87.序列到序列学习(seq2seq)以及代码实现
1. 机器翻译

2. Seq2Seq

双向RNN可以做encoder,但不能做decoder。
3. 编码器-解码器细节

4. 训练
5. 衡量生成序列的好坏的BLEU
上面的公式既加入了段序列的惩罚项,又加入了更难出现的长序列的高权重。
6. 总结:
- Seq2seq从一个句子生成另一个句子
- 编码器和解码器都是RNN
- 将编码器最后时间隐状态来初始解码器隐状态来完成信息传递
- 常用BLEU来衡量生成序列的好坏
7. 代码实现
下面,我们动手构建 seq2seq的设计, 并将基于“英-法”数据集来训练这个机器翻译模型。
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
7.1 编码器
现在,来实现循环神经网络编码器。 注意,我们使用了嵌入层(embedding layer) 来获得输入序列中每个词元的特征向量。 嵌入层的权重是一个矩阵, 其行数等于输入词表的大小(vocab_size), 其列数等于特征向量的维度(embed_size)。 对于任意输入词元的索引 , 嵌入层获取权重矩阵的第 行(从 0 开始)以返回其特征向量。 另外,本文选择了一个多层门控循环单元来实现编码器。
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
# embed是word2vec的思想,把字典里one-hot编码的字或者词,变成预训练(可能需要微调)的词向量
# embed就是将word映射到向量空间
self.embedding = nn.Embedding(vocab_size, embed_size)
# 第一个参数是inputs大小,在之前一些代码中传入的是vocab_size或者len(vocab),是词表的大小
# 但是在这里因为使用了nn.Embedding将词表的大小改变成了embed_size,再作为输入
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
# 把batch_size换到中间,把num_steps换到第一个轴
# 转换为(时间步数量,批量大小,词表大小)
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
# 输出output是每一个时间步的最后一层RNN的输出,根据图去理解,最后一层RNN往上的输出
# state: 在最后一个时刻所有的层的输出,根据图去理解,是每一层最右边的输出
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
下面,我们实例化上述编码器的实现: 我们使用一个两层门控循环单元编码器,其隐藏单元数为 16 。 给定一小批量的输入序列X(批量大小为 4 ,时间步为 7 )。 在完成所有时间步后, 最后一层的隐状态的输出是一个张量(output由编码器的循环层返回), 其形状为(时间步数,批量大小,隐藏单元数)。
Pytorch:model.train()和model.eval()用法和区别,以及model.eval()和torch.no_grad()的区别
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval() # 在eval模式下,dropout不会生效
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
output.shape
运行结果:
![]()
由于这里使用的是门控循环单元, 所以在最后一个时间步的多层隐状态的形状是 (隐藏层的数量,批量大小,隐藏单元的数量)。 如果使用长短期记忆网络,state中还将包含记忆单元信息。
state.shape
运行结果:

7.2 解码器
当实现解码器时, 我们直接使用编码器最后一个时间步的隐状态来初始化解码器的隐状态。 这就要求使用循环神经网络实现的编码器和解码器具有相同数量的层和隐藏单元。 为了进一步包含经过编码的输入序列的信息,上下文变量在所有的时间步与解码器的输入进行拼接(concatenate)。 为了预测输出词元的概率分布, 在循环神经网络解码器的最后一层使用全连接层来变换隐状态。
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
# decoder在模型上和encoder是一样的
# decoder有自己的embedding层,不能和encoder共享,因为词汇都不一样
self.embedding = nn.Embedding(vocab_size, embed_size)
# 这里的输入是embed_size + num_hiddens
# 并且假设了encoder隐藏层大小和decoder的隐藏层大小一样
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
# decoder有输出层
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
# enc_outputs是output、state
# enc_outputs[1] 就是encoder输出的state
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# context是上下文信息
# state是最后一个时刻的所有RNN层的隐藏状态,也就是图中最后一竖的H
# state[-1]就是最后一个时刻的最后一层RNN的输出,也就是图中右上角的H
# 那个右上角的H包括了所有浓缩的信息,把它拿到之后,重复几次,
# 重复成decoder输入的长度,每个时刻都重复一次
# 广播context,使其具有与X相同的num_steps
# 从另一个角度理解为:repeat操作增加通道数,这里把二位矩阵扩充到三维,增加了seq维
context = state[-1].repeat(X.shape[0], 1, 1)
# decoder中RNN的输入是当前embedding的输出加上encoder传过来的上下文信息,
# 虽然state已经传过来了,但是觉得不够,还要把最后那个时刻context和embedding拼在一起作为输入
# 这也是为什么decoder的RNN的输入是embed_size + num_hiddens
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
下面,我们用与前面提到的编码器中相同的超参数来实例化解码器。 如我们所见,解码器的输出形状变为(批量大小,时间步数,词表大小), 其中张量的最后一个维度存储预测的词元分布。
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
# 输出形状为(批量大小,时间步数,词表大小)
# 对每一个样本的每一个时刻都做一个输出
# state的形状为(层数,批量大小,隐藏层大小)
output.shape, state.shape
运行结果:
![]()
7.3 损失函数
在每个时间步,解码器预测了输出词元的概率分布。 类似于语言模型,可以使用softmax来获得分布, 并通过计算交叉熵损失函数来进行优化。 回想一下machine_translation中, 特定的填充词元被添加到序列的末尾, 因此不同长度的序列可以以相同形状的小批量加载。 但是,我们应该将填充词元的预测排除在损失函数的计算之外。
为此,我们可以使用下面的sequence_mask函数 ,通过零值化屏蔽不相关的项, 以便后面任何不相关预测的计算都是与零的乘积,结果都等于零。 例如,如果两个序列的有效长度(不包括填充词元)分别为 1 和 2 , 则第一个序列的第一项和第二个序列的前两项之后的剩余项将被清除为零。
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
我们还可以使用此函数屏蔽最后几个轴上的所有项。如果愿意,也可以使用指定的非零值来替换这些项。
X = torch.ones(2, 3, 4)
sequence_mask(X, torch.tensor([1, 2]), value=-1)
现在,我们可以通过扩展softmax交叉熵损失函数来遮蔽不相关的预测。 最初,所有预测词元的掩码都设置为1。 一旦给定了有效长度,与填充词元对应的掩码将被设置为0。 最后,将所有词元的损失乘以掩码,以过滤掉损失中填充词元产生的不相关预测。
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
# 生成和label形状一样全1的矩阵
weights = torch.ones_like(label)
# 把有效的长度保留下来,其他变为0
weights = sequence_mask(weights, valid_len)
# reduction定义为none,就不会对loss求和或者求平均
self.reduction='none'
# 这里loss调用的是父类函数,其实super中的内容可以删掉
# 在pytorch中的MaskedSoftmaxCELoss规定要把vocab_size放在第2个维度
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
# unweighted_loss * weights 会使得有效的地方留下来,其他为0
# dim=1,就是对每个句子取平均
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
我们可以创建三个相同的序列来进行代码健全性检查, 然后分别指定这些序列的有效长度为 4 、 2 和 0 。 结果就是,第一个序列的损失应为第二个序列的两倍,而第三个序列的损失应为零。
loss = MaskedSoftmaxCELoss()
# 3是批量大小,4是时间步数,10是每个单词向量的维度
# torch.tensor([4, 2, 0]:第一个样本所有都是valid,第二个样本只有前两个是valie
# 最后一个样本全都不是valid
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long),
torch.tensor([4, 2, 0]))
运行结果:
![]()
7.4 训练
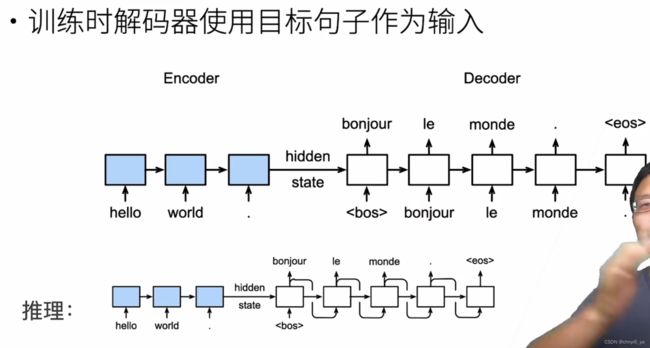
在下面的循环训练过程中, 特定的序列开始词元(“< bos>”)和 原始的输出序列(不包括序列结束词元“< eos>”) 拼接在一起作为解码器的输入。 这被称为强制教学(teacher forcing), 因为原始的输出序列(词元的标签)被送入解码器。 或者,将来自上一个时间步的预测得到的词元作为解码器的当前输入。
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
# net就是encoder-decoder
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
# batch中有源句子,源句子的valid_len,目标句子,目标句子的valid_len
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
# bos:begin of sentence:源句子要翻译需要这个标志
bos = torch.tensor([tgt_vocab['' ]] * Y.shape[0],
device=device).reshape(-1, 1)
# dec_input 就是吧bos和Y(target)里面的除最后一项组合在一起
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
# net的输入是编码器输入、解码器输入、编码器有效长度
Y_hat, _ = net(X, dec_input, X_valid_len)
# 计算loss的时候,因为y的填充不要算loss,所以传入Y_valid_len告诉非填充部分
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
现在,在机器翻译数据集上,我们可以 创建和训练一个循环神经网络“编码器-解码器”模型用于序列到序列的学习。
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10 # 句子长度为10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)
# 用encoder和decoder做出net
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
运行结果:
训练的速度很快,是因为encoder和decoder都是一个RNN,长度为10,总共就2个RNN;也能看做是一个长度为20的RNN。

7.5 预测
为了采用一个接着一个词元的方式预测输出序列, 每个解码器当前时间步的输入都将来自于前一时间步的预测词元。 与训练类似,序列开始词元(“< bos>”) 在初始时间步被输入到解码器中。 该预测过程如 图所示, 当输出序列的预测遇到序列结束词元(“< eos>”)时,预测就结束了。

使用循环神经网络编码器-解码器逐词元地预测输出序列。
# 之前训练的时候,在做解码器的输入和输出时,输入用的是+真实的target句子
# 而预测的时候我们是不知道真实句子的,所以会有区别
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
# 把 源句子+ 转换为idx
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['' ]]
# 有效长度
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
# 对源句子进行填充和截取
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['' ])
# 添加批量轴
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
# 至此,以上代码都是encoder部分
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
# 这里和之前有区别,之前给的是+目标句子,而在这里,就是给
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['' ]], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps): # 预测n步
# 每一步都往decoder中放入dec_X和dec_state
# 第一次循环的dec_X就是' ]:
break
# 没有预测结束,就把预测结果放入output_seq
output_seq.append(pred)
# 把预测的output_seq通过to_tokens把token(词元)查出来,并且用空格拼接,就能变成一句话了
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
7.6 预测序列的评估

BLEU的代码实现如下:
def bleu(pred_seq, label_seq, k):
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
# 公式的第一部分
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1): # n-gram,从1一直算到k元语法
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
最后,利用训练好的循环神经网络“编码器-解码器”模型, 将几个英语句子翻译成法语,并计算BLEU的最终结果。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
运行结果:

这节课整个过程可以理解为(个人理解,有问题欢迎指正)【摘自b站评论】:
1.获得训练集样本,将样本转化为embeding矩阵,每一个embeding向量对应一个词,embeding向量的种类有vocab_size个,这些embeding向量重复累积构成了整个文本(二维张量)。代码中的输入X是(batch_size,num_steps,embed_size)意义即:每个词用一个embeding向量表示,这个向量的维度为embed_size,每个时间步有num_steps个词,取batch_size个批量。
2.确定超参数时间步s,时间步长度即为单次输入(英语)和输出(法语)的最大数量。
3.确定批量b,这里是为了优化,以便训练时更快更好地迭代收敛。
4.每次选取b组长度为s的样本,这些样本在encoder中前向传递最终得到一个H,把H和对应的法语张量合并共同作为decoder的输入,后续像rnn一样前向传递,即:将当前词和此时的状态共同作为输入来预测下一个词。
5.预测完成后将output和实际文本对应的张量进行交叉熵计算,计算时只取有效长度避免出现多余的损失值。
6.训练完成后即可输入英语,把输出结果累积得到英语对应的法语翻译,并用bleu衡量翻译的好坏。
8. Q&A
Q1:encoder输出和decoder的输入,拼接和按位相加起来有什么区别吗?
A1: 不能按位加,因为decoder的输入是 embedding size,而encoder的输出是hidden size,上面的代码是取的一样的值,但实际上不能这么做,因为长度不一样。
Q2: 实际句子的长度超过了设定的句子长度,是直接截掉不用还是放到下一个句子?
A2: 截掉不用