Pandas数据分析D1
Pandas数据分析D1
-
- 第一节 数据载入及初步观察
-
- 1.1 载入数据
-
- 任务1 :导入库
- 任务2: 载入数据
- 任务3:每1000行为一个数据模块,逐块读取
- 任务四:将表头改成中文
- 1.2 初步探索
- 1.3 保存数据
- 第二节 pandas基础
-
- 1.4 了解数据
-
- 任务一:pandas中有两个数据类型DateFrame和Series
- 任务二、三:载入文件并查看列
- 任务四:查看"Cabin"这列的所有值
- 任务五:删除多余列
- 任务六: 列元素隐藏,观察其他几个列元素
- 1.5 筛选的逻辑
-
- 任务一、二: "Age"为筛选条件
- 任务三:将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
- 任务四、五:用loc和iloc方法显示数据
- 第三节 探索性数据分析
-
- 1.6 了解你的数据吗?
-
- 任务一:利用Pandas对示例数据进行排序,要求升序
- 任务二:按票价和年龄两列进行综合排序(降序排列)
- 任务三:利用Pandas进行算术计算,计算两个DataFrame数据相加结果
- 任务四:通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?
- 任务五:学会使用Pandas describe()函数查看数据基本统计信息
- 任务六:分别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么?
datawhale动手学数据分析学习记录
第一节 数据载入及初步观察
1.1 载入数据
任务1 :导入库
import numpy as np
import pandas as pd
任务2: 载入数据
- 绝对路径和相对路径读取数据
df1 = pd.read_csv('./train.csv')
df2 = pd.read_csv(u'F:/Note/hands-on-data-analysis-master/第一单元项目集合/train.csv', encoding = "gbk")
路径中存在中文路径的解决方法:python3 处理中文路径
encoding代表文件的编码格式,常用的编码有utf-8、utf-16、gbk、gb2312、gb18030等。如果编码指定错误数据将无法读取,IPython解释器会报解析错误。
- pd.read_table() 读取数据
使用 pd.read_table() 读取会出现无法读取分割符。可用 分割参数 sep 处理。
df3 = pd.read_table('./train.csv', sep = ',', engine = 'python')
- ‘.tsv’ 和 ‘.csv’ 后缀的区别
读取csv和tsv文件以及两者的相互转换
- csv文件:逗号分隔符文件,可以使用excel打开
- tsv文件:制表符Tab分隔文件,可以使用文本文档打开
因此,可使用 sep 参数来处理两种类型文件: sep = '\t' , sep = ','
任务3:每1000行为一个数据模块,逐块读取
Pandas数据集的分块读取
- 直接分块读取: read_csv()中加入
chunksize参数
返回的reader不是DataFrame,而是一个可迭代对象(iteration),需要注意的是,这个可迭代对象不能用下标访问
reader = pd.read_csv('./train.csv', usecols = ['PassengerId', 'Survived', 'Sex'], chunksize = 5)
for i in reader:
print(i)

- 先将数据集读取为可迭代对象,再分块读取
在read_csv()方法中指定参数iterator为True,接着再分块方式遍历reader,注意使用到的get_chunk()方法和里面的参数,参数定义分块大小
reader = pd.read_csv('./train.csv', usecols = ['PassengerId', 'Survived', 'Sex'], iterator= True)
while True:
try:
print(reader.get_chunk(5))
except StopIteration:
break
通过 type(reader) 可以获取到 reader 的类别为
这种逐块读取的好处是:避免一次性读取数据后内存不够。
pandas.read_csv分块读取大文件(chunksize、iterator=True)
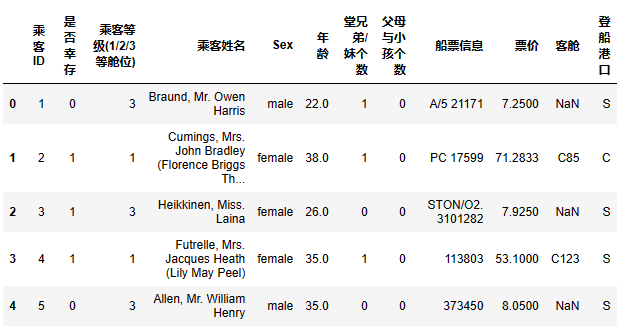
任务四:将表头改成中文
df = pd.read_csv('./train.csv')
df.columns = [' 乘客ID', '是否幸存', '乘客等级(1/2/3等舱位)',
'乘客姓名','性别', '年龄', '堂兄弟/妹个数', '父母与小孩个数',
'船票信息', '票价', '客舱','登船港口']
df.rename(columns = {'性别': 'Sex'}, inplace = True)
df.head()
1.2 初步探索
# 查看数据基本信息
df.info()
# 观察表格前10行和后15行
df.head(10)
df.tail(15)
# 判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull()
1.3 保存数据
df.to_csv('./train_chinese.csv', index = False, encoding = 'utf-8')
第二节 pandas基础
1.4 了解数据
任务一:pandas中有两个数据类型DateFrame和Series
s = pd.Series(data = [100, 'a', {'dict':5},
index = pd.Index(['id', 20, 'third', name = 'my_idx'),
dtype = 'object',
name = 'my_name')
s

df = pd.DataFrame(data = np.array([['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
[2000, 2001, 2002, 2001, 2002, 2003],
[1.5, 1.7, 3.6, 2.4, 2.9, 3.2]]).T,
index = ['row_{}'.format(i) for i in range(6)],
columns = ['state', 'year', 'pop'])
df

任务二、三:载入文件并查看列
df = pd.read_csv('./train.csv')
df.columns
任务四:查看"Cabin"这列的所有值
df['Cabin'].unique()
任务五:删除多余列
df_test = pd.read_csv('./test_1.csv')
df_test_copy = df_test.drop([i for i in df_test.columns if i not in df.columns],
axis = 1)
df_test_copy.info()
任务六: 列元素隐藏,观察其他几个列元素
df.drop(['PassengerId','Name','Age','Ticket'], axis = 1).info()
1.5 筛选的逻辑
任务一、二: "Age"为筛选条件
# 显示年龄在10岁以下的乘客信息
df[df['Age']<10]
# 将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
midage = df[(df['Age'] > 10) & (df['Age'] < 50)]
任务三:将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
midage = midage.reset_index(drop=True)
midage.loc[[100], ['Pclass', 'Sex']]
任务四、五:用loc和iloc方法显示数据
midage.loc[[100,105,108],['Pclass','Name','Sex']]
midage.iloc[[100,105,108],[2,3,4]]
Pandas.DataFrame中loc()和iloc()的区别
第三节 探索性数据分析
排序、算术计算以及计算描述函数的使用
1.6 了解你的数据吗?
任务一:利用Pandas对示例数据进行排序,要求升序
frame = pd.DataFrame(np.arange(8).reshape((2, 4)),
index=['2', '1'],
columns=['d', 'a', 'b', 'c'])
frame
# 以 c 的值排序,升序
frame.sort_values(by='c', ascending=True)
总结:
KaTeX parse error: Expected 'EOF', got '#' at position 27: …ort_values(by=‘#̲#’,axis=0,ascen…
Pandas-排序函数sort_values()
任务二:按票价和年龄两列进行综合排序(降序排列)
df.sort_values(by=['票价', '年龄'], ascending=False).head()
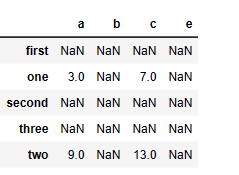
任务三:利用Pandas进行算术计算,计算两个DataFrame数据相加结果
frame1_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
frame1_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
frame1_a + frame1_b
任务四:通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?
max(df['堂兄弟/妹个数'] + df['父母与小孩个数'])
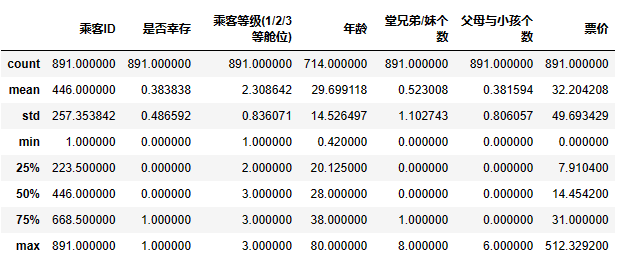
任务五:学会使用Pandas describe()函数查看数据基本统计信息
df.describe()
任务六:分别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么?
df['票价'].describe()

票价方差较大,可能蕴含较多信息,结合之前票价、年龄排序结果,票价可能是一个关键因素。