自制深度学习推理框架-BAT C++面试官必知必会-第三课-实现我们的第一个算子ReLu
自制深度学习推理框架-起飞!实现我们的第一个算子ReLu
我们的课程主页
https://github.com/zjhellofss/KuiperInfer 欢迎pr和点赞
本期视频位置
请务必配合视频一起学习该课件. 视频地址
本期代码位置
git clone https://gitee.com/fssssss/KuiperCourse.git
git checkout fouth
ReLu算子的介绍
ReLu是一种非线性激活函数, 它有运算简单, 不会在边缘处出现梯度消失的特点, 而且它在一定程度上能够防止深度学习模型在训练中发生的过拟合现象. ReLu的公式表达如下所示, 如果对于深度学习基本概念不了解的同学, 可以将ReLu当作一个公式进行对待, 不用深究其背后的含义.
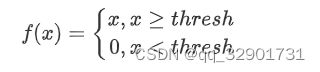
我们今天的任务就是来完成这个公式中的操作, 值得注意的是, 在我们的项目中, x和f(x)可以理解为我们在第二、第三节中实现的张量类(Tensor). 完整的Tensor定义可以看我们的上游项目, 代码链接
Operator类
Operator类就是我们在第一节中说过的计算图中计算节点或者说操作符的概念, 计算图的另外一个组成是数据流图. 一个规定了数据是怎么流动的, 另外一个规定了数据到达某个节点后是怎么进行运算的.
在我们的代码中先定义一个Operator类, 它是一个父类, 其余的Operator包括我们本节要实现的ReLuOperator都是其派生类.Operator类中会存放计算节点相关的参数, 例如在ConvOperator中就会存放初始化卷积算子所需要的stride, padding, kernel_size等参数, 而本节的ReLuOperator就会带有thresh值.
我们从下方的代码中来了解Operator类和ReLuOperator类, 它们是父子关系, Operator是基类, OpType记录Operator的类型.
值得注意的是计算图中的具体计算操作并不放在Operator类中执行, 而是根据Operator中存放的参数去初始化对应的Layer, 在ReLuOperator中记录了初始化ReLuLayer运行所需要的thresh.
整体的执行关系是这样的
- 根据模型文件来定义
operator,并将相关的参数存放在operator中 - 根据
operator中存放的参数, 去初始化对应的Layer - 获取输入数据,
Layer进行运算
enum class OpType {
kOperatorUnknown = -1,
kOperatorReLu = 0,
};
class Operator {
public:
OpType kOpType = OpType::kOperatorUnknown;
virtual ~Operator() = default;
explicit Operator(OpType op_type);
};
ReLuOperator实现:
class ReLuOperator : public Operator {
public:
~ReLuOperator() override = default;
explicit ReLuOperator(float thresh);
void set_thresh(float thresh);
float get_thresh() const;
private:
float thresh_ = 0.f;
};
Layer类
我们会在Operator类中存放从计算图结构文件得到的信息, 例如在ReLuOperator中存放的thresh值作为一个参数, 这个参数就是我们从计算图结构文件中得到的.
下一步我们需要根据ReLuOperator类去完成ReLuLayer的初始化, 他们的区别在于ReLuOperator负责存放从计算图中得到的计算节点参数信息, 不负责计算. 而ReLuLayer则负责具体的计算操作. 同样, 所有的Layer类有一个公共父类Layer. 我们可以从下方的代码中来了解两者的关系.
class Layer {
public:
explicit Layer(const std::string &layer_name);
virtual void Forwards(const std::vector<std::shared_ptr<Tensor<float>>> &inputs,
std::vector<std::shared_ptr<Tensor<float>>> &outputs);
virtual ~Layer() = default;
private:
std::string layer_name_;
};
其中Layer的Forwards方法是具体的执行函数, 负责将输入的inputs中的数据, 进行ReLu运算并存放到对应的outputs中.
class ReLuLayer : public Layer {
public:
~ReLuLayer() override = default;
explicit ReLuLayer(const std::shared_ptr<Operator> &op);
void Forwards(const std::vector<std::shared_ptr<Tensor<float>>> &inputs,
std::vector<std::shared_ptr<Tensor<float>>> &outputs) override;
private:
std::shared_ptr<ReLuOperator> op_;
};
这是继承于Layer的ReLuLayer类, 我们可以看到其中有一个op成员, 是一个ReLuOperator指针, 这个指针指向的operator中负责存放ReLuLayer计算时所需要用到的一些参数. 此处op_存放的参数比较简单, 只有ReLuOperator中的thresh参数.
我们再看看是怎么使用ReLuOperator去初始化ReLuLayer的, 先通过统一接口传入Operator类, 再转换为对应的ReLuOperator派生类指针, 最后再通过指针中存放的信息去初始化op_.
ReLuLayer::ReLuLayer(const std::shared_ptr<Operator> &op) : Layer("ReLu") {
CHECK(op->kOpType == OpType::kOperatorReLu);
ReLuOperator *ReLu_op = dynamic_cast<ReLuOperator *>(op.get());
CHECK(ReLu_op != nullptr);
this->op_ = std::make_shared<ReLuOperator>(ReLu_op->get_thresh());
}
我们来看一下具体ReLuLayer的Forwards过程, 它在执行具体的计算, 完成ReLu函数描述的功能.
void ReLuLayer::Forwards(const std::vector<std::shared_ptr<Tensor<float>>> &inputs,
std::vector<std::shared_ptr<Tensor<float>>> &outputs) {
CHECK(this->op_ != nullptr);
CHECK(this->op_->kOpType == OpType::kOperatorReLu);
const uint32_t batch_size = inputs.size();
for (int i = 0; i < batch_size; ++i) {
CHECK(!inputs.at(i)->empty());
const std::shared_ptr<Tensor<float>>& input_data = inputs.at(i);
input_data->data().transform([&](float value) {
float thresh = op_->get_thresh();
if (value >= thresh) {
return value;
} else {
return 0.f;
}
});
outputs.push_back(input_data);
}
}
在for循环中, 首先读取输入input_data, 再对input_data使用armadillo自带的transform依次遍历其中的元素, 如果value的值大于thresh则不变, 如果小于thresh就返回0. 最后, 我们写一个测试函数来验证我们以上的两个类, 节点op类和计算层layer类的正确性.
实验环节
先判断Forwards返回的outputs是否已经保存了ReLu层的输出, 输出大小应该assert为1. 随后再进行比对, 我们应该知道在thresh等于0的情况下, 第一个输出index(0)和第二个输出index(1)应该是0, 第三个输出应该是3.f.
TEST(test_layer, forward_ReLu) {
using namespace kuiper_infer;
float thresh = 0.f;
std::shared_ptr<Operator> ReLu_op = std::make_shared<ReLuOperator>(thresh);
std::shared_ptr<Tensor<float>> input = std::make_shared<Tensor<float>>(1, 1, 3);
input->index(0) = -1.f;
input->index(1) = -2.f;
input->index(2) = 3.f;
std::vector<std::shared_ptr<Tensor<float>>> inputs;
std::vector<std::shared_ptr<Tensor<float>>> outputs;
inputs.push_back(input);
ReLuLayer layer(ReLu_op);
layer.Forwards(inputs, outputs);
ASSERT_EQ(outputs.size(), 1);
for (int i = 0; i < outputs.size(); ++i) {
ASSERT_EQ(outputs.at(i)->index(0), 0.f);
ASSERT_EQ(outputs.at(i)->index(1), 0.f);
ASSERT_EQ(outputs.at(i)->index(2), 3.f);
}
}