python学习笔记:opencv的图像操作
什么是opencv?
opencv是一个开源的计算机视觉库,可以在http://opencv.org获取,opencv库用C,C++,python等多种语言编写,在使用中,经常用opencv打开存储器的图像,对摄像头的图像进行捕捉并保存或者对图像进行预处理,以实现图像更好的额完成算法分类,应用领域很广:在人机互动,物体识别,图像分割,人脸识别,动作识别,运动跟踪,机器人,运动分析,机器视觉,汽车安全驾驶等方面都有涉及。
图像像素的存储形式?
1.对于只有黑白颜色的灰度图,为单通道,一个像素块对应矩阵中一个数字,数值为0-255,0表示最暗(黑色),255表示最亮(白色)
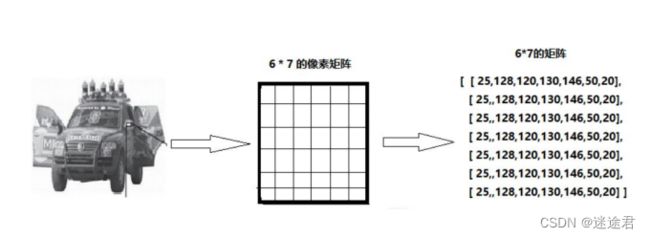
2.对于采用RGB模式的彩色图片,则为三通道图,RED,GREEN,BLUE三原色,按照不同比例相加,一个像素块对应矩阵中一个向量
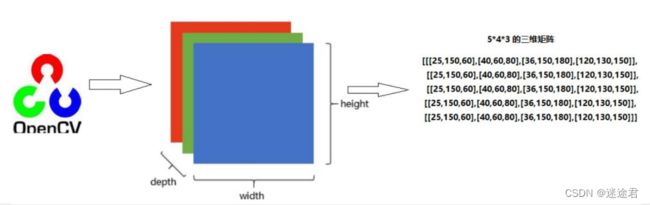
注意:
彩色图像的三维矩阵
第一轴轴长:图片宽度
第二轴轴长:图片高度
第三轴轴长:图片深度opencv采用BGR模式,而不是RGB所以
第一轴轴长:图片高度
第二轴轴长:图片宽度
第三轴轴长:图片深度
opencv操作图像

1.读取图像,并显示
import cv2
# 读取本地某个路径下的图片文件,返回值为numpy中的ndarray类型
img = cv2.imread("1.JPG")
print(type(img))
print(img.shape)
# 显示img对象中的图片
cv2.imshow("1", img)
# 阻塞等待任意按键按下,再退出;参数代表永久阻塞
# 返回值表示按下按键的key值
cv2.waitKey(0)
# 退出时销毁该窗口
cv2.destroyAllWindows()2.图片的变换
在人工智能对图片进行处理时提取特征值时往往需要灰度图,所以我们需要对图片进行一些处理。
"""
2.图片的变换
"""
img = cv2.imread("1.JPG")
print(type(img))
print(img.shape)
cv2.imshow("1", img)
# 由于img为彩色图像数据,而人工智能特征值提取,需要灰度图
# 将 bgr格式的彩图转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# resize():改变图片大小,实质是压缩
gray = cv2.resize(gray, (480, 640))
print(gray)
print(gray.shape)
cv2.imshow("2", gray)
cv2.waitKey(0)
cv2.destroyAllWindows()
3.图像截取,抠图
图像截图抠图本质上也是对图像对应的numpy数组进行索引切片得到相应的部分
"""
3.图像截取,抠图
"""
img = cv2.imread("1.JPG")
print(type(img))
print(img.shape)
cv2.imshow("1", img)
# # 索引切片进行抠图
eyes = img[480: 480+94, 640: 640+118, :]
cv2.imshow("2", eyes)
# # 将图片数据写入本地文件
cv2.imwrite("eyes.jpg", eyes)
cv2.waitKey(0)
cv2.destroyAllWindows()4.opencv操作摄像头

import cv2
"""
4.opencv操作摄像头
"""
# 打开摄像头0
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("摄像头未打开")
exit(0)
while True:
# 读取一帧图片
ret, img = cap.read()
print(img)
cv2.imshow("1", img)
if cv2.waitKey(50) == 27:
break
cv2.destroyAllWindows()5.opencv操作摄像头,显示文字,画框
putText()
参数1:图片数据对象
参数2:显示的文本数据
参数3:文本显示位置参数4:文本字体样式
参数5:字体的大小参数6:字体的颜色rgb
参数7:文字的线条粗细rectangle():绘制矩形框
"""
5.opencv操作摄像头,显示文字,画框
"""
import time
# # 打开摄像头0
time_start = time.time()
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("摄像头未打开")
exit(0)
while True:
# 读取一帧图片
ret, img = cap.read()
# 参数1:图片数据对象 参数2:显示的文本数据
# 参数3:文本显示位置 参数4:文本字体样式
# 参数5:字体的大小 参数6:字体的颜色rgb
# 参数7:文字的线条粗细
cv2.putText(img, "FPS", (240, 320), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color=(0, 123, 220), thickness=2)
# 绘制矩形框,pt1:矩形框左下角点坐标,pt2矩形框右下角点坐标
cv2.rectangle(img, pt1=(270, 190), pt2=(370, 290), color=(0, 0, 0), thickness=5)
cv2.imshow("1", img)
if cv2.waitKey(50) == 27:
break
cv2.destroyAllWindows()6.opencv人脸检测
path是我们使用人脸检测库文件的文件路径位置,通过库的支持我们将每一帧的图片进行比对得到人脸的坐标,然后通过绘制矩形,达到人脸识别的效果。
"""
6.opencv人脸检测
"""
path = 'D:\\anaconda\\envs\\tf\\Library\\etc\\haarcascades\\haarcascade_frontalface_default.xml'
model = cv2.CascadeClassifier(path)
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("摄像头未打开")
exit(0)
while True:
ret, img = cap.read()
print(img.shape)
# 由于该模型,要求图片必须是灰度图,所以必须转换
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 将灰度图送入模型进行检测,返回列表,列表中元素为每个人脸的位置信息【x, y, w, h】
facelist = model.detectMultiScale(gray)
if len(facelist) < 0:
print("未检测到")
cv2.waitKey(100)
break
print(facelist)
for i in facelist:
x, y, w, h = i
cv2.rectangle(img, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 0), thickness=2)
cv2.imshow("1", img)
if cv2.waitKey(50) == 27:
break
cv2.destroyAllWindows()