编译原理语义分析代码_Cycle GAN原理分析与代码解读

写这篇文章花了好久。
原理分析:
图片生成领域是GAN网络的天下,最近很多人将GAN网络应用到了图像风格迁移领域。这篇论文也是做image to image translation,之前已经有较为成功的网络Pix2Pix了(同一个团队做的),本篇论文的出发点和Pix2Pix的不同在于:
Pix2Pix网络要求提供image pairs,也即是要求提供x和y,整个思路为:从噪声z,根据条件x,生成和真实图片y相近的y’。条件x和图像y是具有一定关联性的。
而本篇CycalGAN不要求提供pairs,如题目所说:Unpaired。因为成对的图像数据集其实并不多。这里的x和y不要求有什么较好的关联性,可以是毫不相干的两幅图像。

Method:
Adversarial loss:
普通的GAN损失:
这个损失函数里面x和y分别是2个不同领域的image,
按照传统GAN的思路,优化目标就变为了:
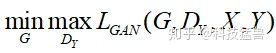
但单纯的使用这一个损失是无法进行训练的。原因在于,映射F完全可以将所有x都映射到y空间的同一张图片,使损失无效化。为此提出循环GAN网络。从域x生成域y,再从y生成回x,循环往复。
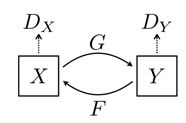
再使用一个生成器,命名为
整个过程如下图所示:
Cycle consistency loss:
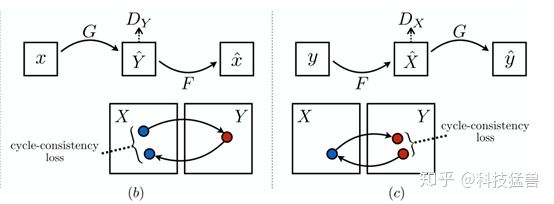
仅仅使用这两个对称的GAN网络还是不够的,因为G或者F可以把输入图片映射为输出域里面的任何一张图片,而不是针对输入图片的。所以仅仅使用上述的损失函数不足以生成风格迁移之后的图片。
CycleGAN的核心理念是,如果有一个图像风格转换器 G 可以将 X 域的图片转换为 Y 域的风格,而 F 可以将 Y 域的图片转换为 X 域的风格,那么 G 和 F 应该是互逆的。也就是说, X 域的图片经过 G 转换为Y域的之后,Y 域的应该可以通过 F 转换为 X域的。为了实现这一个Cycle Consistency,论文使用了一个Cycle Consistency Loss :

所以,总的损失函数为:
我们希望得到:
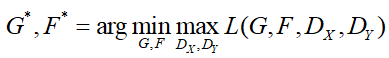
这里需要说明的是我们相当于是训练了2个 'Auto-encoder',每一个'Auto-encoder'把一幅图片从一个域转化到另一个域中。

实现细节:
为了稳定模型的训练,作者使用了2项技术:
1. 把对数损失函数变为least-squares loss。
2. 对于GAN的损失函数,训练G的时候损失函数为
训练D的时候损失函数为:
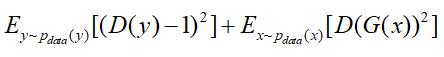
3. 最重要的一点:作者在实验中发现再添加一项损失:
添上这个损失之后,生成的图片奇迹般地效果更好了:

作者也做了一些解释:如果不加这项损失,G和F会改变原图的色调,如上图所示的那样。在学习Monet画作和Flickr照片之间的映射时,生成器经常将白天的画作映射到日落时拍摄的照片,因为这样的映射在adversarial loss和cycle loss下可能同样有效。
其他参数为:
Batch size=1
优化器:Adam
Lamda=10
评价指标:
这篇论文的evaluation metrics来自pix2pix的paper。传统的per-pixel mean-squared error无法评估结构性损失,所以无法准确地评价visual quality。于是作者采用以下的指标:
1. AMT perceptual studies
这个指标是基于Amazon Mechanical Turk (AMT)这个平台来评估实验结果的。把一张真图和一张假图称为“1个pair”,先给25个参与者每个人练习10个pair,告诉他们结果。具体的练习方法是每张图片展示1秒,之后参与者回答哪个图片是假图。再测试40个pair,以评估哪个算法能更好地欺骗受试者。
2. FCN score
这个指标是针对cityspace数据集,任务具体是把labels转换为photos,如下图所示。

这个指标背后的思想是:如果生成的图像是真实的,那么训练在真实图像上的分类器也能够正确地对合成图像进行分类。为此,我们采用流行的FCN-8s[39]结构进行语义分割。
把生成的图片通过FCN,FCN预测generated photo的labels。然后,可以使用语义分割的metrics将该标签映射与输入地面真值标签进行比较。语义分割metrics如下面所示。
3. 语义分割metrics
- per-pixel accuracy
- per-class accuracy
- mean class Intersection-Over-Union (Class IOU)
Baselines:
CoGAN:也是风格迁移的网络,从X到Y的转换可以通过找到生成图像X的latent representation,然后将该潜在表示渲染为样式Y来实现。
SimGAN:使用adversarial loss进行风格迁移。
Pix2Pix:是基于成对数据进行训练的,以了解在不使用任何成对数据的情况下,我们能多接近这个“上限”。
实验结果:

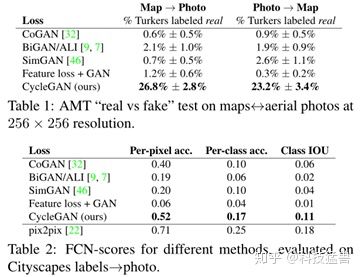
Cycle-GAN可以在四分之一的试验中欺骗参与者,而且FCN-scores更加接近Pix2Pix的upper bound,而且远超baseline。
Ablation study:
上文我们已经看到作者使用的损失函数是:

这里消融实验是去掉损失函数的某一项,看看结果有什么变化。
这里的GAN Forward Loss是指:
GAN backward Loss是指:
结果如下:
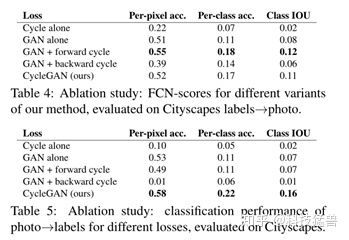

Image reconstruction quality:
对比了

代码解读:
1.models.py:
初始化函数:
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)Residual Block:
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
)
def forward(self, x):
return x + self.block(x)模型定义:
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0]
# Initial convolution block
out_features = 64
model = [
nn.ReflectionPad2d(channels),
nn.Conv2d(channels, out_features, 7),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Downsampling
for _ in range(2):
out_features *= 2
model += [
nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Residual blocks
for _ in range(num_residual_blocks):
model += [ResidualBlock(out_features)]
# Upsampling
for _ in range(2):
out_features //= 2
model += [
nn.Upsample(scale_factor=2),
nn.Conv2d(in_features, out_features, 3, stride=1, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Output layer
model += [nn.ReflectionPad2d(channels), nn.Conv2d(out_features, channels, 7), nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# Calculate output shape of image discriminator (PatchGAN)
self.output_shape = (1, height // 2 ** 4, width // 2 ** 4)
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1)
)
def forward(self, img):
return self.model(img)Generator:
模型一上来就是3个“卷积块”,每个卷积块包含:一个2D卷积层,一个Instance Normalization层和一个ReLU。这3个“卷积块”是用来降采样的。
然后是6个“残差块”,每个残差块包含2个卷积层,每个卷积层后面都有一个Instance Normalization层,第一个Instance Normalization层后面是ReLU激活函数,这些使用残差连接。
然后过2个“上采样块”,每个块包含一个2D转置卷积层,1个Instance Normalization和1个ReLU激活函数。
最后一层是一个2D卷积层,使用tanh作为激活函数,该层生成的形状为(128,128,3)的图像。
这个Generator的输入和输出的大小是一摸一样的,都是(128,128,3)。
Discriminator:
判别网络的架构类似于PatchGAN中的判别网络架构,是一个包含几个卷积块的深度卷积神经网络。
2.datasets.py:
import glob
import random
import os
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
def to_rgb(image):
rgb_image = Image.new("RGB", image.size)
rgb_image.paste(image)
return rgb_image
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, unaligned=False, mode="train"):
self.transform = transforms.Compose(transforms_)
self.unaligned = unaligned
self.files_A = sorted(glob.glob(os.path.join(root, "%s/A" % mode) + "/*.*"))
self.files_B = sorted(glob.glob(os.path.join(root, "%s/B" % mode) + "/*.*"))
def __getitem__(self, index):
image_A = Image.open(self.files_A[index % len(self.files_A)])
if self.unaligned:
image_B = Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)])
else:
image_B = Image.open(self.files_B[index % len(self.files_B)])
# Convert grayscale images to rgb
if image_A.mode != "RGB":
image_A = to_rgb(image_A)
if image_B.mode != "RGB":
image_B = to_rgb(image_B)
item_A = self.transform(image_A)
item_B = self.transform(image_B)
return {"A": item_A, "B": item_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))这里需要注意的是: return { "A": item_A, "B": item_B}
这句话意味着什么呢?意味着下面这个dataloader:
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, unaligned=True),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)你一会在执行:
for i, batch in enumerate(dataloader):这句话的时候,batch是个dict,我们要通过batch['A']和batch['B']访问2种风格的图片。
3.utils.py:
学习率衰减:
class LambdaLR:
def __init__(self, n_epochs, offset, decay_start_epoch):
assert (n_epochs - decay_start_epoch) > 0, "Decay must start before the training session ends!"
self.n_epochs = n_epochs
self.offset = offset
self.decay_start_epoch = decay_start_epoch
def step(self, epoch):
return 1.0 - max(0, epoch + self.offset - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)4.cyclegan.py:
导入必要的库:
import argparse
import os
import numpy as np
import math
import itertools
import datetime
import time
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
from utils import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="monet2photo", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving generator outputs")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between saving model checkpoints")
parser.add_argument("--n_residual_blocks", type=int, default=9, help="number of residual blocks in generator")
parser.add_argument("--lambda_cyc", type=float, default=10.0, help="cycle loss weight")
parser.add_argument("--lambda_id", type=float, default=5.0, help="identity loss weight")
opt = parser.parse_args()
print(opt)
# Create sample and checkpoint directories
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)损失函数:
# Losses
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
cuda = torch.cuda.is_available()
input_shape = (opt.channels, opt.img_height, opt.img_width)注意这几个损失函数很细节,前面说了其实是MSELoss,而不是对数损失,
也是一样。
初始化G和D:
# Initialize generator and discriminator
G_AB = GeneratorResNet(input_shape, opt.n_residual_blocks)
G_BA = GeneratorResNet(input_shape, opt.n_residual_blocks)
D_A = Discriminator(input_shape)
D_B = Discriminator(input_shape)导入参数:
if cuda:
G_AB = G_AB.cuda()
G_BA = G_BA.cuda()
D_A = D_A.cuda()
D_B = D_B.cuda()
criterion_GAN.cuda()
criterion_cycle.cuda()
criterion_identity.cuda()
if opt.epoch != 0:
# Load pretrained models
G_AB.load_state_dict(torch.load("saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, opt.epoch)))
G_BA.load_state_dict(torch.load("saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, opt.epoch)))
D_A.load_state_dict(torch.load("saved_models/%s/D_A_%d.pth" % (opt.dataset_name, opt.epoch)))
D_B.load_state_dict(torch.load("saved_models/%s/D_B_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
G_AB.apply(weights_init_normal)
G_BA.apply(weights_init_normal)
D_A.apply(weights_init_normal)
D_B.apply(weights_init_normal)优化器:
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))学习率衰减:
# Learning rate update schedulers
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(
optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(
optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(
optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
Tensor = torch.cuda.FloatTensor if cuda else torch.Tensortorch.optim.lr_scheduler.LambdaLR里面有一个参数lr_lambda是要输入学习率,这个学习率是动态变化的,由LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step来获得。
数据预处理:
# Image transformations
transforms_ = [
transforms.Resize(int(opt.img_height * 1.12), Image.BICUBIC),
transforms.RandomCrop((opt.img_height, opt.img_width)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]依然把数据归一化到均值为0,方差为1的形式。
dataloader:
# Training data loader
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, unaligned=True),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
# Test data loader
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, unaligned=True, mode="test"),
batch_size=5,
shuffle=True,
num_workers=1,
)保存一个生成的样本:
def sample_images(batches_done):
"""Saves a generated sample from the test set"""
imgs = next(iter(val_dataloader))
G_AB.eval()
G_BA.eval()
real_A = Variable(imgs["A"].type(Tensor))
fake_B = G_AB(real_A)
real_B = Variable(imgs["B"].type(Tensor))
fake_A = G_BA(real_B)
# Arange images along x-axis
real_A = make_grid(real_A, nrow=5, normalize=True)
real_B = make_grid(real_B, nrow=5, normalize=True)
fake_A = make_grid(fake_A, nrow=5, normalize=True)
fake_B = make_grid(fake_B, nrow=5, normalize=True)
# Arange images along y-axis
image_grid = torch.cat((real_A, fake_B, real_B, fake_A), 1)
save_image(image_grid, "images/%s/%s.png" % (opt.dataset_name, batches_done), normalize=False)训练和保存模型:
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Set model input
real_A = Variable(batch["A"].type(Tensor))
real_B = Variable(batch["B"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *D_A.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *D_A.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
G_AB.train()
G_BA.train()
optimizer_G.zero_grad()
# Identity loss
loss_id_A = criterion_identity(G_BA(real_A), real_A)
loss_id_B = criterion_identity(G_AB(real_B), real_B)
loss_identity = (loss_id_A + loss_id_B) / 2
# GAN loss
fake_B = G_AB(real_A)
loss_GAN_AB = criterion_GAN(D_B(fake_B), valid)
fake_A = G_BA(real_B)
loss_GAN_BA = criterion_GAN(D_A(fake_A), valid)
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Cycle loss
recov_A = G_BA(fake_B)
loss_cycle_A = criterion_cycle(recov_A, real_A)
recov_B = G_AB(fake_A)
loss_cycle_B = criterion_cycle(recov_B, real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# Total loss
loss_G = loss_GAN + opt.lambda_cyc * loss_cycle + opt.lambda_id * loss_identity
loss_G.backward()
optimizer_G.step()
# -----------------------
# Train Discriminator A
# -----------------------
optimizer_D_A.zero_grad()
# Real loss
loss_real = criterion_GAN(D_A(real_A), valid)
# Fake loss (on batch of previously generated samples)
fake_A_ = fake_A_buffer.push_and_pop(fake_A)
loss_fake = criterion_GAN(D_A(fake_A_.detach()), fake)
# Total loss
loss_D_A = (loss_real + loss_fake) / 2
loss_D_A.backward()
optimizer_D_A.step()
# -----------------------
# Train Discriminator B
# -----------------------
optimizer_D_B.zero_grad()
# Real loss
loss_real = criterion_GAN(D_B(real_B), valid)
# Fake loss (on batch of previously generated samples)
fake_B_ = fake_B_buffer.push_and_pop(fake_B)
loss_fake = criterion_GAN(D_B(fake_B_.detach()), fake)
# Total loss
loss_D_B = (loss_real + loss_fake) / 2
loss_D_B.backward()
optimizer_D_B.step()
loss_D = (loss_D_A + loss_D_B) / 2
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, adv: %f, cycle: %f, identity: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_GAN.item(),
loss_cycle.item(),
loss_identity.item(),
time_left,
)
)
# If at sample interval save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
# Update learning rates
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(G_AB.state_dict(), "saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, epoch))
torch.save(G_BA.state_dict(), "saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_A.state_dict(), "saved_models/%s/D_A_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_B.state_dict(), "saved_models/%s/D_B_%d.pth" % (opt.dataset_name, epoch))G_AB.train()
G_BA.train()设置为训练状态。
接下来该更新G的参数了,套路一共有4步:
1. optimizer_G.zero_grad() 。
2. 求出loss。这里G的loss分为3部分,就是上面介绍的。
3. loss_G.backward()。
4. optimizer_G.step()。
需要注意的是作者是把和
一起更新的。
更新D的参数也是一样的方法:
个人总结:
CycleGAN也不是没有问题。CycleGAN: a Master of Steganography (隐写术) [Casey Chu, et al., NIPS workshop, 2017 ]这篇论文就指出,CycleGAN存在一种情况,是它能学会把输入的某些部分藏起来,然后在输出的时候再还原回来。比如下面这张图:

可以看到,在经过第一个generator的时候,屋顶的黑色斑点不见了,但是在经过第二个generator之后,屋顶的黑色斑点又被还原回来了。这其实意味着,第一个generator并没有遗失掉屋顶有黑色斑点这一讯息,它只是用一种人眼看不出的方式将这一讯息隐藏在输出的图片中(例如黑点数值改得非常小),而第二个generator在训练过程中也学习到了提取这种隐藏讯息的方式。那generator隐藏讯息的目的是什么呢?其实很简单,隐藏掉一些破坏风格相似性的“坏点”会更容易获得discriminator的高分,而从discriminator那拿高分是generator实际上的唯一目的。