深度学习应用部署
深度学习部署部署
- 模型部署简要介绍
-
- 模型部署简介
- TensorRT部署
-
- TensorRT推理
- TensorRT优化
- 多线程多进程
-
- python GIL
- 多线程
- 多进程
- 协程
- 实现方式
-
- threading实现多线程
- multiprocess实现多进程
- gevent实现协程
- concurrent实现并发
- 多线程多进程返回值
- 异步编程asyncio
-
- 如何使用asyncio
- 深度学习模型部署
-
-
- 多线程多进程推理
- gunicorn部署Flask
-
- 经验案例
-
- pytorch转onnx踩坑实录
-
- opencv里的深度学习模块不支持三维池化层
- opencv与onnxruntime的差异
- onnxruntime支持3维池化和3维卷积
- onnx动态分辨率输入
- OpenVINO™加速AI开发部署
-
-
- 具体操作
-
模型部署简要介绍
模型部署简介
目前主流的深度学习部署平台包含GPU、CPU、ARM。模型部署框架则有英伟达推出的TensorRT,谷歌的Tensorflow和用于ARM平台的tflite,开源caffe,百度的paddle,腾讯的NCNN。

TensorRT部署
TensorRT推理
- 构建TensorRT引擎。目前主流的方式是从onnx转化为TensorRT的引擎,比如有keras2onnx,tf2onnx(但是好像onnx不太支持tensorflow)
- 运行TensorRT的引擎。
ICudaEngine接口持有优化后的引擎,如果要进行推理,还要从ICudaEngine创建IExecutionContext,进而使用IExecutionContext::execute或者IExecutionContext::enqueue函数进行推理。 - 使用混合精度:TensorRT默认使用float32来进行推理,同时也支持fp16和int8的推理。使用fp16进行推理,可以得到几乎和float32相同精度的结果,但是计算量会比float32少的多,和float32推理的区别仅仅在于多设置一个flag。而使用int8进行推理,则需要首先对模型进行量化,得到每一层的动态范围,以便于在运行时进行设定。
- 动态尺寸:TensorRT还支持动态尺寸。动态尺寸是指在构建引擎时不指定全部的输入尺寸,而是以-1作为占位符,等到运行时再设定具体的尺寸。这种情况下一般需要在构建时,添加优化配置文件。
TensorRT优化
- 性能度量工具
在优化代码之前,首先必须要对代码进行度量。最简单直接的度量方法是使用c++标准库的chrono中的API来测量两个时间点的差值。但是TensorRT代码多数为并行代码,因此在CUDA中引入了CUDA Event的概念,可以更方便地对并行代码进行计时。另外还有一些官方的工具,比如trtexec和nvprof,都可以对TensorRT进行剖析。 - TensorRT优化方法
主要优化方法包含使用batch和stream。batch是指将多个尺寸相同数据组合在一起,送入网络中进行推理。这样比每次只处理一个数据要快的多。使用stream则可以增加更多的并行性。stream也可以和线程一起使用。 - TensorRT自定义层
TensorRT并不支持所有的深度学习算子。有些算子,还需要我们自己去实现。TensorRT提供了layer plugin接口,我们只需要继承该接口,并实现其中相应的函数即可。一般建议自定义层的第一步是首先使用CUDA实现自定义层的主要功能,然后再将其和layer plugin的接口进行组合。
多线程多进程
深度学习的部署方式有很多种,serving的方式可以通过Tensorflow serving 或者paddle hub的方式进行处理,Tensorflow serving的部署方式有明显的缺点是没有后续的操作,只能输入指定的输入然后得到输出结果。因此在项目中我使用的是Flaskrest-plus+Tensorflow/Onnxruntime+Docker+Gunicorn+Nginx的方式进行部署。
-
并发与并行
并发:在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一时刻点上只有一个程序在处理机上运行。例如吃饭的时候打电话,你只能吃完一口饭,再说一句话,再吃一口饭,再说一句话,并发说明你有处理多个任务的能力,不一定要同时。
并行:指的是系统具有同时处理多个任务的能力。例如上面的吃饭打电话的例子,你可以一边吃饭一边说话。
-
同步与异步
同步和异步关注的是消息通信机制。同步就是调用消息,调用方必须等到这个消息返回结果才能继续往后执行。异步与同步相反,调用方不会等待调用消息返回的结果,而是通过调用发出后,调用者可以继续执行后续操作。消息调用完成后通知调用者。
同步:当进程执行IO(等待外部数据)的时候,程序进行等待。
异步:当进程执行IO的时候,进程可以执行其他任务,一直等到数据接受成功。
-
阻塞与非阻塞
阻塞与非阻塞指的是执行一个操作是等操作结束再返回,还是立即返回。对于同步和异步的事件,阻塞和非阻塞都是可以的。非阻塞有两种方式:主动查询和被动接受消息。
python GIL
GIL官方解释翻译:在Cpython解释器中,同一个进程下开启多线程,同一时刻只能有一个线程执行,无法利用多核优势。GIL锁本质是一把互斥锁,将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务修改,进而保证数据安全。保护不同数据安全,应该加不同的锁。
每执行一个Python程序,就是开启一个进程,在一个python进程内,不仅有其主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器界别的线程。所有线程都运行在这一个进程内。因此:
- 所有数据都是共享的,这其中代码作为一种数据也是被所有线程共享的。
- 所有线程的任务,都需要将任务代码当做参数传给解释器代码去执行。即所有线程要想运行自己的任务,首先需要解决的是能够访问解释器代码。
有了GIL,Python的进程可以利用多核,但是开销大,同时多线程开销小,但是无法利用多核优势。
python的多线程是假的多线程,Python解释器虽然可以开启多个线程,但是同一时间只有一个线程能在解释器中执行,GIL锁的存在使得CPU资源同一时间只会给一个线程使用。如果是I/O密集型任务即使开再多进程也没有用,所以可以利用Python多线程。如果是计算密集型任务,可以直接使用多进程。
要理解GIL的含义,我们需要从Python的基础讲起。像C++这样的语言是编译型语言,所谓编译型语言,是指程序输入到编译器,编译器再根据语言的语 法进行解析,然后翻译成语言独立的中间表示,最终链接成具有高度优化的机器码的可执行程序。编译器之所以可以深层次的对代码进行优化,是因为它可以看到整 个程序(或者一大块独立的部分)。这使得它可以对不同的语言指令之间的交互进行推理,从而给出更有效的优化手段。
与此相反,Python是解释型语言。程序被输入到解释器来运行。解释器在程序执行之前对其并不了解;它所知道的只是Python的规则,以及在执行过程 中怎样去动态的应用这些规则。它也有一些优化,但是这基本上只是另一个级别的优化。由于解释器没法很好的对程序进行推导,Python的大部分优化其实是 解释器自身的优化。
现在我们来看一下问题的症结所在。要想利用多核系统,Python必须支持多线程运行。作为解释型语言,Python的解释器必须做到既安全又高效。我们都知道多线程编程会遇到的问题,解释器要留意的是避免在不同的线程操作内部共享的数据,同时它还要保证在管理用户线程时保证总是有最大化的计算资源。
那么,不同线程同时访问时,数据的保护机制是怎样的呢?答案是解释器全局锁。从名字上看能告诉我们很多东西,很显然,这是一个加在解释器上的全局(从解释器的角度看)锁(从互斥或者类似角度看)。这种方式当然很安全,但是它有一层隐含的意思(Python初学者需要了解这个):对于任何Python程序,不管有多少的处理器,任何时候都总是只有一个线程在执行。
”为什么我全新的多线程Python程序运行得比其只有一个线程的时候还要慢?“许多人在问这个问题时还是非常犯晕的,因为显然一个具有两个线程的程序要比其只有一个线程时要快(假设该程序确实是可并行的)。事实上,这个问题被问得如此频繁以至于Python的专家们精心制作了一个标准答案:”不要使用多线程,请使用多进程”。
所以,对于计算密集型的,我还是建议不要使用python的多线程而是使用多进程方式,而对于IO密集型的,还是劝你使用多进程方式,因为使用多线程方式出了问题,最后都不知道问题出在了哪里,这是多么让人沮丧的一件事情!
多线程
让一个进程同时执行一段代码,用起来类似于多进程,但是区别在于线程与线程之间能够共享资源。python不太推荐用多线程,因为GIL的存在。推荐使用multiprocessing或者concurrent.futures.ProcessPoolExecutor。但是如果想要同时运行多个I/O密集型任务,多线程仍然是一个合适的模型。线程之间的对于共享进程的数据需要考虑线程安全的问题,由于进程之间是隔离的,拥有独立的内存空间资源,相对比较安全。
多线程官网地址:python多线程参考文档
多进程
多进程的通信方式:管道,FIFO,消息队列,信号,共享内存,socket,stream流。同步方式是PV信号量,管程。
多进程官网地址:python3.8 多进程,python3.8 多进程共享内存
协程
协程运行与线程之上,当一个协程完成后,可以选择主动让出,让另一个协程运行在当前线程上。协程并没有增加线程数量,只是在线程的基础上通过分时复用的方式运行多核协程,而且协程的切换在用户态完成,切换的代价比线程从用户态到内核态的代价小很多。最有效的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
协程最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。其次协程不需要多线程的机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
gevent官网
简单的协程例子:
import time
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
time.sleep(1)
r = '200 OK'
def produce(c):
next(c)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)
实现方式
import threading
import time
def func(arg):
time.sleep(0.5)
print('%s running....' % arg)
threading实现多线程
t1 = threading.Thread(target=func, args=('This is thread 1', ))
t2 = threading.Thread(target=func, args=('This is thread 2', ))
t1.start()
t2.start()
t1.join()
t2.join()
print('This is a main function')
继承threading.Thread,并重写run
# 继承threading.Thread 并重写run
class CutomerThread(threading.Thread):
def __init__(self, thread_name):
# step 1: CALL BASE __init__ function
super(CutomerThread, self).__init__(name=thread_name)
self.__name = thread_name
def run(self):
# step 2: override run function
time.sleep(0.5)
print('%s running...\n' % self.__name)
t1 = CutomerThread("thread 1")
t2 = CutomerThread("thread 2")
t1.start()
t2.start()
t1.join()
t2.join()
print('this is main function')
threading.Thread提供的线程对象方法和属性:
- start()::创建线程后通过start启动线程,等待CPU调度,为run函数执行做准备。
- run():线程开始执行的入口函数,函数体中会调用用户编写的target函数,或者执行被重载的run函数。
- join([timeout]):阻塞挂起调用该函数的线程,知道被调用线程执行完成或超时。通常会在主线程中调用该方法,等待其他线程执行完成。
- name,getName()&setName():线程名称相关的操作。
- isAlive(), is_alive():start函数执行之后到run函数执行完之前都为True
- demon、isDaemon()&setDaemon():守护线程相关。
multiprocess实现多进程
from multiprocessing import Process
import os, time
def pstart(name):
print('Process name: %s, pid: %s'%(name, os.getpid()))
subproc =Process(target=pstart, args=('subprocess', ))
subproc.start()
subproc.join()
print(f'subprocess pid: {subproc.pid}')
print(f'current process pid: {os.getpid()}')
继承方式实现多进程
# 继承方式创建多进程
from multiprocessing import Process
import os, time
class CustomerProcess(Process):
def __init__(self, p_name, target=None):
super(CustomerProcess, self).__init__(name = p_name, target = target, args=(p_name, ))
def run(self):
print(f'Custom Process name: {self.name}, {os.getpid()}')
p1 = CustomerProcess('process_1')
p1.start()
p1.join()
print(f"subprocess pid: {p1.pid}")
print(f"current process pid: {os.getpid()}" )
gevent实现协程
from gevent import monkey; monkey.patch_socket()
import gevent
def f(n):
for i in range(n):
print(gevent.getcurrent(), i)
g1 = gevent.spawn(f, 5)
g2 = gevent.spawn(f, 5)
g3 = gevent.spawn(f, 5)
g1.join()
g2.join()
g3.join()
import gevent
def f1():
for i in range(5):
print(f'f1:{i}')
gevent.sleep(0)
def f2():
for i in range(10):
print(f'f2:{i}')
gevent.sleep(0)
t1 = gevent.spawn(f1)
t2 = gevent.spawn(f2)
gevent.joinall([t1, t2])
concurrent实现并发
异步执行可以由ThreadPoolExecutor使用线程或者由ProcessPoolExecutor使用单独的进程来实现。
-
Executor对象
class concurrent.futures.Executor
-
submit(fn, *args, **kwargs):fn表示要执行的函数,后面两个表示参数。方法执行返回Future对象表示可调用对象的执行。
with ThreadPoolExecutor(max_workers=1) as executor: future = executor.submit(pow, 323, 1235) print(future.result()) -
map(func, *iterables, timeout = None, chunksize=1)
类似python的map高级函数,但是iterales是立即执行而不是延迟执行的;func是异步执行的,对func的多个调用可以并发执行。如果设置了timeout,当超时的时候,会报concurrent.futures.TimeoutError。timeout可以是整数或者浮点数。
使用ProcessPoolExecutor时,这个方法会将iterables分割任务快并作为独立的任务并提交到执行池中。这些块的大概数量可以由chunksize指定正整数设置。
-
shutrdown(wait=True)
当待执行的future对象完成执行后向执行者发送信号,它就会释放正在使用的任何资源。在关闭后调用Executor.submit()和Executor.map()将会引发RuntimeError。
如果wait为True,则此方法只有在所有待执行的future对象完成执行且释放已分配的资源后才会返回。使用with语句可以避免显式调用这个方法。
-
-
ThreadPoolExecutor对象
ThreadPoolExecutor是Executor的子类,它使用线程池来异步执行调用。class concurrent.futures.ThreadPoolExecutor(max_workers=None, thread_name_prefix=‘’, initializer=None, initargs=())
from concurrent import futures import time def func1(n): print(f'this is func1') time.sleep(2) return i fs = [] with futures.ThreadPoolExecutor(max_workers=3) as executor: # for i in range(3): # future = executor.submit(func1, i) # fs.append(future) result = [executor.submit(func1, i) for i in range(3)] for future in futures.as_completed(result): print(future.result()) -
ProcessPoolExecutor对象
ProcessPoolExecutor类是Executor的子类,它使用进程池来异步地执行调用。它可以绕过全局解释器锁,也意味着可以处理和返回可封存的对象。在juptynotebook上运行代码好像不行。
from concurrent import futures import time def func1(n): i =1 print(f'this is func1') return i if __name__ == '__main__': fs = [] with futures.ProcessPoolExecutor(max_workers=3) as executor: # for i in range(3): # future = executor.submit(func1, i) # fs.append(future) result = [executor.submit(func1, i) for i in range(3)] for future in futures.as_completed(result): print(future.result()) -
Future对象
Future类可将调用对象封装为异步执行。
class concurrent.futures.Future:
- cancel():尝试取消调用。如果去掉正在执行或已结束云顶不能取消,则该方法将返回False,否则调用会被取消并且该方法将返回True。
- cancelled():如果成功调用则返回True
- running():如果调用正在执行而且不能被取消那么返回Ture
- done():如果调用已被取消或正常结束那么返回True
- result():返回调用返回值。
多线程多进程返回值
from time import ctime, sleep
import threading
import numpy as np
import collections
loops = ['广州', '北京']
t_list = ['01', '02', '03']
cldas_sum = collections.deque()
class MyThread(threading.Thread):
def __init__(self, func, args, name=''):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args
self.result = self.func(*self.args)
def get_result(self):
try:
return self.result
except Exception:
return None
def loop(nloop):
for j in t_list:
cldas_values = []
for k in range(4):
cldas_value = nloop + str(k)
cldas_values.append(cldas_value)
cldas_values.append(j)
cldas_values.append(nloop)
cldas_sum.append(cldas_values)
print(id(cldas_values))
#print(cldas_sum)
return cldas_sum
def main():
print('start at', ctime())
threads = []
nloops = range(len(loops))
for i in nloops:
t = MyThread(loop, (loops[i],), loop.__name__)
threads.append(t)
for i in nloops: # start threads 此处并不会执行线程,而是将任务分发到每个线程,同步线程。等同步完成后再开始执行start方法
threads[i].start()
for i in nloops: # jion()方法等待线程完成
threads[i].join()
print(threads[1].get_result())
print('DONE AT:', ctime())
if __name__ == '__main__':
main()
异步编程asyncio
python 的异步编程可以参考asyncio标准库。关于python的异步编程先了解两个概念:同步指的是事务的逻辑,先执行第一个事务,如果阻塞了,会一直等待,知道这个事务完成,再执行第二个事务,顺序执行。异步指的是调用这个事务之后,不会等待这个事务的处理结果,直接处理第二个事务,通过状态、通知、回调来通知调用者的处理结果。
如何使用asyncio
以下内容摘自阮一峰的Python异步编程。
- 导入
asyncio的模块包
import asyncio
- 函数前面加上
async关键字,就编程了异步函数
async def main():
pass
- 在
async函数内部的异步任务前面,加上await命令
await asyncio.sleep(1)
async函数的实例:
在async函数main的里面,asyncio.gather方法将多个异步任务包装成一个新的异步任务,必须等到多个异步任务都执行结束,这个新的异步任务才会结束。
import asyncio
async def count():
print('1')
await asyncio.sleep(1)
print('2')
async def main():
await asyncio.gather(count(), count(), count())
# python3.7
# asyncio.run(main())
asyncio.get_event_loop().run_until_complete(main())
深度学习模型部署
在一个项目中要求对图像进行目标检测以及语义分割,其中包括目标检测模型以及语义分割模型。
多线程多进程推理
部分代码:
info['filename'] = './1.png'
time1 = time.time()
result_img = inference.cityscapes(info['filename'])
result= objectDetection(Image.open(info['filename']))
time2 = time.time()
print(f'运行时间:{time2-time1}s')
p1 = multiprocessing.Process(target=inference.cityscapes, args=(info['filename'], ))
p2 = multiprocessing.Process(target=objectDetection, args=(Image.open(info['filename']), ))
p1.start()
p2.start()
p1.join()
p2.join()
time3 = time.time()
print(f'多线程多进程运行时间:{time3-time2}s')
但是运行起来时间并没有提升。
- 单线程运行时间:

- 多线程运行时间

观察整个运行过程,发现在使用多进程进行推理的时候需要再一次重新加载模型,而顺序执行程序则不需要重新加载模型。
gunicorn部署Flask
# gunicorn相关参数
-c CONFIG : CONFIG,配置文件的路径,通过配置文件启动;生产环境使用;
-b ADDRESS : ADDRESS,ip加端口,绑定运行的主机;
-w INT, --workers INT:用于处理工作进程的数量,为正整数,默认为1;
-k STRTING, --worker-class STRTING:要使用的工作模式,默认为sync异步,可以下载eventlet和gevent并指定
--threads INT:处理请求的工作线程数,使用指定数量的线程运行每个worker。为正整数,默认为1。
--worker-connections INT:最大客户端并发数量,默认情况下这个值为1000。
--backlog int:未决连接的最大数量,即等待服务的客户的数量。默认2048个,一般不修改;
-p FILE, --pid FILE:设置pid文件的文件名,如果不设置将不会创建pid文件
--access-logfile FILE : 要写入的访问日志目录
--access-logformat STRING:要写入的访问日志格式
--error-logfile FILE, --log-file FILE : 要写入错误日志的文件目录。
--log-level LEVEL : 错误日志输出等级。
--limit-request-line INT : HTTP请求头的行数的最大大小,此参数用于限制HTTP请求行的允许大小,默认情况下,这个值为4094。值是0~8190的数字。
--limit-request-fields INT : 限制HTTP请求中请求头字段的数量。此字段用于限制请求头字段的数量以防止DDOS攻击,默认情况下,这个值为100,这个值不能超过32768
--limit-request-field-size INT : 限制HTTP请求中请求头的大小,默认情况下这个值为8190字节。值是一个整数或者0,当该值为0时,表示将对请求头大小不做限制
-t INT, --timeout INT:超过这么多秒后工作将被杀掉,并重新启动。一般设定为30秒;
--daemon: 是否以守护进程启动,默认false;
--chdir: 在加载应用程序之前切换目录;
--graceful-timeout INT:默认情况下,这个值为30,在超时(从接收到重启信号开始)之后仍然活着的工作将被强行杀死;一般使用默认;
--keep-alive INT:在keep-alive连接上等待请求的秒数,默认情况下值为2。一般设定在1~5秒之间。
--reload:默认为False。此设置用于开发,每当应用程序发生更改时,都会导致工作重新启动。
--spew:打印服务器执行过的每一条语句,默认False。此选择为原子性的,即要么全部打印,要么全部不打印;
--check-config :显示现在的配置,默认值为False,即显示。
-e ENV, --env ENV: 设置环境变量;
注意:在Windows上运行gunicorn会报错,但是在Linux没有问题

在使用的时候以下命令:
gunicorn --bind 0.0.0.0:5001 app_swagger:app
会出现以下奇怪的错误:

跟gunicorn完全没关系,反而跟代码的参数有关系,在stackoverflow上看到有以下解决方案,github上issue:https://github.com/benoitc/gunicorn/issues/2286

经验案例
pytorch转onnx踩坑实录
该经验案例是摘自:模型部署翻车记:pytorch转onnx踩坑实录
首先,简单说明一下pytorch转onnx的意义。在pytorch训练出一个深度学习模型后,需要在TensorRT或者openvino部署,这时需要先把Pytorch模型转换到onnx模型之后再做其它转换。因此,在使用pytorch训练深度学习模型完成后,在TensorRT或者openvino或者opencv和onnxruntime部署时,pytorch模型转onnx这一步是必不可少的。接下来通过几个实例程序,介绍pytorch转换onnx的过程中遇到的坑。
opencv里的深度学习模块不支持三维池化层
在车牌检测任务中,检测结果如下所示,其实这种检测结果并不是一个优良的结果,可以看到检测框里的车牌是倾斜的,如果要识别车牌里的文字,那么倾斜的车牌会严重影响车牌识别结果的。

对于车牌识别这种场景,在做车牌检测时,一种优良的检测结果应该是这样的,如下图所示。

在输出车牌检测框的同时输出检测到的车牌的4个角点。有了这4个角点之后,对车牌做透视变换,这时的车牌就是水平放置的,最后做车牌识别,这样就做成了一个车牌识别系统,在这个系统里包含车牌检测,车牌矫正,车牌识别三个模块。车牌检测模块使用retinaface,原始的retinaface是做人脸检测的,它能输出人脸检测矩形框和人脸5个关键点。考虑到车牌只有4个点,于是修改retinaface的网络结构使其输出4个关键点,然后在车牌数据集训练,训练完成后,以一幅图片上做目标检测的结果如上图所示。车牌矫正模块使用了传统图像处理方法,关键函数是opencv里的getPerspectiveTransform和warpPerspective。车牌识别模块使用Intel公司提出的LPRNet。
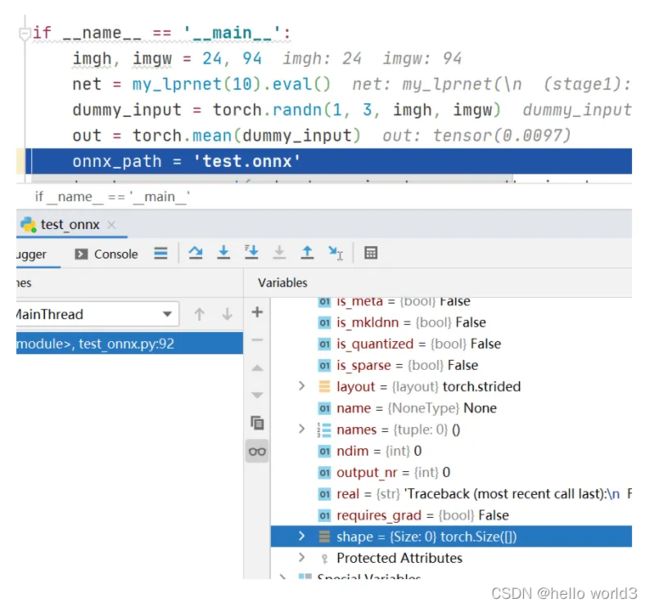
接下来尝试把pytorch模型转换到onnx文件,然后使用opencv做车牌检测与识别。然而在转换完成onnx文件后,使用opencv读取onnx文件遇到了一些坑。转换过程分两步,首先是转换车牌检测retinaface到onnx文件,这一步倒是很顺利,转换没有出错,并且使用opencv读取onnx文件做前向推理的输出结果也是正确的。第二步转换车牌识别LPRNet到onnx文件,由于Pytorch自带torch.onnx.export转换得到的ONNX,因此转换的代码很简单,在生成onnx文件后,opencv读取onnx文件出现了模型其妙的错误。程序运行的结果截图如下:

从打印结果看,torch.onnx.export生成onnx文件时没有问题的,但是在cv2.dnn.readNet这一步出现异常导致程序中断,并且打印出的异常信息是一连串的数字,去百度搜索也么找到解决办法。观察LPRNet的网络结构,发现在LPRNet里定义了3维池化层,代码截图如下:

于是,定义一个只含有3维池化层的网络,转换生成onnx文件,然后opencv读取onnx文件做前向推理,程序运行结果如下:

可以看到在这时能成功读取onnx文件,但是在执行前向计算model.forward时出错,换成3维平均池化,运行结果如下:
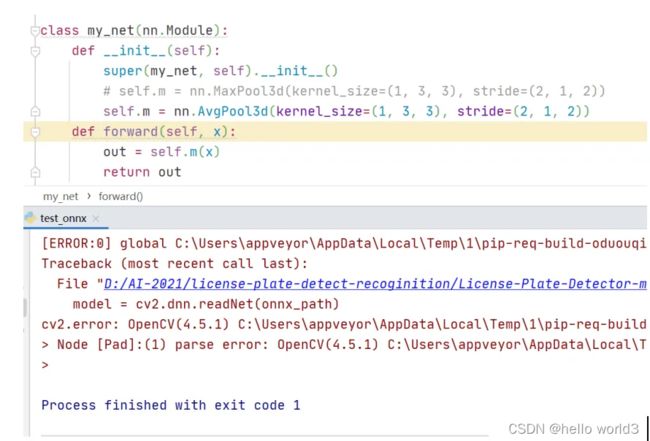
可以看到依然出错,这说明opencv的深度学习模块里不支持3维池化。不过,对比3维池化和2维池化的前向计算原理可以发现,3维池化其实等价于2个2维池化。程序实例如下:

程序最后最后运行结果打印信息是相等。从这里就可以看出opencv里的深度学习模块并不支持3维池化的前向计算,这期待后续新版本的opencv里能添加3维池化的计算。这时在LPRNet网络结构定义文件里修改3维池化层,重新生成onnx文件,opencv读取onnx文件执行前向计算后依然出错,运行结果如下:
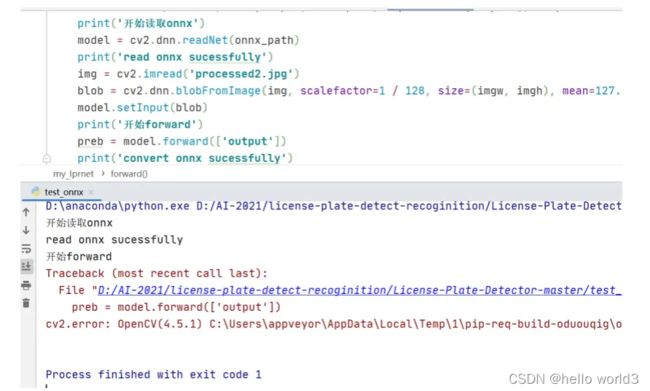
于是继续观察LPRNet的网络结构,在forward函数里看到有求平均值的操作,代码截图如下所示:
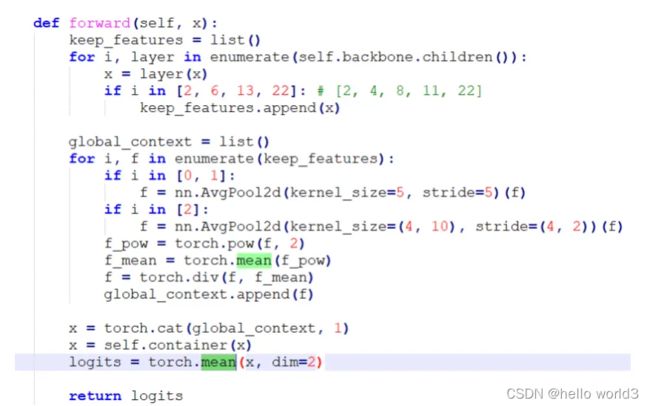
注意到第一个torch.mean函数里没有声明在哪个维度求平均值,这说明它是对一个4维四维张量的整体求平均值,这时候从一个4维空间搜索成一个点,也就是一个标量数值。但是在pytorch里,对一个张量求平均值后依然是一个张量,只不过它的维度shape是空的,示例代码如下。这时如果想要访问平均值,需要加上.item(),这个是需要注意的一个pytorch知识点。
通过以上几个程序实验,可以总结出opencv读取onnx文件做深度学习前向计算的2个坑:
(1) .opencv里的深度学习模块不支持3维池化计算,解决办法是修改原始网络结构,把3维池化转换成两个2维池化,重新生成onnx文件
(2) .当神经网络里有torch.mean和torch.sum这种把4维张量收缩到一个数值的运算时,opencv执行forward会出错,这时的解决办法是修改原始网络结构,在torch.mean的后面加上.item()
在解决这些坑之后,编写了一套使用opencv做车牌检测与识别的程序,包含C++和python两个版本的代码。使用opencv的dnn模块做前向计算,后处理模块是自己使用C++和Python独立编写的。
opencv与onnxruntime的差异
起初在github上看到一个使用DBNet检测条形码的程序,不过它是基于pytorch框架做的。于是编写一套程序把pytorch模型转换到onnx文件,使用opencv读取onnx文件做前向计算。编写完程序后在运行时没有出错,但是最后输出的结果跟调用pytorch 的输出结果不一致,并且从可视化结果看,没有检测出图片中的条形码。这时在看到网上有很多使用onnxruntime部署onnx模型的文章,于是决定使用onnxruntime部署,编写完程序后运行,选取几张快递单图片测试,结果如下图所示DBNet检测到的4个点,图中绿色的点,红色的线是把4个连接起来的直线。


并且我还编写了一个函数比较opencv和onnxruntime的输出结果,程序代码和运行结果如下,可以看到在相同输入,读取同一个onnx文件的前提下,opencv和onnxruntime的输出结果竟然不相同。

ONNXRuntime是微软推出的一款推理框架,用户可以非常便利的用其运行一个onnx模型。从这个实验,可以看出相比于opencv库,onnxruntime库对onnx模型支持的更好。
onnxruntime支持3维池化和3维卷积
在第1节讲到opencv不支持3维池化,那么onnxruntime是否支持呢?接着编写了一个程序探索onnxruntime对3维池化的支持情况,代码和运行结果如下,可以看到程序报错了。
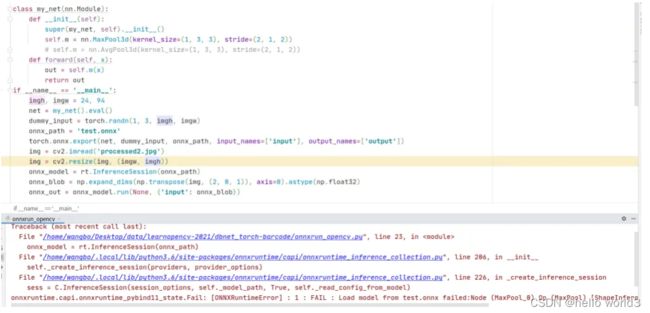
查看nn.MaxPool3d的说明文档,截图如下,可以看到它的输入和输出是5维张量,于是修改上面的代码,把输入调整到5维张量。

代码和运行结果如下,可以看到这时候onnxruntime库能正常读取onnx文件,并且它的输出结果跟pytorch的输出结果相等。
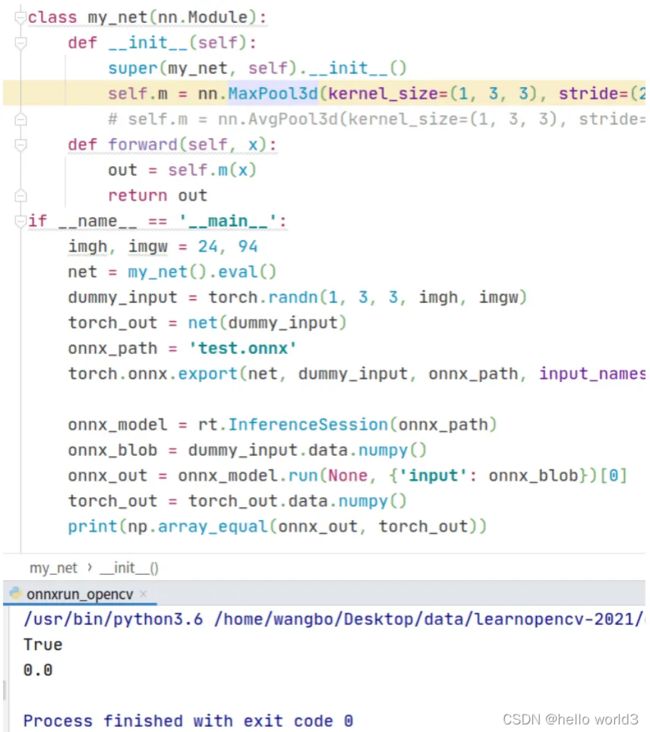
继续实验,把三维池化改作三维卷积,代码和运行结果如下,可以看到平均差异在小数点后11位,可以忽略不计。

在第1节讲到过opencv不支持3维池化,那时候的输入张量是4维的,如果把输入张量改成5维的,那么opencv是否就能进行3维池化计算呢?为此,编写代码,验证这个想法。代码和运行结果如下,可以看到在cv2.dnn.blobFromImage这行代码出错了。

查看cv2.dnn.blobFromImage这个函数的说明文档,截图如下,可以看到它的输入image是4维的,这说明它不支持5维的输入。

经过这一系列的程序实验论证,可以看出onnxruntime库对onnx模型支持的更好。如果深度学习模型有3维池化或3维卷积层,那么在转换到onnx文件后,使用onnxruntime部署深度学习是一个不错的选择。
onnx动态分辨率输入
在torch.export函数里有一个输入参数dynamic_axes,它表示动态的轴,即可变的维度。假如一个神经网络输入是动态分辨率的,那么需要定义dynamic_axes = {‘input’: {2: ‘height’, 3: ‘width’}, ‘output’: {2: ‘height’, 3: ‘width’}},接下来我编写一个程序来验证,代码和运行结果的截图如下:
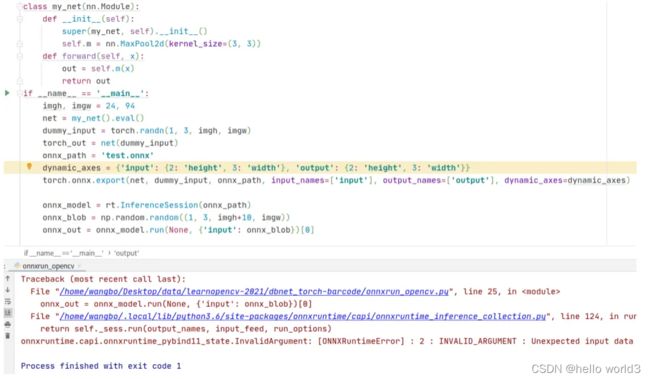
可以看到,在生成onnx文件后,使用onnxruntime库读取,对输入blob的高增加10个像素单位,在run这一步出错了。使用opencv读取onnx文件,代码和运行结果的截图如下,可以看到依然出错了。
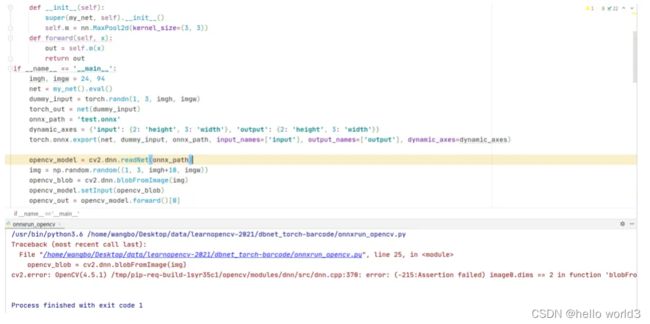
通过这个程序实验,让人怀疑torch.export函数的输入参数dynamic_axes是否真的支持动态分辨率输入的。
以上这些程序实验是我在编写算法应用程序时记录下的一些bug和解决方案的,希望能帮助到深度学习算法开发应用人员少走弯路。
此外,DBNet的官方代码里提供了转换到onnx模型文件,于是我依然编写了一套使用opencv部署DBNet文字检测的程序,依然是包含C++和Python两个版本的代码。官方代码的模型是在ICDAR场景文本检测数据集上训练的,考虑到车牌里也含有文字,我把文章开头展示的汽车图片作为输入,程序检测结果如下,可以看到依然能检测到车牌的4个角点,只是不够准确。如果想要获得准确的角点定位,可以在车牌数据集上训练DBNet。

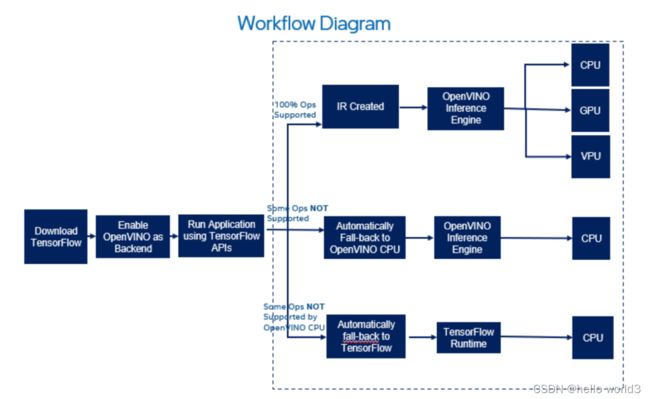
OpenVINO™加速AI开发部署
该方案出自:https://mp.weixin.qq.com/s/BBrIAABv77RJf8KtfEsBtg。其实感觉也是在推广OpenVINO的工具。使用工具对模型进行加速推理,有一个要求是使用工具后,模型的性能不会降低太多。在这篇文章中说明了在同一测试环境下,OpenVINO™ 与 TensorFlow 的集成实现了 1.34 的加速几何平均值,同时,模型的准确性保持不变:

具体操作
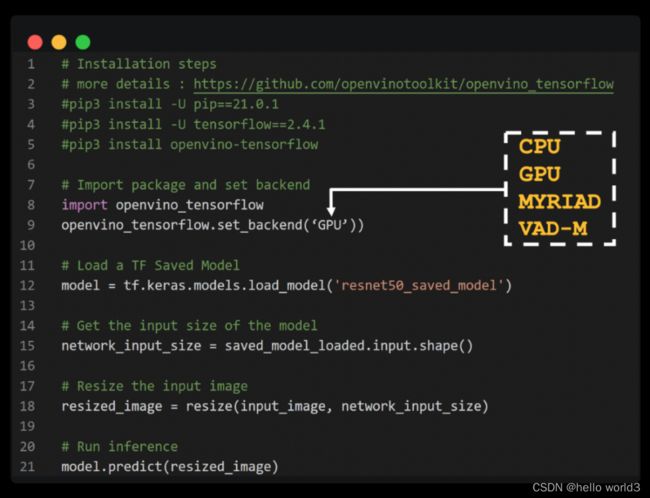
OpenVINO™ 与 TensorFlow 的集成专为使用 OpenVINO™ 工具套件的开发人员而设计——通过最少的代码修改来提高推理应用程序的性能。该集成为提高TensorFlow 兼容性提供以 OpenVINO™ 工具套件内联优化和所需运行时,并加速了各种英特尔芯片上多类AI模型的推理。通过以下代码即可加速模型推理:
import openvino_tensorflow
openvino_tensorflow.set_backend('' )
OpenVINO™ 与 TensorFlow 的集成通过将 TensorFlow 图巧妙地划分为多个子图,再将这些子图分派到 TensorFlow 运行时或 OpenVINO™ 运行时,从而实现最佳加速推理。他的工作流如下: