PyTorch算法加速指南
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
![]()
本文转自|视觉算法
这是我们正在撰写的系列文章中的第一篇。所有帖子都在这里:
1.加快算法速度,第1部分—PyTorch
2.加快算法速度,第2部分-Numba
3.加快算法速度,第3部分—并行化
4.加快算法速度,第4部分--Dask
这些与Jupyter Notebooks配套,可在此处获得:[Github-SpeedUpYourAlgorithms]和[Kaggle]
(编辑-28/11/18)-添加了“torch.multiprocessing”部分。
目录
介绍
如何检查CUDA的可用性?
如何获取有关cuda设备的更多信息?
如何存储张量并在GPU上运行模型?
如果有多个GPU,如何选择和使用GPU?
数据并行
数据并行性比较
torch.multiprocessing
参考文献

1.引言
在本文中,我将展示如何使用torch和pycuda检查、初始化GPU设备,以及如何使算法更快。
PyTorch是建立在torch之上的机器学习库。它得到了Facebook AI研究小组的支持。在最近开发之后,由于它的简单性,动态图以及本质上是pythonic,它已经获得了很大的普及。它的速度仍然不会落后,在许多情况下甚至可以超越其表现。
pycuda允许您从python访问Nvidia的CUDA并行计算API。
2.如何检查CUDA的可用性

Sydney Rae在《 Unsplash》上创作的“沙滩上的棕色干树叶”
要检查Torch是否可以使用cuda设备,您可以简单地运行:
import torch
torch.cuda.is_available()
# True3.如何获得cuda设备的更多信息
Rawpixel在Unsplash上发布的“黑色智能手机”
要获取设备的基本信息,可以使用torch.cuda。但是,要获取有关设备的更多信息,可以使用pycuda,这是CUDA库周围的python包装器。您可以使用类似:
import torch
import pycuda.driver as cuda
cuda.init()
## Get Id of default device
torch.cuda.current_device()
# 0
cuda.Device(0).name() # '0' is the id of your GPU
# Tesla K80或者
torch.cuda.get_device_name(0) # Get name device with ID '0'
# 'Tesla K80'我编写了一个简单的类来获取有关您的cuda兼容GPU的信息:

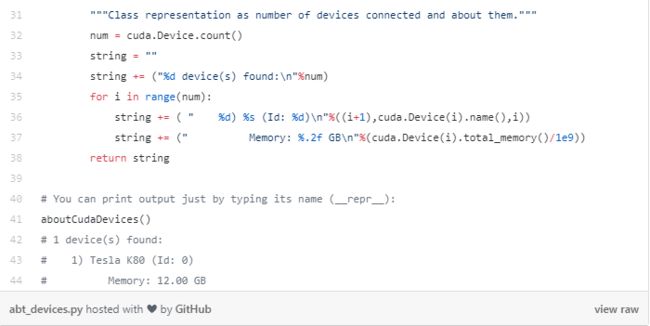
要获取当前的内存使用情况,可以使用pyTorch的函数,例如:
mport torch
# Returns the current GPU memory usage by
# tensors in bytes for a given device
torch.cuda.memory_allocated()
# Returns the current GPU memory managed by the
# caching allocator in bytes for a given device
torch.cuda.memory_cached()运行应用程序后,可以使用简单的命令清除缓存:
# Releases all unoccupied cached memory currently held by
# the caching allocator so that those can be used in other
# GPU application and visible in nvidia-smi
torch.cuda.empty_cache()但是,使用此命令不会通过张量释放占用的GPU内存,因此它无法增加可用于PyTorch的GPU内存量。
这些内存方法仅适用于GPU。
4.如何在GPU上存储张量并且运行模型?
使用 .cuda

五只鸽子在栏杆上栖息,一只鸽子在飞行中---来自Nathan Dumlao Unsplash上的作品
如果要在cpu上存储内容,可以简单地写:
a = torch.DoubleTensor([1., 2.])此向量存储在cpu上,您对其执行的任何操作都将在cpu上完成。要将其传输到gpu,您只需执行.cuda:
a = torch.FloatTensor([1., 2.]).cuda()或者
这将为其选择默认设备,该默认设备可通过命令查看
torch.cuda.current_device()
# 0也可以这样:
a.get_device()
# 0您也可以将模型发送到GPU设备。例如,考虑一个由nn.Sequential组成的简单模块:
sq = nn.Sequential(
nn.Linear(20, 20),
nn.ReLU(),
nn.Linear(20, 4),
nn.Softmax()
)要将其发送到GPU设备,只需执行以下操作:
model = sq.cuda()您可以检查它是否在GPU设备上,为此,您必须检查其参数是否在GPU设备上,例如:
# From the discussions here: discuss.pytorch.org/t/how-to-check-if-model-is-on-cuda
next(model.parameters()).is_cuda
# True5.在多个GPU中,如何选择GPU进行运算?

NeONBRAND 在Unsplash上的“工具的选择性聚焦摄影”
您可以为当前应用程序/存储选择一个GPU,该GPU可以与您为上一个应用程序/存储选择的GPU不同。
正如在第(2)部分中已经看到的那样,我们可以使用pycuda获取所有与cuda兼容的设备及其ID,在此不再赘述。
考虑到您有3个cuda兼容设备,可以将张量初始化并分配给特定设备,如下所示:

在这些Tensor上执行任何操作时,无论选择哪个设备,都可以执行该操作,结果将与Tensor保存在同一设备上。
x = torch.Tensor([1., 2.]).to(cuda2)
y = torch.Tensor([3., 4.]).to(cuda2)
# This Tensor will be saved on 'cuda2' only
z = x + y如果您有多个GPU,则可将应用程序在多个设备上工作,但是它们之间会产生通信开销。但是,如果您不需要太多中继信息,则可以尝试一下。
其实还有一个问题。在PyTorch中,默认情况下,所有GPU操作都是异步的。尽管在CPU和GPU或两个GPU之间复制数据时确实进行了必要的同步,但是如果您仍然使用torch.cuda.Stream()命令创建自己的流,那么您将必须自己照顾指令的同步 。
从PyTorch的文档中举一个例子,这是不正确的:
cuda = torch.device('cuda')
s = torch.cuda.Stream() # Create a new stream.
A = torch.empty((100, 100), device=cuda).normal_(0.0, 1.0)
with torch.cuda.stream(s):
# because sum() may start execution before normal_() finishes!
B = torch.sum(A)如果您想充分利用多个GPU,可以:
1.将所有GPU用于不同的任务/应用程序,
2.将每个GPU用于集合或堆栈中的一个模型,每个GPU都有数据副本(如果可能),因为大多数处理是在训练模型期间完成的,
3.在每个GPU中使用带有切片输入和模型副本。每个GPU都会分别计算结果,并将其结果发送到目标GPU,然后再进行进一步的计算等。
6.数据并行

阿比盖尔·基南(Abigail Keenan)在《 Unsplash》上的“森林中的树木摄影”
在数据并行中,我们将从数据生成器获得的数据(一个批次)分割为较小的小型批次,然后将其发送到多个GPU进行并行计算。
在PyTorch中,数据并行是使用torch.nn.DataParallel实现的。
我们将看到一个简单的示例来了解实际情况。为此,我们必须使用nn.parallel的一些功能,即:
1.复制:在多个设备上复制模块。
2.分散:在这些设备中的第一维上分配输入。
3.收集:从这些设备收集和连接第一维的输入。
4.parallel_apply:要将从Scatter获得的一组分布式输入s,应用于从Replicate获得的相应分布式Module集合。
# Replicate module to devices in device_ids
replicas = nn.parallel.replicate(module, device_ids)
# Distribute input to devices in device_ids
inputs = nn.parallel.scatter(input, device_ids)
# Apply the models to corresponding inputs
outputs = nn.parallel.parallel_apply(replicas, inputs)
# Gather result from all devices to output_device
result = nn.parallel.gather(outputs, output_device)或者,更简单
model = nn.DataParallel(model, device_ids=device_ids)
result = model(input)7.数据并行比较

Icon8团队在Unsplash上发布“银铃闹钟”
我没有多个GPU,但是我可以在这里找到Ilia Karmanov和他的github存储库上一篇不错的文章,其中比较了使用多个GPU的大多数框架。
他的结果:
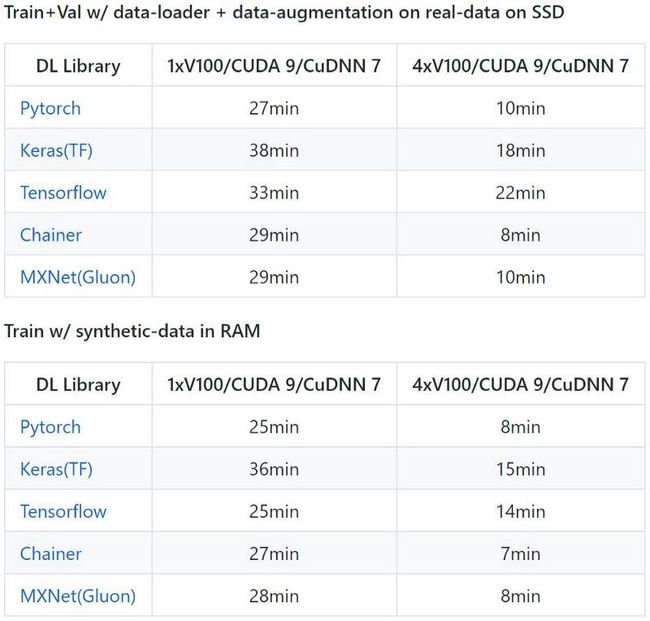
[他的github存储库最新更新:(2018年6月19日)]。PyTorch 1.0,Tensorflow 2.0的发布以及新的GPU可能已经改变了这一点……]
因此,您可以看到,即使必须在开始和结束时与主设备进行通信,并行处理也绝对有帮助。在多GPU情况下,PyTorch的结果要比Chainer及其他所有结果都快。通过一次调用DataParallel,Pytorch也使其变得简单。
8.torch.multiprocessing

Unsplash 上Matthew Hicks作品
torch.multiprocessing是Python多处理模块的包,其API与原始模块100%兼容。因此,您可以在此处使用Python的多处理模块中的Queue,Pipe,Array等。此外,为了使其更快,他们添加了一个方法share_memory_(),该方法使数据进入任何进程时都可以直接使用,因此将数据作为参数传递给不同的进程将不会复制该数据。
您可以共享张量,模型参数,也可以根据需要在CPU或GPU上共享它们。

您可以在此处的“池和进程”部分中使用上面的方法,并且要获得更快的速度,可以使用share_memory_()方法在所有进程之间共享张量,而无需复制数据。
您也可以使用机器集群。有关更多信息,请参见此处。
9.参考
https://documen.tician.de/pycuda/
https://pytorch.org/docs/stable/notes/cuda.html
https://discuss.pytorch.org/t/how-to-check-if-model-is-on-cuda
https://medium.com/@iliakarmanov/multi-gpu-rosetta-stone-d4fa96162986
感谢您的阅读!
via https://towardsdatascience.com/speed-up-your-algorithms-part-1-pytorch-56d8a4ae7051
- END -
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

