is_show=False, type_="shadow"),
),
yaxis_opts=opts.AxisOpts(
name='numbers(10000)'
))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False)
)
.render("现场观众总人数.html")
) 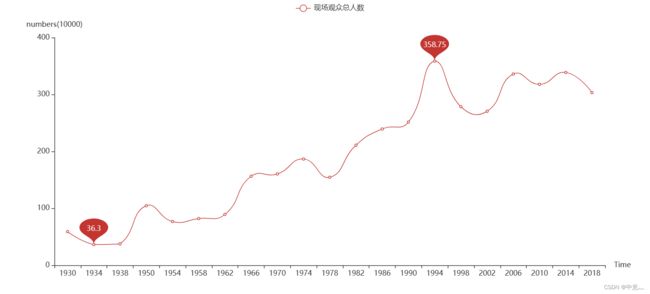
世界杯现场观众数整体是上升的,从最初只有60万人到2018年有303万人现场观看,上涨了近5倍,其中在1934年现场人数最少,只有36万人左右,可能是要打仗了吧=-=,而在1994年,现场人数最多,达到了358万人,是在美国所举办=-=。但我估计今年卡塔尔世界杯可能会破新高。
然后我们分析一下哪些国家举办国世界杯的吧,这里队日本和韩国的数据要处理一下,他们联合举办,就当他们都举办过的吧=-=,当然这里的德国和联邦德国依旧合并,而这里的USA需要更改为United States,England 也需要更改,不然Map画不出来=-=。
HostCountry=df.groupby(df.loc[:,'HostCountry']).groups
for i in HostCountry:
HostCountry[i]=len(HostCountry[i])
HostCountry['Korea']=1
HostCountry['Japan']=1
del HostCountry['Korea/Japan']
HostCountry['United States']=HostCountry['USA']
del HostCountry['USA']
HostCountry['United Kingdom']=HostCountry['England']
del HostCountry['England']
HostCountry=[[i,HostCountry[i]] for i in HostCountry]
c=(
Map(init_opts=opts.InitOpts(width='1150px'))
.add(
series_name="举办国家",
data_pair=HostCountry,
maptype="world",
)
# 全局配置项
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(title="世界地图"),
# 设置标准显示
visualmap_opts=opts.VisualMapOpts(max_=2, is_piecewise=False),
)
# 系列配置项
.set_series_opts(
# 标签名称显示,默认为True
label_opts=opts.LabelOpts(is_show=False, color="blue"),showLegendSymbol=False
)
# 生成本地html文件
.render("世界地图.html")
)
只能说有的国家都举办二轮了,有的国家连一轮都没举办过 ,当然这和地区经济也有关,可以看在亚洲举办的次数最少,在欧洲举办的次数是最多的,像墨西哥,巴西,法国等都举办了两次了。
然后再看看夺冠国家的分布吧,这里英国的名字需要自己修改一下,不如又识别不了
Winner=df.groupby(['Winner']).groups
for i in Winner :
Winner[i]=len(Winner[i])
Winner['Germany']=Winner['Germany FR']+Winner['Germany']
del Winner['Germany FR']
Winner['United Kingdom']=Winner['England']
del Winner['England']
Winner=[[i,Winner[i]] for i in Winner]
# Winner.columns=['nums']
c=(
Map(init_opts=opts.InitOpts(width='1150px'))
.add(
series_name="夺冠国家",
data_pair=Winner,
maptype="world",
)
# 全局配置项
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(title="世界地图"),
# 设置标准显示
visualmap_opts=opts.VisualMapOpts(max_=5, is_piecewise=True),
)
# 系列配置项
.set_series_opts(
# 标签名称显示,默认为True
label_opts=opts.LabelOpts(is_show=False, color="blue"),showLegendSymbol=False
)
# 生成本地html文件
.render("夺冠国家分布.html")
)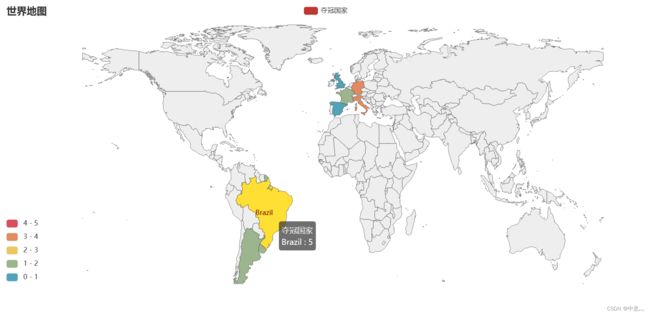
可以看出,巴西强呀,拿过五次冠军,德国也不弱呀,也拿了四次,整体来看,还是欧洲实力强劲,欧洲总共拿了12次冠军,剩下的就是南美洲拿了,其他洲呢呜呜呜,搞得像是个南美与欧洲的游戏似的。
然后我们开始分析第二个表,就是世界杯比赛比分汇总表:WorldCupMatches.csv这个表。
先导入模块,这里因为我是分呈两个py文件写的,所以我又导了一遍模块,这里说明一下吧,就没有具体的步骤是对数据进行清洗和处理的,因为数据原本已经很规整了,但里面一下国家名字需要处理,都在用到的时候进行处理,比如德国和联邦德国=-=。
import pandas as pd
from pyecharts import options as opts
import seaborn as sns
from pyecharts.charts import Bar,Pie
from pyecharts.charts import Line
import matplotlib.pyplot as plt还是要导入数据
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
df=pd.read_csv('WorldCupMatches.csv',index_col=0)#将第一列作为索引列,即将时间作为索引然后我先分析了一下主客场对的取胜有没有影响,这里我就统计了一下主客场胜率
主客队队比赛胜利的影响
#主场队胜
win=int(df[df.loc[:,'Home Team Goals']>df.loc[:,'Away Team Goals']].count()[0])
#平
draw=int(df[df.loc[:,'Home Team Goals']==df.loc[:,'Away Team Goals']].count()[0])
#主场队输
loss=int(df[df.loc[:,'Home Team Goals']

从中可以发现,主场优势是真实存在的,当作为主场方的,其胜率达到了58%,而客场的胜率只有20%,也确实是这样,以前在重庆看力帆打上海申花,全程都是一片红,只有一点蓝,然后加油的时候,申花傻逼直上云霄哇哈哈哈
然后统计一下在举办世界杯的年份中,未举办16强,半决赛,决赛等的年份,顺带统计一下这些比赛的场均观众人数吧
#统计一下小组赛,16进8,半决赛,决赛场均观众人数
df.loc[df['Stage'].str.contains('Group'),'Stage']='Group'
df.loc[df['Stage']=='First round','Stage']='Group'
df.loc[df['Stage']=='Preliminary round','Stage']='Group'
df.loc[df['Stage']=='Round of 16','Stage']='Quarter-finals'
df.loc[df['Stage']=='Third place','Stage']='Match for third place'
df.loc[df['Stage']=='Play-off for third place','Stage']='Match for third place'
Stage=list(set(df['Stage']))
Year=list(set(df.index))
Index={}
for i in Stage:
a=[]
for j in Year:
a.append((j,i))
Index[i]=a
groupbyed=df.groupby(['Year','Stage']).agg('mean')
Index=[list(i) for i in groupbyed.index]
Index.sort(key=lambda x: x[1])
Final=[]
Group=[]
Third=[]
Quarter=[]
Semi=[]
Index=[tuple(i) for i in Index]
for i in Index:
if i[1]=='Final':
Final.append(i)
elif i[1]=='Group':
Group.append(i)
elif i[1]=='Match for third place':
Third.append(i)
elif i[1]=='Quarter-finals':
Quarter.append(i)
else:
Semi.append(i)
Year=[i[0] for i in groupbyed.loc[Group,:].index]
Group=groupbyed.loc[Group,'Attendance']
Quarter=groupbyed.loc[Quarter,'Attendance']
data=pd.merge(Group,Quarter,how='outer',on='Year')
Semi=groupbyed.loc[Semi,'Attendance']
data=pd.merge(data,Semi,how='outer',on='Year')
Third=groupbyed.loc[Third,'Attendance']
data=pd.merge(data,Third,how='outer',on='Year')
Final=groupbyed.loc[Final,'Attendance']
data=pd.merge(data,Final,how='outer',on='Year')
data.columns=['小组赛','16进8','半决赛','季军赛','决赛']
for i in data.columns:
print('未举办'+i+"的年份:",list(data[data[i].isna()][i].index))
c = (
Line(init_opts=opts.InitOpts(width='1150px',height='550px'))
.add_xaxis(Year)
.add_yaxis("小组赛", data.iloc[:,0].tolist(), is_connect_nones=True,is_smooth=True)
.add_yaxis("16进8", data.iloc[:,1].tolist(), is_connect_nones=True,is_smooth=True)
.add_yaxis("半决赛", data.iloc[:,2].tolist(), is_connect_nones=True,is_smooth=True)
.add_yaxis("季军赛", data.iloc[:,3].tolist(), is_connect_nones=True,is_smooth=True)
.add_yaxis("决赛", data.iloc[:,4].tolist(), is_connect_nones=True,is_smooth=True)
.set_global_opts(title_opts=opts.TitleOpts(),
tooltip_opts=opts.TooltipOpts(is_show=True,axis_pointer_type= "cross",trigger="axis"),
xaxis_opts=opts.AxisOpts(name='Time'),
yaxis_opts=opts.AxisOpts(name='Numbers'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False),)
.render("不同比赛现场观众.html")
)

从中可以指导1950年没有举办决赛,为此我还去百度了一下,1950年巴西世界杯,真没有正式的决赛,当也还没有半决赛=-=,好像是中途有几个国家退出了,咱们也不知道。从场均现场观众数来看,基本都是决赛>季军赛>半决赛>16进8>小组赛,但在1986年的季军赛,谁打谁呀,观众少的可怜,百度一下,法国打比利时=-=,法国4:2比利时,但为什么没人看呢
然后统计分析一下球队的进球数,失球数吧
#统计球队历史总进球数,失球数
df.loc[df['Home Team Name'].str.contains('Germany'),'Home Team Name']='Germany'
df.loc[df['Away Team Name'].str.contains('Germany'),'Away Team Name']='Germany'
# print(df.loc[df['Home Team Name'].str.contains('German')])
inGoals=pd.DataFrame(df.groupby(['Home Team Name']).agg('sum')['Home Team Goals']+df.groupby(['Away Team Name']).agg('sum')['Away Team Goals'])
outGoals=pd.DataFrame(df.groupby(['Home Team Name']).agg('sum')['Away Team Goals']+df.groupby(['Away Team Name']).agg('sum')['Home Team Goals'])
inGoals.index.names=['Team Name']
outGoals.index.names=['Team Name']
Goals=pd.merge(inGoals,outGoals,how='inner',on='Team Name')
Goals['Total Goals']=Goals.iloc[:,0]+Goals.iloc[:,1]
Goals.columns=['inGoals','outGoals','Total Goals']
Goals=Goals.sort_values(by='Total Goals',ascending=False)
Goals.fillna(0,inplace=True)
#场均进球
count1=df.groupby(['Home Team Name']).agg('count')['Datetime']
count1.index.name='Team Name'
count2=df.groupby(['Away Team Name']).agg('count')['Datetime']
count2.index.name='Team Name'
Goals=pd.merge(Goals,count1,how='inner',on='Team Name')
Goals=pd.merge(Goals,count2,how='inner',on='Team Name')
Goals['times']=Goals.iloc[:,3]+Goals.iloc[:,4]
Goals.drop(Goals.columns[[3,4]],axis=1,inplace=True)
Goals['avginGoals']=Goals.loc[:,'inGoals']/Goals.loc[:,'times']
Goals['avgoutGoals']=Goals.loc[:,'outGoals']/Goals.loc[:,'times']
# print(Goals)
c = (
Bar(init_opts=opts.InitOpts(width='1150px'))
.add_xaxis(Goals.index.tolist())
.add_yaxis("总进球数", Goals.iloc[:,0].tolist())
.add_yaxis("总失球数", Goals.iloc[:,1].tolist())
.add_yaxis("总球数", Goals.iloc[:,2].tolist())
.add_yaxis("场均进球数", [round(i,2) for i in Goals.iloc[:,4].tolist()])
.add_yaxis("场均失球数", [round(i,2) for i in Goals.iloc[:,5].tolist()])
.add_yaxis("总比赛场数", Goals.iloc[:,3].tolist())
.set_global_opts(
title_opts=opts.TitleOpts(),
datazoom_opts=opts.DataZoomOpts(),
xaxis_opts=opts.AxisOpts(name='Team Name'),
yaxis_opts=opts.AxisOpts(name='Numbers'),
)
.render("总球数.html")
)

这个图是动态的嘛,反正可以拖动,进球多的反正都是那些强队,也没啥好说的,咱们来看看中国队,唯一一次进世界杯,但好像一个球没进,丢了9个球,打了三场,哎,看着今年的日本、韩国和沙特,真觉得国足在干嘛呀呜呜。
然后我们具体来看看冠军球队的进球和失球数吧
#统计一下冠军对的进球数失球数和场均进球失球,这里需要从另外个表获取一下数据
df1=pd.read_csv('WorldCupsSummary.csv',index_col=0)#将第一列作为索引列,即将时间作为索引
#国家获得冠军数量
groupbyed=df1.groupby(['Winner']).groups
for i in groupbyed :
groupbyed[i]=len(groupbyed[i])
groupbyed['Germany']=groupbyed['Germany FR']+groupbyed['Germany']#合并Germany与Germany FR
del groupbyed['Germany FR']
groupbyed=pd.DataFrame([groupbyed]).T
groupbyed.columns=['nums']
groupbyed.sort_values(by='nums',ascending=False,inplace=True)
guanjun=groupbyed[groupbyed['nums']>=1].index
c = (
Bar(init_opts=opts.InitOpts(width='1150px'))
.add_xaxis(guanjun.tolist())
.add_yaxis("总进球数", Goals.loc[guanjun,'inGoals'].tolist())
.add_yaxis("总失球数", Goals.loc[guanjun,'outGoals'].tolist())
.add_yaxis("总球数", Goals.loc[guanjun,'Total Goals'].tolist())
.add_yaxis("场均进球数", [round(i,2) for i in Goals.loc[guanjun,'avginGoals'].tolist()])
.add_yaxis("场均失球数", [round(i,2) for i in Goals.loc[guanjun,'avgoutGoals'].tolist()])
.add_yaxis("总比赛场数", Goals.loc[guanjun,"times"].tolist())
.add_yaxis("夺冠次数", groupbyed.loc[guanjun,"nums"].tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='按照夺冠次数排名'),
datazoom_opts=opts.DataZoomOpts(),
xaxis_opts=opts.AxisOpts(name='Team Name'),
yaxis_opts=opts.AxisOpts(name='Numbers'),
)
.render("冠军球数.html")
)
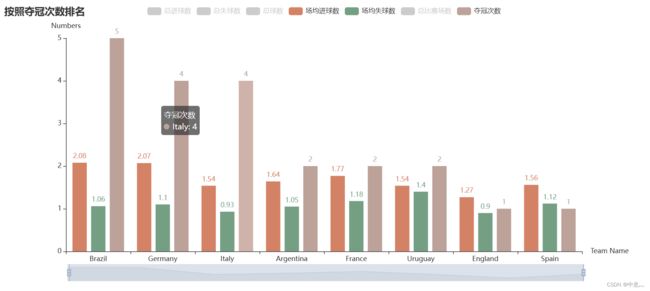
在比赛场次中,德国打的最多,其次就是巴西,加之两者实力也差不多,所以德国进球数和失球数都高于巴西也是正常,虽然巴西比德国多一个冠军呢,而在场均进球和失球数上看,巴西都好于德国,同时巴西是场均进球最多的,但只有巴西和德国场均进球破2了,说明这两只是进攻性较强的队伍,而法国的场均失球是最少的,一场比赛一个球都不一定能丢,说明法国队防守挺厉害的,
接下来,咱们看看比分最大的10场比赛是哪10场
#比分最大的比赛
df['maxGoals']=abs(df.loc[:,'Home Team Goals']-df.loc[:,'Away Team Goals'])
df.sort_values(by='maxGoals',ascending=False,inplace=True)
df['VS']=df.loc[:,'Home Team Name']+' VS '+df.loc[:,'Away Team Name']
df['result'] = df['Home Team Goals'].astype(str)+"-"+df['Away Team Goals'].astype(str)
# print(df.iloc[:10,df.columns.get_loc('VS')])
plt.figure(figsize=(12, 10))
ax = sns.barplot(y=df.iloc[:10,df.columns.get_loc('VS')], x=df.iloc[:10,df.columns.get_loc('maxGoals')])
sns.despine(right=True)
plt.ylabel('Match',fontsize=15)
plt.xlabel('Score Difference',fontsize=15)
plt.yticks(size=12)
plt.xticks(size=12)
plt.title('Top10 Score Gap', size=20)
for i, s in enumerate("Stadium " + df.iloc[:10,df.columns.get_loc('Stadium')] + ", Date: " + df.iloc[:10,df.columns.get_loc('Datetime')] + "\n" +
", match result: " + df.iloc[:10,df.columns.get_loc('result')]):
ax.text(1, i, s, fontsize=12, color='white', va='center')
plt.show()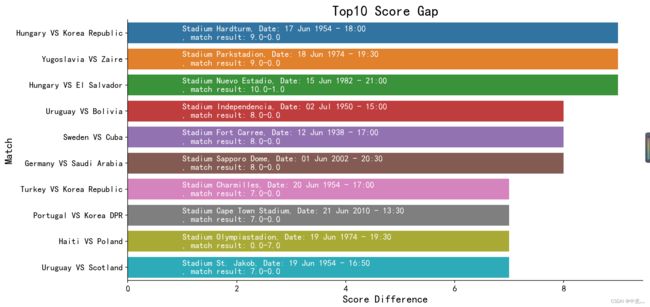 哇哦,比分差距最大的是9,这么大的比分,压对了得多大的赔率呀哇哈哈哈
哇哦,比分差距最大的是9,这么大的比分,压对了得多大的赔率呀哇哈哈哈
最后咱们来看看,参与3届世界杯以上的主裁吧,希望马宁下次能当主裁(偷笑)
#参与三届世界杯的主裁
Referee=df.groupby(['Referee']).groups
times=[]
for i in Referee:
times.append(len(list(set(Referee[i]))))
Referee[i]=list(set(Referee[i]))
Referee=pd.DataFrame().from_dict(Referee,orient='index')
Referee['Times']=times
Referee.index.name='Referee Name'
Referee.columns=['时间1','时间2','时间3','次数']
# Referee.columns=['Times']
Referee.sort_values(by='次数',inplace=True,ascending=False)
plt.figure(figsize=(12, 10))
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
ax = sns.barplot(y=Referee[Referee['次数']==3].index, x=Referee.loc[Referee[Referee['次数']==3].index,'次数'])
sns.despine(right=True)
plt.ylabel('主裁',fontsize=15)
plt.xlabel('次数',fontsize=15)
plt.yticks(size=12)
plt.xticks(size=12)
plt.title('参与三次世界杯的主裁', size=20)
for i, s in enumerate("主裁世界杯时间:" + Referee.loc[Referee[Referee['次数']==3].index,'时间1'].astype(int).astype(str)+'年、'+ Referee.loc[Referee[Referee['次数']==3].index,'时间2'].astype(int).astype(str) +'年、'+ Referee.loc[Referee[Referee['次数']==3].index,'时间3'].astype(int).astype(str)+'年'):
ax.text(1, i, s, fontsize=12, color='white', va='center')
plt.show() 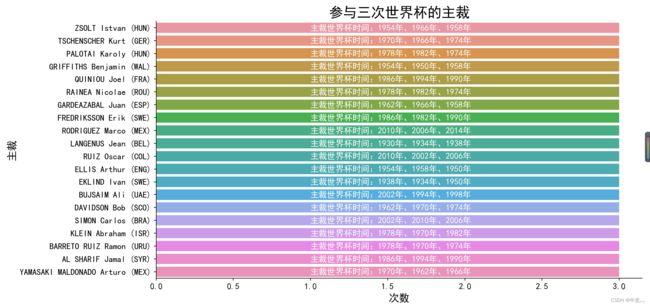
这些裁判估计都很厉害吧,咱们也不认识,我也懂足球,咱们就不对他们分析了
然后这里只分析了第两个个表,后面还有一个表的数据没有分析,我后面会更新在后面,现在先把前面的写了,怕后面忘了哇哈哈哈