Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3)
——分布式环境搭建
前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下。
在这里,我们采用这样的策略来模拟环境,我们使用3台ubuntu机器,1台为作主机(master),另外2台作为从机(slaver)。同时,这台主机,我们就用第一章中搭建好的环境来。
我们采用与第一章中相似的步骤来操作:
-
运行环境搭建
在前面,我们知道,运行hadoop是在linux上运行的。所以我们单机就在ubuntu上运行着。所以同样,2台从机,同样采用linux系统。为了节省资源,本人试验时用了2台centOS系统,而且是采用命令行的方式,没有用图形方式。
系统中软件准备,第一章中我们准备了subversion ssh ant 和jdk。那在这里,从机上我们不要这么多了,我们不用再下载、编译代码了,从主机上复制就行。所以在从机上只需要安装ssh 和jdk这两个:
先用 sudo apt-get install ssh这个命令,把SSH安装起来。
注:在centOS中,使用yum install ssh。
java环境,可以在网上下载一个JDK安装包,如:jdk-6u24-linux-i586.bin
安装直接在目录下运行./jdk-6u24-linux-i586.bin即可。
然后配置jdk目录:
先进入安装目录 cd jdk-6u24-…
然后输入 PWD 就可以看到java安装目录,复制下来:

命令行执行:sudo gedit /etc/profile
在打开的文件里,追加:
export JAVA_HOME=/home/administrator/hadoop/jdk1.6.0_27 //这里要写安装目录
export PATH=${JAVA_HOME}/bin:$PATH
执行source /etc/profile 立即生效
-
网络配置
要想运行分布式环境,那这3台计算机(虚拟机)肯定是要联网才行。同时,三台之前也要畅通无阻。
如果直接采用虚拟机,就比较方便了,默在虚拟机中都使用NAT联网方式即可:
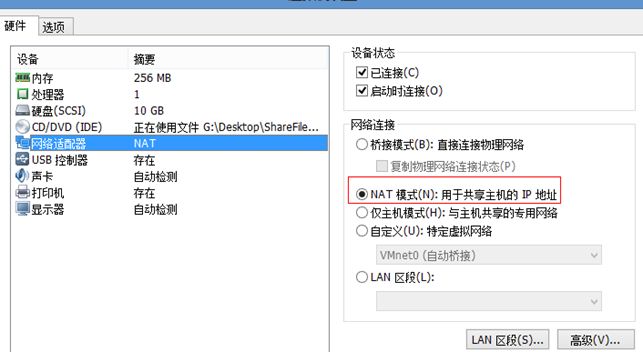
分别进入三个系统,用ifconfig命令,可以查到当前分配过来的IP地址:
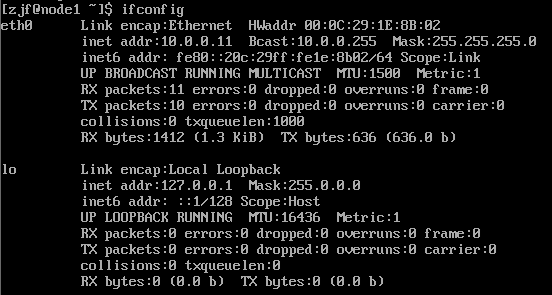
如上图中可以看到是10.0.0.11。
如果发现没有eth0,也就是说网卡还没启用或分配好地址,则可以手动分配:
ifconfig eth0 10.0.0.12 netmask 255.255.255.0 //设置eht0 的IP地址
route add default gw 10.0.0.2 //设置网关
在VMware中,怎么看到网关呢,可以在菜单 编辑->虚拟网络编辑器 中看到:
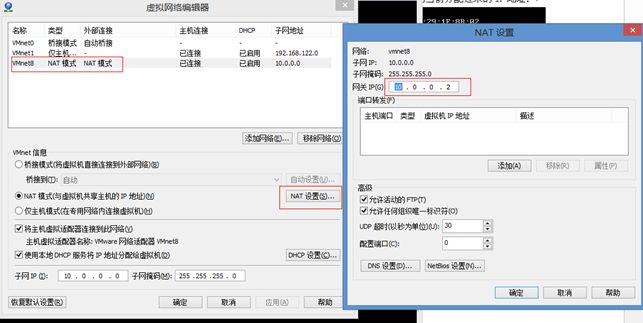
网关一定要配置对,否则光IP地址后,机器之前互想ping不通的。
在配置好IP后,可以尝试ping一下网关和其他机器,看是否能通。
在这里,我们3台机IP为:
主机 master : 10.0.0.10
从机1 salter1 :10.0.0.11
从机2 salter2 :10.0.0.12
有了3台机器的IP地址,我们想,后面在配置中肯定会用到,但为了方便以后IP地址的变动,所以我们还是用另名吧。在window中,我们知道在C:\Windows\System32\driver\etc下,有个host文件,修改后,就可以将IP换成别名了。
在linux中,同样有这个文件,在/etc/hosts中。所以编辑一下: $vi /etc/hosts:
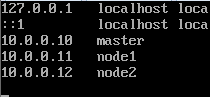
文件保存后,就可以试一下ping master ping node1来代替IP地址了。
这个操作需要在三个机器上都操作一下。
现在网络了,为了后面操作,在所有部署运行hadoop的机器上,都必须使用相同的帐号。所以需要在2台从机上创建一个与主机一样的帐号、密码:
比如都用zjf帐号: $user add zjf 设置密码: $passwd zjf 进入该帐号: $su zjf
有可能机器上会有防火墙,影响后面的远程,所以可以先关一下:
$ service iptables stop
-
配置SSH
第1章中我们了解了SSH的功能,在这里就可真正派用处了。
我们在master机中,用ssh试一下连接node1:

可以看到,需要输入密码才能够进入。远程启动所有从机时,一个个输入密码,也不是个好事,得配置下:
-
在从机node1中先实现自己登陆自己时不要输入密码。
这个在第1章中已经描述。这里就不多述了。结果就是:
-
让主结点(master)能通过SSH免密码登录两个子结点(slave)
为了实现这个功能,两个slave结点的公钥文件中必须要包含主结点的公钥信息,这样当master就可以顺利安全地访问这两个slave结点了。操作过程如下:
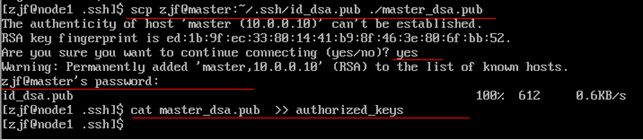
$cd ~/.ssh
$scp zjf@master:~/.ssh/id_dsa.pub ./master_dsa.pub
$cat master_dsa.pub >> authorized_keys
好了,配置完后,回到master机器中,再来试一下ssh node1:

OK,成功进入,没有要输入密码。
同样,把node2也安这个方式操作一下。
-
配置hadoop
在第一章配置基础上,我们需要增加两项配置:
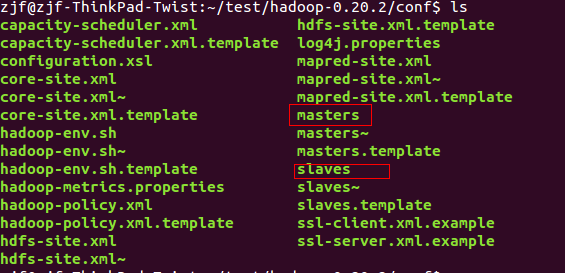
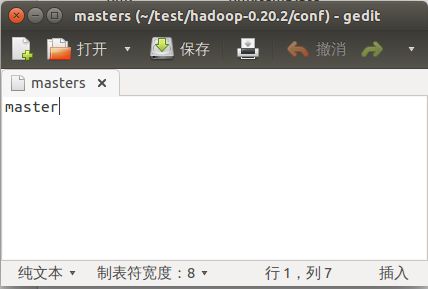
在conf文件夹下,找到masters文件,编辑,在里面输入master后保存:
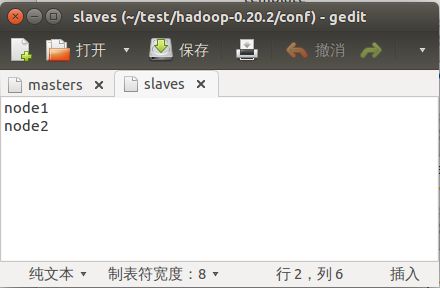
在同文件夹下,找到slaves,编辑,在里面输入node1 node2后保存:
打开conf下core-site.xml:
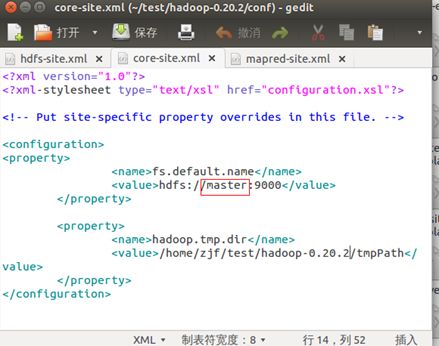
里面的localhost换成master。
打开conf下的marped-site.xml:
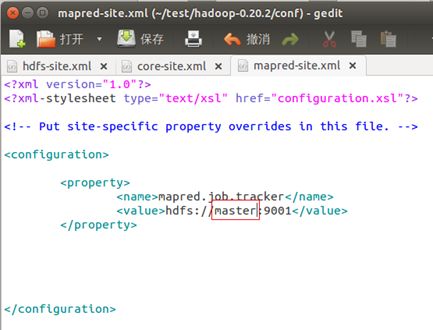
同样,也是里面的localhost换成master。
-
复制hadoop包
前面,在一台机器上部署时,我们的hadoop包是通过SVN下载了源码,然后再用ant编译出来的,但在这里,从机上就不用这么麻烦了,我们可以从主机上复制过去。如何复制呢? 远程登陆我们用SSH,远程复制就用SCP。在复制前要注意,我们在主机中hadoop存放在什么位置,在从机中也要存放在该位置才行。
比如,在主机中,我们存放于test下,所以在2台node上,都创建一下test文件夹。
然后在主机上执行:scp -r hadoop-0.20.2/ node1:~/test 然后会看到刷屏,表示在复制了。
同样执行: scp -r hadoop-0.20.2/ node2:~/test
好了,现在两台从机上也都有了hadoop包了。
-
运行
在主机上,进入hadoop-0.20.2目录,运行bin/start-all.sh,即可以启动整个分布式系统了。
然后在主机上运行jps:
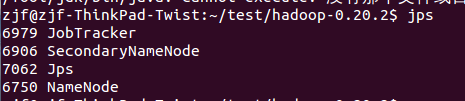
在从机上运行jps:

在主服务器上打开 http://localhost:50070,可以看到:
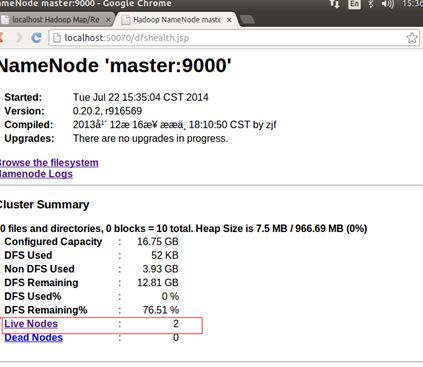
有两个活动的结点,点进去,可以看到:
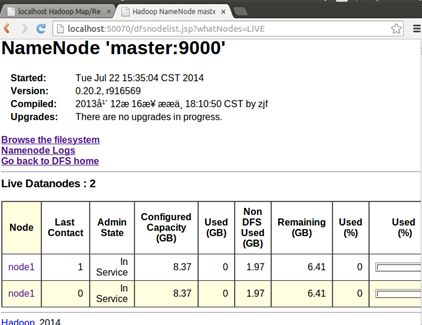
点下面的结点可以查看详细,如果点开页面打不开,则有可能是机器防火墙阻止了。
可以进入相应机器,执行
$ service iptables stop
来关闭防火墙。
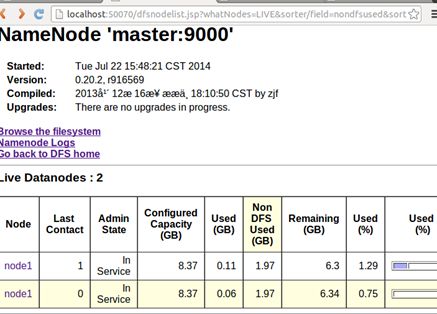
我们可以尝试上传一下文件:
$bin/hadoop fs -put ~/Tool/eclipse-SDK-3.7.1-linux-gtk.tar.gz test1.tar.gz
可以看到:
再上传一下文件:
$bin/hadoop fs -put ~/Tool/eclipse-SDK-3.7.1-linux-gtk.tar.gz test2.tar.gz
可以看到:
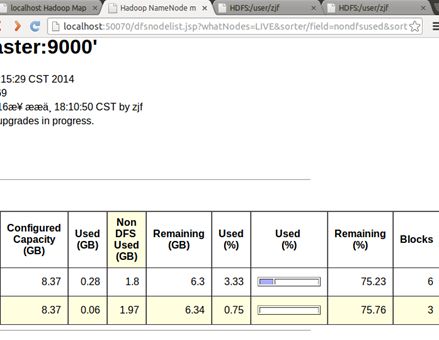
但发现不平衡,都跑一台上了。所以可以执行命令
$bin/hadoop balancer -threshold 1
这样,再来看:
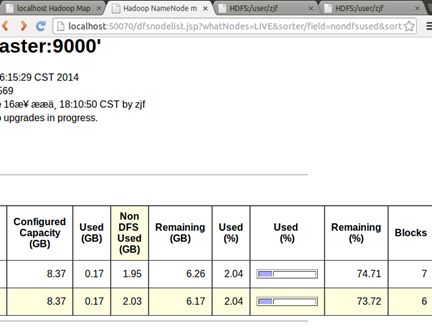
平衡了。