竞赛打卡:糖尿病遗传风险检测挑战赛
竞赛打卡:糖尿病遗传风险检测挑战赛
本博客是竞赛学习打卡记录博客。学习地址Coggle七月学习打卡。就是记录在竞赛学习过程中的打卡内容(有可能不会按照内容全部进行打卡,时间可能不是很够)
学习内容
本教程主要是针对糖尿病遗传风险检测挑战赛开展,将讲解数据比赛中具体使用的知识点和细节。 在本次学习中我们将学习特征工程、特征筛选和模型调参过程。
赛题地址:比赛地址
赛题介绍
在这次比赛中,您需要通过训练数据集构建糖尿病遗传风险预测模型,然后预测出测试数据集中个体是否患有糖尿病,和我们一起帮助糖尿病患者解决这“甜蜜的烦恼”。对于测试数据集当中的个体,您必须预测其是否患有糖尿病(患有糖尿病:1,未患有糖尿病:0),预测值只能是整数1或者0。
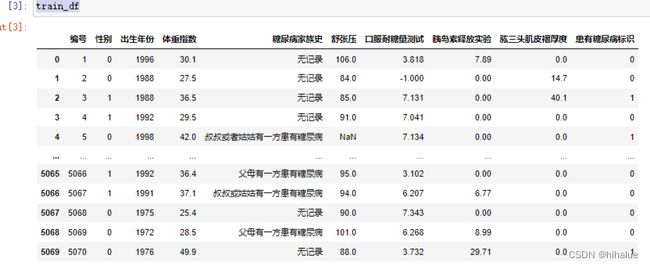
训练集(比赛训练集.csv)一共有5070条数据,用于构建您的预测模型(您可能需要先进行数据分析)。数据的字段有编号、性别、出生年份、体重指数、糖尿病家族史、舒张压、口服耐糖量测试、胰岛素释放实验、肱三头肌皮褶厚度、患有糖尿病标识(最后一列),您也可以通过特征工程技术构建新的特征。
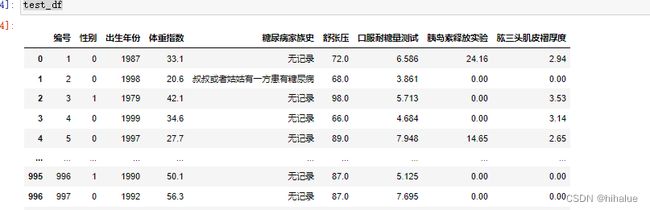
测试集(比赛测试集.csv)一共有1000条数据,用于验证预测模型的性能。数据的字段有编号、性别、出生年份、体重指数、糖尿病家族史、舒张压、口服耐糖量测试、胰岛素释放实验、肱三头肌皮褶厚度。
0708更新
任务1:报名比赛
步骤1:报名比赛
进入竞赛地址,点击报名即可。

步骤2:下载比赛数据(点击比赛页面的赛题数据)
报名完成后,就可以进行数据集的下载了
步骤3:解压比赛数据,并使用pandas进行读取;
这个比较简单,直接使用pandas读就行了
import numpy as np
import pandas as pd
train_df = pd.read_csv('data/1/比赛训练集.csv', encoding='gbk')
test_df = pd.read_csv('data/1/比赛测试集.csv', encoding='gbk')
print(train_df)
print(test_df)
步骤4:查看训练集和测试集字段类型
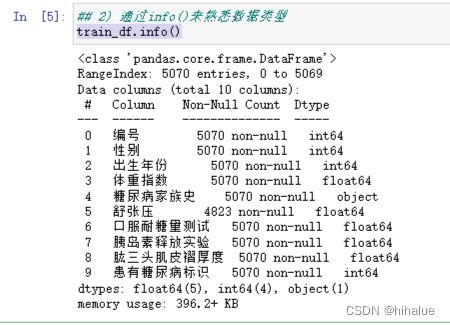
使用DataFrame的info()函数来查看数据集的字段类型
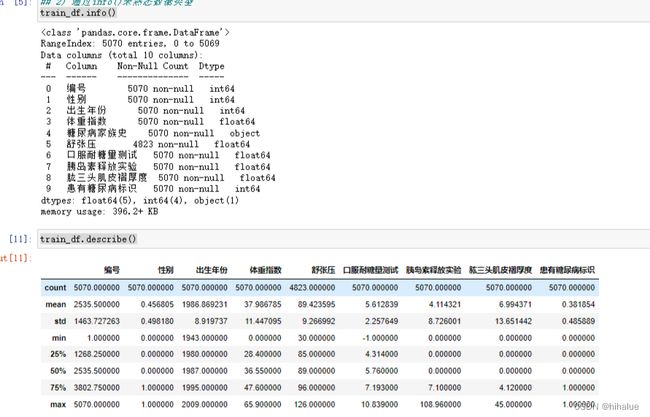
print(train_df.info())
print(test_df.info())
任务2:比赛数据分析
步骤1:统计字段的缺失值,计算缺失比例
缺失值可以用DataFrame里的isnull()来查看,在后面再调用sum()或者mean()可以得到总和以及平均。这里我们想看两个数据集的比例关系,所以mean相对合理一些(因为行数即数据样本数不同)
train_df.isnull().sum() # 这里不方便对比train和test的分布情况,因为总的行数不同,所以建议使用mean()
print(train_df.isnull().mean(0))
print(test_df.isnull().mean(0))

可以看到只有一列(舒张压)有缺失值。
步骤2:分析字段的类型
字段类型可以用任务1 的info来查看(可以通过查看Dtype来判断数据类型);还可以进一步用describe()来查看数值列的mean、max等信息。
print(train_df.info())
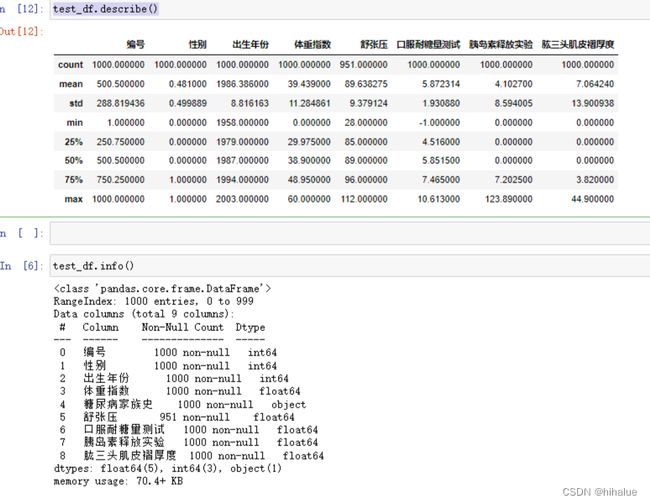
print(test_df.info())
print(train_df.describe())
print(test_df.describe())
步骤3:计算字段相关性
计算相关性可以用corr()来计算;可视化我一般使用sns.heatmap();当然也可以用打卡内容汇总里面提示的那几个图像
## 1) 相关性分析
price_numeric = train_df.copy()
correlation = price_numeric.corr()
print(correlation['患有糖尿病标识'].sort_values(ascending = False),'\n')
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
f , ax = plt.subplots(figsize = (7, 7))
plt.title('数据与是否患病的Correlation',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
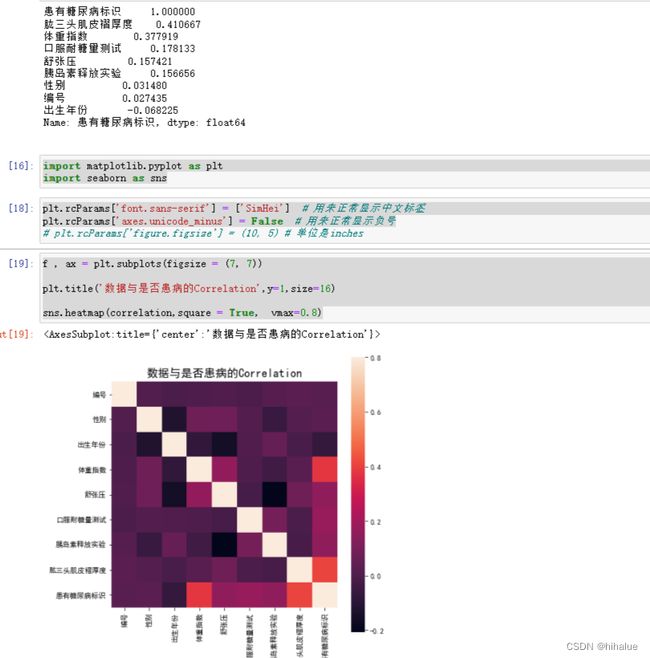
这样就比较清晰得看出数值列和是否患病 的相关性(这里有一列非数值没考虑,可以尝试将其独热编码后再进行相关性分析)
也可以用打卡汇总中提示的这几个图(记得分开,不然画到一起,就不知道要怎么看了。。。)
# train_df['性别'].value_counts().plot(kind='barh')
sns.countplot(x='患有糖尿病标识', hue='性别', data=train_df) # 条形图
# sns.boxplot(y='出生年份', x='患有糖尿病标识', hue='性别', data=train_df) #箱线图
# sns.violinplot(y='体重指数', x='患有糖尿病标识', hue='性别', data=train_df)
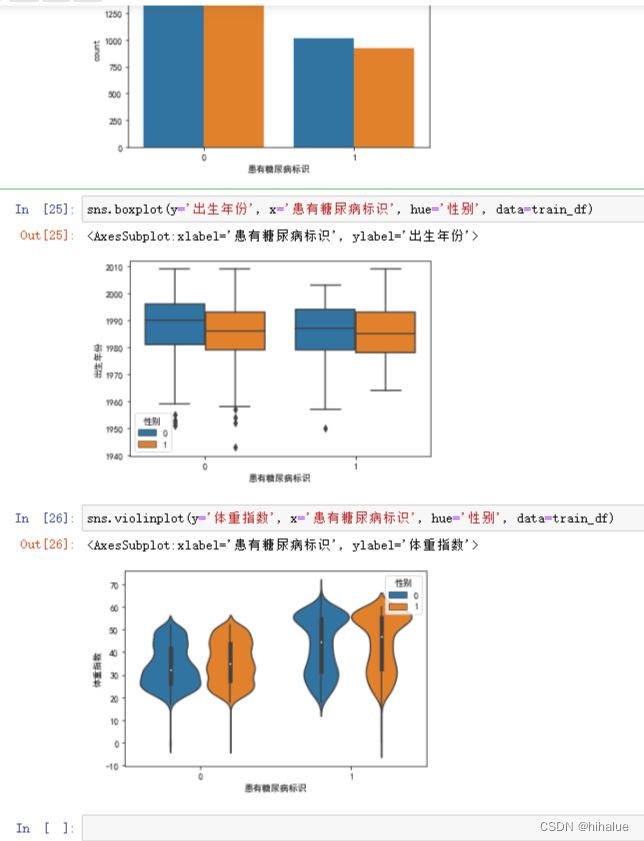
0708 end
今天先打卡前两个任务。