kaggle竞赛——桑坦德银行客户满意度预测(二)
桑坦德银行客户满意度预测
- 探索性数据分析(二)
-
- 分析带关键词前缀的特征
-
- var前缀特征
- imp特征
- saldo特征
- num特征
- ind特征
探索性数据分析(二)
分析带关键词前缀的特征
var前缀特征
在上一章中我们对主要的var特征进行过分析,现在我们可以看看var关键字特征有哪些
import re
[col for col in train.columns if col[:3] == 'var']
['var3', 'var15', 'var36', 'var21', 'var38', 'var15_below_23']
其中,var15_below_23是我们新创建的特征,代表用户是否小于23岁。那除了var关键字,是否还有其他的关键字呢?
f_keywords = {col.split('_')[0] for col in train.columns if (len(col.split('_')) > 1) &~ ('var15' in col)}#&~:满足前面但不满足后面
f_keywords
结果如下:
{'imp', 'ind', 'num', 'saldo'}
# 计算每种关键词前缀特征的计数
f_keywords = zip(f_keywords, np.zeros(len(f_keywords),dtype=int))
f_keywords = dict(f_keywords)
for key in f_keywords.keys():
for col in train.columns:
if key in col:
f_keywords[key] += 1
f_keywords
关键字及其包含特征数如下:
| key | value |
|---|---|
| ind | 32 |
| num | 64 |
| imp | 14 |
| saldo | 26 |
我们用直方图来直观的展示这个列表:
k = pd.Series(f_keywords)
ax = sns.barplot(x=k.index,y=k.values)
plt.title('特征关键词前缀的频数分布')
plt.ylabel('频数')
plt.xlabel('关键词前缀')
plt.show()
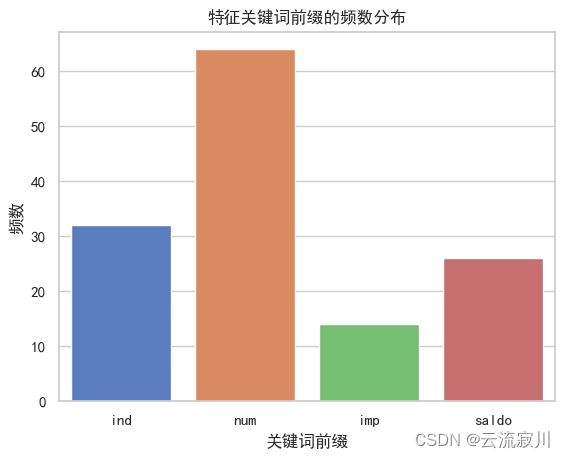
接下来我们先来分析特征最少的imp关键字特征。
imp特征
我们先来查看imp特征有哪些
imp = [col for col in train.columns if 'imp' in col]
imp
['imp_ent_var16_ult1',
'imp_op_var39_comer_ult1',
'imp_op_var39_comer_ult3',
'imp_op_var41_comer_ult1',
'imp_op_var41_comer_ult3',
'imp_op_var41_efect_ult1',
'imp_op_var41_efect_ult3',
'imp_op_var41_ult1',
'imp_op_var39_efect_ult1',
'imp_op_var39_efect_ult3',
'imp_op_var39_ult1',
'imp_aport_var13_hace3',
'imp_var43_emit_ult1',
'imp_trans_var37_ult1']
共有14个特征,由于逐一分析难度较大且同一关键字特征的分布应该存在共性,所以我们随机选取其中一个进行分析。
random.seed(a = 0)
print('被随机选择中的imp特征:%s' % (random.sample(imp,1)))
被随机选择中的imp特征:imp_trans_var37_ult1
接下来我们查询出特征的最小值和最大值,并绘制它的频数分布直方图。
col = 'imp_trans_var37_ult1'
print("训练集中 saldo_medio_var13_corto_ult3 最小值为:%i,最大值为:%i" % (train[col].min(), train[col].max()))
print("测试集中 saldo_medio_var13_corto_ult3 最小值为:%i,最大值为:%i" % (test[col].min(), test[col].max()))
# 绘制特定列的频数分布折线图
valuecounts_plot(train=train, test=test, col=col)
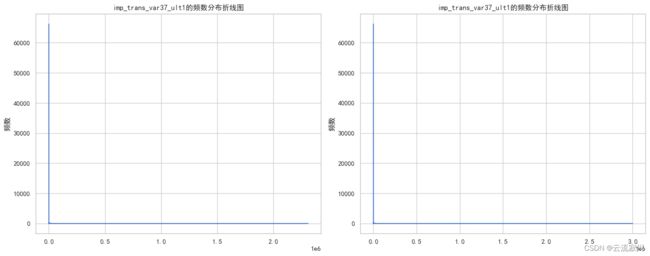
训练集特征'imp_trans_var37_ult1'其值占比(top 5):
值 占比%
0.0 87.069192
300.0 0.536701
600.0 0.420942
1500.0 0.361747
150.0 0.344646
Name: imp_trans_var37_ult1, dtype: float64
训练集特征'imp_trans_var37_ult1'其值占比(bottom 5):
值 占比%
2.37 0.001315
4171.68 0.001315
7881.96 0.001315
4740.00 0.001315
792.81 0.001315
Name: imp_trans_var37_ult1, dtype: float64
测试集特征'imp_trans_var37_ult1'其值占比(top 5):
值 占比%
0.0 87.235221
300.0 0.563191
600.0 0.465589
1500.0 0.391728
3000.0 0.319185
Name: imp_trans_var37_ult1, dtype: float64
测试集特征'imp_trans_var37_ult1'其值占比(bottom 5):
值 占比%
3309.84 0.001319
662.88 0.001319
2206.53 0.001319
5576.19 0.001319
10938.60 0.001319
Name: imp_trans_var37_ult1, dtype: float64
分析以上图表我们可以知道,大约87%的训练数据和测试数据都为0
由于大部分0值的存在,非0值的分布情况我们观察不清楚,所以接下来我们排除0值,将非0值的频数分布绘制出来
valuecounts_plot(train=train[train[col] != 0],test=test[test[col] != 0],col=col)
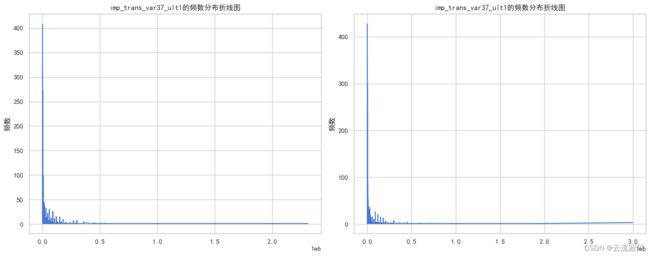
我们可以发现,对于该特征,绝大多数的非零值都在500000之内且非零值呈现出一定的右偏分布且其他的imp特征也有类似的规律。所以我们可以考虑:将imp特征的零值不变,非零值进行对数变换使之接近正态分布。
df = train[train[col] != 0]
df1 = test[test[col] != 0]
for data in [df, df1]:
data.loc[data[col] != 0, col] = np.log(data.loc[data[col] != 0, col])
hisplot_comb(col, train=df, test=df1)
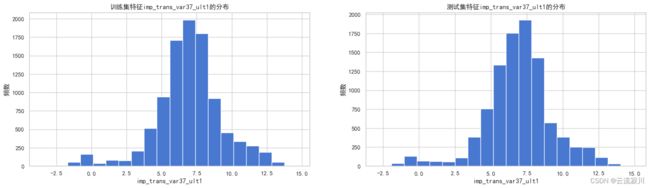
对数变换后,数据的分布好了很多 当特征imp_trans_var37_ult1 不为0时,经过对数变换,训练集和测试集数据均近似服从正态分布
saldo特征
我们还是先来查看saldo关键词特征列表
saldo = [col for col in train.columns if 'saldo' in col]
saldo
'saldo_var12',
'saldo_var13_corto',
'saldo_var13',
'saldo_var24',
'saldo_var26',
'saldo_var25',
'saldo_var30',
'saldo_var37',
'saldo_var42',
'saldo_medio_var5_hace2',
'saldo_medio_var5_hace3',
'saldo_medio_var5_ult1',
'saldo_medio_var5_ult3',
'saldo_medio_var8_hace2',
'saldo_medio_var8_ult1',
'saldo_medio_var8_ult3',
'saldo_medio_var12_hace2',
'saldo_medio_var12_hace3',
'saldo_medio_var12_ult1',
'saldo_medio_var12_ult3',
'saldo_medio_var13_corto_hace2',
'saldo_medio_var13_corto_hace3',
'saldo_medio_var13_corto_ult1',
'saldo_medio_var13_corto_ult3']
一共有26个特征,我们仍然随机选取一个
random.seed(a=77)
print('被随机选择的saldo特征:%s' % (random.sample(saldo,1)))
被随机选择的saldo特征:saldo_medio_var13_corto_ult3
通过对该特征进行如上分析,我们发现saldo类型特征呈现出与imp特征相似的零值占比大、非零值分布右偏的情况,因此这里我们可以对saldo特征采取和imp特征相同的处理方式。
num特征
我们还是先打印出包含num关键字的特征列表
num = [col for col in train.columns if 'num' in col]
print('包含前缀num的特征共有 %i 个' % (len(num)))
num[:10]
包含前缀num的特征共有 64 个,前10个为:
['num_var1_0',
'num_var4',
'num_var5_0',
'num_var5',
'num_var8_0',
'num_var8',
'num_var12_0',
'num_var12',
'num_var13_0',
'num_var13_corto_0']
和上面一样我们从中随机选取一个特征进行分析。
random.seed(a = 420)
print('被随机选择的num特征:%s ' % (random.sample(num,1)))
被随机选择的num特征:num_var5
col = 'num_var5'
print("训练集中 num_var5 最小值为:%i,最大值为:%i" % (train[col].min(), train[col].max()))
print("测试集中 num_var5 最小值为:%i,最大值为:%i" % (test[col].min(), test[col].max()))
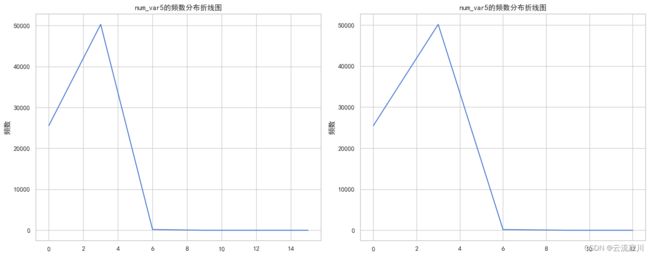
valuecounts_plot(train=train, test=test, col=col)
**************************************************************************************
训练集特征'num_var5'其值占比(top 5):
值 占比%
3 66.120758
0 33.624046
6 0.249934
9 0.003946
15 0.001315
Name: num_var5, dtype: float64
****************************************************************************************************
训练集特征'num_var5'其值占比(bottom 5):
值 占比%
3 66.120758
0 33.624046
6 0.249934
9 0.003946
15 0.001315
Name: num_var5, dtype: float64
测试集特征'num_var5'其值占比(top 5):
值 占比%
3 66.133372
0 33.625260
6 0.233454
9 0.006595
12 0.001319
Name: num_var5, dtype: float64
****************************************************************************************************
测试集特征'num_var5'其值占比(bottom 5):
值 占比%
3 66.133372
0 33.625260
6 0.233454
9 0.006595
12 0.001319
Name: num_var5, dtype: float64
我们可以看到,此特征只有5个唯一值,表明他是一个分类特征。并且他们都是3的倍数,其中3的出现次数最多,均占66%,我们发现15不出现在测试数据中,12不出现在训练数据中
接下来我们看看num_var5的唯一值分布情况和不满意客户在num_var5的分布情况:
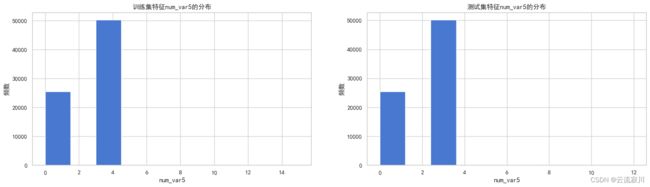
hisplot_comb(col=col,bins=10)
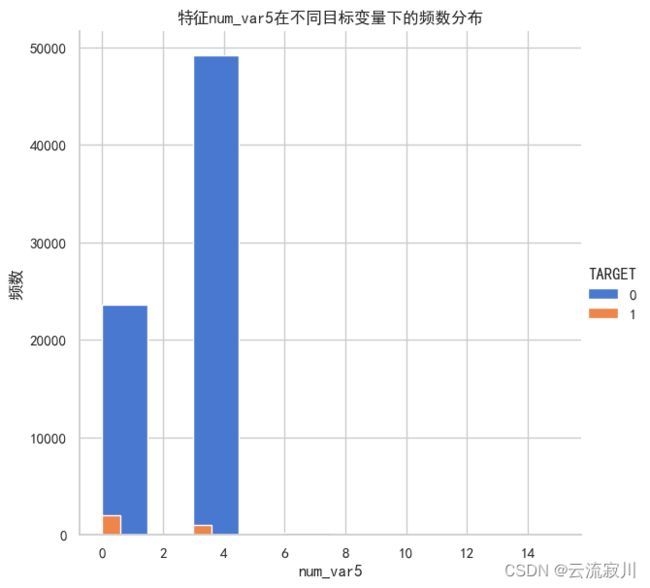
histplot_target(col=col, bins=10)
for i in train[col].unique():
print("当 '%s'==%i 时,不满意客户数量为:%i,其占比为:%.3f%%" %
(col, i, train[(train['TARGET'] == 1) & (train[col] == i)].shape[0],
train[(train['TARGET'] == 1) & (train[col] == i)].shape[0]*100 / train[train[col] == i].shape[0]))
当 'num_var5'==0 时,不满意客户数量为:1959,其占比为:7.664%
当 'num_var5'==3 时,不满意客户数量为:1042,其占比为:2.073%
当 'num_var5'==6 时,不满意客户数量为:7,其占比为:3.684%
当 'num_var5'==9 时,不满意客户数量为:0,其占比为:0.000%
当 'num_var5'==15 时,不满意客户数量为:0,其占比为:0.000%
我们可以发现,该特征中唯一值3和0占比最大,共达到了99%且唯一值0的不满意客户占比最多。
那么,既然num_var5是分类型特征,那其他的num型特征是否也为分类型特征呢?我们可以将所有的num型特征的唯一值输出出来看看。
for feat in num:
print("%s \t unique-values:%i \t dtype:%s" % (feat, train[feat].nunique(), train[feat].dtype))
num_var1_0 unique-values:3 dtype:int64
num_var4 unique-values:8 dtype:int64
num_var5_0 unique-values:5 dtype:int64
num_var5 unique-values:5 dtype:int64
num_var8_0 unique-values:3 dtype:int64
num_var8 unique-values:2 dtype:int64
num_var12_0 unique-values:6 dtype:int64
num_var12 unique-values:4 dtype:int64
num_var13_0 unique-values:7 dtype:int64
num_var13_corto_0 unique-values:3 dtype:int64
num_var13_corto unique-values:3 dtype:int64
num_var13_largo_0 unique-values:7 dtype:int64
num_var13 unique-values:7 dtype:int64
num_var14_0 unique-values:5 dtype:int64
num_var24_0 unique-values:4 dtype:int64
......
num_var45_ult1 unique-values:94 dtype:int64
num_var45_ult3 unique-values:172 dtype:int64
我们发现,num特征的唯一值从2到172不等,在7万多条样本的规模下,基本满足分类型变量的特点,对于分类问题,我们通常需要将分类变量进行编码处理,但是如果进行独热编码,对于具有较多唯一值的特征我们可能会新增172个新字段,过大的稀疏性同样会降低分类效果。因此,我们设置一个阈值10,当num特征的nunique()小于10的时候,我们选择将它编码,如果大于10,我们选择不作处理。
ind特征
同样先查看特征列表
ind = [col for col in train.columns if 'ind' in col]
print("关键词前缀ind特征共有 %i 个" % (len(ind)))
ind[:10]
ind特征共有32个,其中10个为:
['ind_var1_0',
'ind_var5_0',
'ind_var5',
'ind_var8_0',
'ind_var8',
'ind_var12_0',
'ind_var12',
'ind_var13_0',
'ind_var13_corto_0',
'ind_var13_corto']
我们随机选取一个特征进行分析:ind_var5_0
输出他的最小值和最大值并绘制频数分布折线图:
col = 'ind_var5_0'
print("训练集中 ind_var5_0 最小值为:%i,最大值为:%i" % (train[col].min(), train[col].max()))
print("测试集中 ind_var5_0 最小值为:%i,最大值为:%i" % (test[col].min(), test[col].max()))
valuecounts_plot(train=train, test=test, col=col)
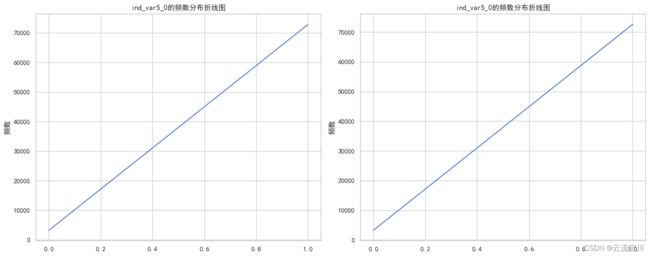
我们可以发现,该特征是一个分类型变量且只有两个值0和1,且1占比绝大部分,约为96%,我们再看看不满意客户在唯一值中的分布情况。
histplot_target(col=col, bins=10)
for i in train[col].unique():
print("当 '%s'==%i 时,不满意客户数量为:%i,其占比为:%.3f%%" %
(col, i, train[(train['TARGET'] == 1) & (train[col] == i)].shape[0],
train[(train['TARGET'] == 1) & (train[col] == i)].shape[0]*100 / train[train[col] == i].shape[0]))
当 'ind_var5_0'==1 时,不满意客户数量为:2784,其占比为:3.823%
当 'ind_var5_0'==0 时,不满意客户数量为:224,其占比为:7.020%
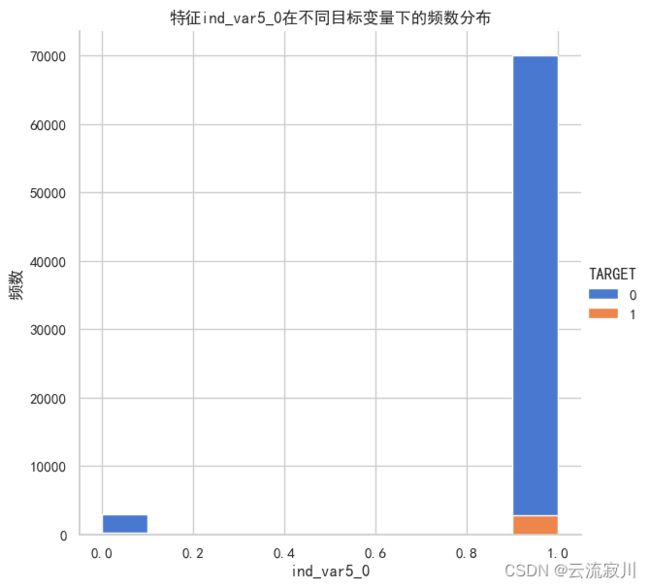
通过nunique()我们可以得知,所有的ind特征均为二分类特征。因此,我们可以不对ind特征进行处理。
最终这一阶段我们得到的训练集和测试集的shape为:
((76020, 144), (75818, 143))
我们将df保存为pickle文件,这种文件的读取速度比csv文件更快。
train.to_pickle('./data/santander-customer-satisfaction/output/train.pkl')
test.to_pickle('./data/santander-customer-satisfaction/output/test.pkl')