sklearn数据预处理(三)归一化

@R星校长
第3关:归一化
任务描述
本关任务:利用sklearn对数据进行归一化。
相关知识
为了完成本关任务,你需要掌握:1.为什么使用归一化,2.L1范式归一化,3.L2范式归一化。
为什么使用归一化
归一化是缩放单个样本以具有单位范数的过程。归一化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化的前提。归一化能够加快模型训练速度,统一特征量纲,避免数值太大。 值得注意的是,归一化是对每一个样本做转换,所以是对数据的每一行进行变换。 而之前我们讲过的方法是对数据的每一列做变换。
L1范式归一化
L1范式定义如下:
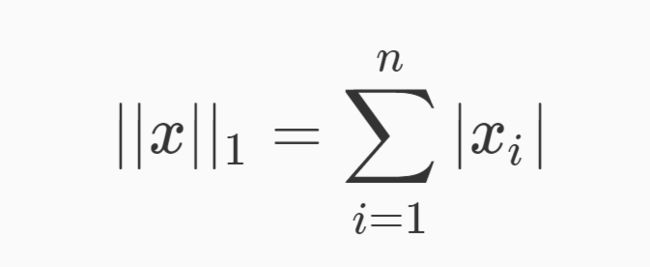
表示向量x中每个元素的绝对值之和。
L1范式归一化就是将样本中每个特征除以特征的L1范式。
在sklearn中使用normalize方法实现,用法如下:
from sklearn.preprocessing import normalize
data = np.array([[-1,0,1],
[1,0,1],
[1,2,3]])
data = normalize(data,'l1')
>>>data
array([[-0.5 , 0. , 0.5 ],
[ 0.5 , 0. , 0.5 ],
[ 0.167, 0.333, 0.5 ]])
L2范式归一化
L2范式定义如下:
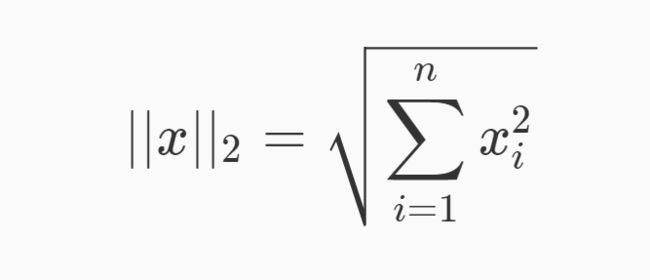
表示向量元素的平方和再开平方根。
L2范式归一化就是将样本中每个特征除以特征的L2范式。
在sklearn中使用normalize方法实现,用法如下:
from sklearn.preprocessing import normalize
data = np.array([[-1,0,1],
[1,0,1],
[1,2,3]])
data = normalize(data,'l2')
>>>data
array([[-0.707, 0. , 0.707],
[ 0.707, 0. , 0.707],
[ 0.267, 0.535, 0.802]])
编程要求
根据提示,在右侧编辑器Begin-End处补充Python代码,实现数据归一化方法,我们会使用实现好的方法对数据进行处理。
测试说明
我们会调用你实现的方法对数据进行处理,如数据为:
data = np.array([[-1,0,1],
[1,0,1],
[1,2,3]])
使用L1归一化则输出为:
array([[-0.5 , 0. , 0.5 ],
[ 0.5 , 0. , 0.5 ],
[ 0.167, 0.333, 0.5 ]])
使用L2归一化则输出为:
array([[-0.707, 0. , 0.707],
[ 0.707, 0. , 0.707],
[ 0.267, 0.535, 0.802]])
数据处理正确则视为通关。
开始你的任务吧,祝你成功!
答案:
# -*- coding: utf-8 -*-
from sklearn.preprocessing import normalize
#实现数据归一化方法
def normalization(x,y):
'''
x(ndarray):待处理数据
y(int):y等于1则使用"l1"归一化
y等于2则使用"l2"归一化
'''
#********* Begin *********#
if y == 1:
x = normalize(x,norm='l1')
return x
elif y == 2:
x = normlize(x,norm='l2')
return x
#********* End *********#







