Diffusion Models, CLIP与 DALLE 的学习与感悟
整合了一下关于Diffusion Models, CLIP与 DALLE 的介绍,应用,以及后续的拓展路线。
(Generative) Diffusion Models
还是先横向对一下最近比较火的几个生成模型 GAN、VAE、Flow-based Models、Diffusion Models。

在这里,可以将Diffusion Models更多的理解成拆分成多个步骤的图像还原过程,由于图像是在整个网络中逐步还原的,且不同的时序步之间,只有n-1与n相关,其他时序步与n无关,那么就能构建出一条单通路的时序处理网络,如图所示。整个Diffusion Model的精髓就在于通过噪声(可以理解成一种掩码)将图像遮盖以获得自监督的图像对,且该图像对在单次训练中可以自动生成非常多(同时为逐步恢复的图像序列)。如下图所示。

引入定义:"Diffusion probabilistic model is parameterized Markov chain trained using variational inference to produce samples matching the data after finite time.”
Variational inference: “variational inference是一種近似複雜分佈的數學方法。而在 deep learning中最知名的一個情境就是訓練 VAE時使用的 variational bound on negative log likelihood。Diffusion model的過程其實跟 VAE有幾分相似,我們可以把 diffusion model想像成一個 encoder是固定的 VAE,然後對每個停下來的點都可以當成是 VAE裡面的 latent z,那就可以用跟 VAE的 variational lower bound寫出 p(x)的 lower bound。”
个人理解:虽然此处引入了马尔科夫链的概念以定义扩散模型,利用了一个序列变化的过程来解释(模拟)模型学习到图像特征的过程。但是从模型训练的角度来说,我认为该过程更像是一个“类微积分”的掩码训练过程,也就是将模型训练细分到更长的流程,每一步都使用了掩码作为干扰,来使模型进行“自监督”的训练。同时,由于是一种自监督过程,也不用担心数据不够,故可以由此训练超大量参数的模型,作为一种大预训练模型使用,类比GPT3.
CLIP:Contrastive Language-Image Pre-training
Intuitions of CLIP:
- 现有CV模型大多都只能预测已知的图像类别,对于没有见过的图像类别,需要额外的信息才能识别。那么文本其实就提供了这样的额外信息。所以利用图像对应的文本数据,也许就能使模型能够分辨未见类的图像。
- GPT3等大规模的无监督数据训练模型,可以在多个下游任务上获得非常好的结果,有些甚至超过使用人工标注的数据训练出的模型。
- 多模态数据的对齐,可能对图像描述与场景理解产生共鸣。
基于对比学习的模型预训练:CLIP的预训练任务是预测给定的图像和文本是否是一对(paired),使用对比学习(contrastive learning)的loss。直接将image对应的text sentence作为一个整体,来判断text和image是否是一对。对于一个包含N个图像-文本对的batch而言,其中正样本是每张图像及其对应的文本,一共有N个,而其他所有图像和文本的组合都是不成对的,也就是负样本是N×N-N个。
如图所示,每一个T代表一句话,一个I代表一张图,那么在对角线的样本对为正样本,其余的为负样本。CLIP将图像和文本先分别输入一个图像编码器image_encoder和一个文本编码器text_encoder,得到图像和文本的向量表示 I-f 和 T_f 。然后将图像和文本的向量表示映射到一个joint multimodal sapce,得到新的可直接进行比较的图像和文本的向量表示 I_e 和T_e (这是多模态学习中常用的一种方法,不同模态的数据表示之间可能存在gap,无法进行直接的比较,因此先将不同模态的数据映射到同一个多模态空间,有利于后续的相似度计算等操作)。然后计算图像向量和文本向量之间的cosine相似度。最后,对比学习的目标函数就是让正样本对的相似度较高,负样本对的相似度较低。

通过自监督的方式尽心训练,打破了原有的label-image的标签学习过程,让预训练的图像模型有机会识别未见过的图像(但是见过文本,故也称为是zeroshot)。预计它之后在图像领域会作为预训练模型,有更多的应用,如套用prompt learning 的下游任务对接。
不过,尽管CLIP在识别常见物体上表现良好,但在如计算图像中物品数量、预测图片中物品的位置距离等更抽象、复杂的任务上,“zero-shot”CLIP表现仅略胜于随机分类,而在区分汽车模型、飞机型号或者花卉种类时,CLIP也不好。且对于预训练阶段没有出现过的图像,CLIP泛化能力也很差。例如,尽管CLIP学习了OCR,但评估MNIST数据集的手写数字上,“zero-shot”CLIP准确率只达到了88%,远低于人类在数据集中的99.75%精确度。最后,研究人员发现,CLIP的“zero-shot”分类器对单词构造或短语构造比较敏感,但有时还是需要试验和错误“提示引擎”的辅助,才能表现良好。
启发~ 对于对齐sentence与image,而不是words与image的原因:文中最开始也尝试了基于预测的方法,根据image的信息预测对应的文本的每个词是什么。然而由于对于一个图像的描述可以有很多种,因此预测一个图像具体的描述词是一个非常困难的任务,导致模型收敛存在问题。因此,CLIP使用对比学习的方法,将任务简单化,只去判断图文pair是否匹配,极大提升了模型收敛速度。
CLIP Models are Few-shot Learners:
这是另一篇CLIP的衍生论文,文章对预训练CLIP的后续使用进行了讨论,这里拿出其中一个实验分析。
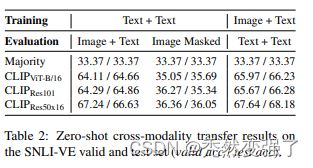
文中希望验证的另一个点是,CLIP这种多模态模型,image侧的encoder和text侧的encoder是否有很强的跨模态能力,即两个encoder的表示在隐空间中是完全对齐的。为了验证这个问题,作者将预训练CLIP的参数固定不动,使用纯文本的caption和hypothesis训练一个文本蕴含任务的分类器。接下来,对于图像-文本的蕴含任务,将图像侧信息输入到image encoder中,文本侧仍然输入到text encoder中,使用基于文本训练好的分类器进行预测。这样其实是只用文本蕴含任务的数据训练,得到了图文蕴含任务的模型,是zero-shot learning。这个过程的简单示意图如下:

结果:表面上看还不错,同时该文作者人分析说通过文本-文本的数据训练模型,整体上可以拟合图像-文本的蕴含任务。但是我认为这个实验有点点不足以证明图像-文本与文本-文本的对齐能力。一方面是因为任务本身比较简单,同时对于文本与图像的描述统一性上,该实验也未见得考虑完全。所以谨慎看好这部分~
总结:CLIP对下游任务的影响,与GPT3相似,比较考验prompts的构造,不同的构造方式,对于最终的结果,差别很大。又一次需要Prompts engineering了。
DALL.E
DALL-E与GPT-3非常相似,它也是一个transformer语言模型,接收文本和图像作为输入,以多种形式输出最终转换后的图像。它可以编辑图像中特定对象的属性,
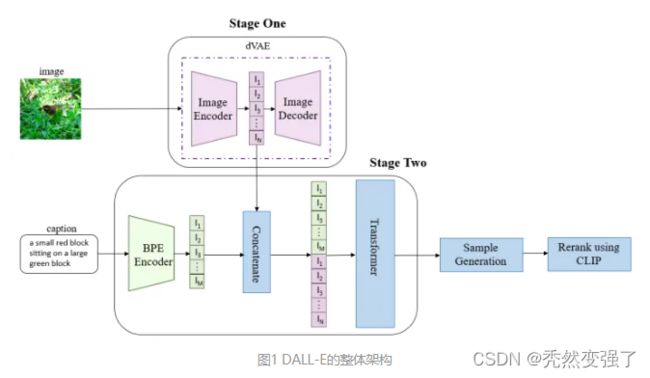
在第一个阶段,将256×256的图片分为32×32个patch,然后使用训练好的离散VAE模型的encoder将每个patch映射到大小为8192的词表中,最终一张图片转为用1024个token表示。在第二个阶段,使用BPE-encoder对文本进行编码,得到最多256个token,token数不满256的话padding到256;再将256个文本token与1024个图像token进行拼接,得到长度为1280的数据;最终将拼接的数据输入训练好的具有120亿参数的Transformer模型。在第三个阶段,对模型生成的图像进行采样,并使用同期发布的CLIP模型[2]对采样结果进行排序,从而得到与文本最匹配的生成图像。DALLE包括三个独立训练得到的模型:dVAE,Transformer和CLIP,其中dVAE的训练与VAE基本相同,Transformer采用类似GPT-3的生成式预训练方法。DALL-E在深度学习能力边界探索的道路上又前进了一步,也再一次展示了大数据和超大规模模型的魅力。美中不足的是,DALL-E包含了三个模块,更像是一个pipeline。
DALL.E mini
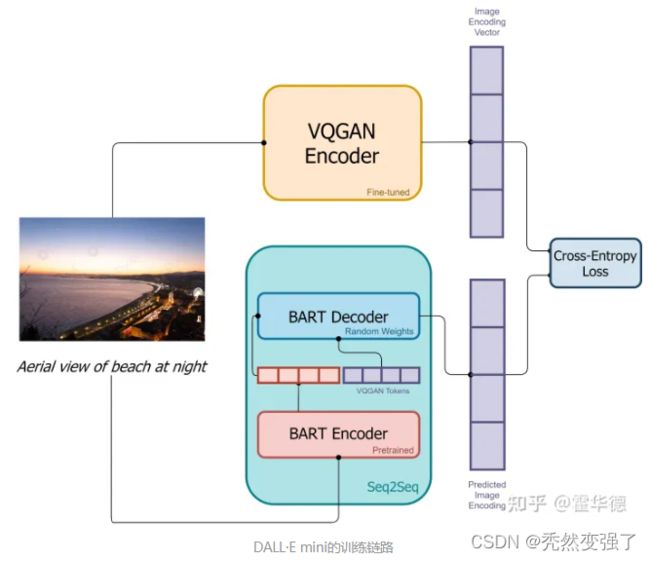
Mini 是在DALLE还未发布正版时,外界仿真出的一个模型,构建思路也很有意思。模型结构如下图,在训练过程中,输入图像和文本对。图像通过一个VQGAN编码器进行编码,该编码器将图像转化一系列token。文本通过一个BART编码器进行编码。BART编码器的输出和编码后的图像被送入BART解码器,这是一个自动回归模型,其目标是预测下一个token。损失函数是预测文本token和图像token的softmax交叉熵。
在推理时,只使用sentence,用于生成图像:sentence通过BART编码器进行编码。一个标记(识别 "Beginning Of Sequence "的特殊标记)通过BART解码器输入。根据解码器,预测下一个token的分布,对图像token进行顺序生成。图像token的序列通过VQGAN解码器进行解码。CLIP用于选择最佳生成的图像。
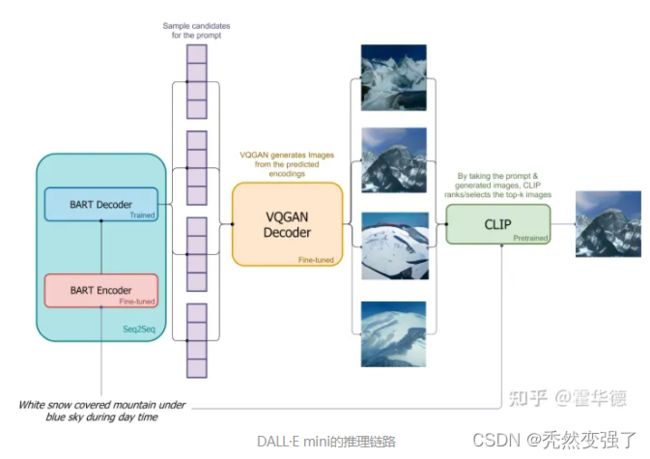
Imagen:基于扩散模型与预训练语言模型处理的图像生成
Imagen使用在纯文本语料中进行预训练的通用大型语言模型(例如T5),它能够非常有效地将文本合成图像:在Imagen中增加语言模型的大小,而不是增加图像扩散模型的大小,可以大大地提高样本保真度和图像-文本对齐。

参考文章,部分内容截取自:
【1】Diffusion Models:生成扩散模型
【2】What are Stable Diffusion Models and Why are they a Step Forward for Image Generation?
【3】What are Diffusion Models?
【4】扩散模型 Diffusion Models - 原理篇
【5】DALL·E 2 解读 | 结合预训练CLIP和扩散模型实现文本-图像生成
【6】详解CLIP (一) | 打通文本-图像预训练实现ImageNet的zero-shot分类,比肩全监督训练的ResNet50/101
【7】预训练CLIP模型的强大威力
【8】實作理解Diffusion Model: 來自DDPM的簡化概念