大数据平台到底该如何设计?
本文首发微信公众号:码上观世界
要回答如何设计大数据平台,首先要回答为什么要设计大数据平台。设计大数据平台无非是满足企业的数据查询和分析需求,最终为企业的运营服务。最终交到运营手里的大数据产品可以是报表、看板以及其他高级BI工具。
实际上,从大数据运营平台沿着数据链路的产生方向往上游推,还存在着大数据采集与存储平台、大数据开发与计算平台、大数据治理平台等。他们分别服务者不同的用户,比如大数据采集与存储平台的用户一般是ETL工程师,大数据开发与计算平台一般是数据仓库工程师或者算法工程师,大数据治理平台一般是IT、安全部门以及产品运营等。
这几个平台其实构成了大数据部门的核心职能:数据采集、存储、计算、治理、查询、分析。
自从有了Hadoop,大数据部门实现这些职能,变得易如反掌:Hadoop基于冗余廉价的机器,用HDFS实现大规模分布式数据存储、用MapReduce计算框架实现分布式计算、用YARN实现资源调度功能,用Hive实现规范化数据仓库,进而提供OLAP查询分析。大数据部门需要做的就是招聘一些大数据工程师,买一些服务器,从官网下载Hadoop部署,然后就可以郑重宣布,XXX公司大数据部门成立啦!
尽管Hadoop出现已经16年了,但是放眼国内大部分中小公司的大数据部门仍然在使用这一套系统和流程:
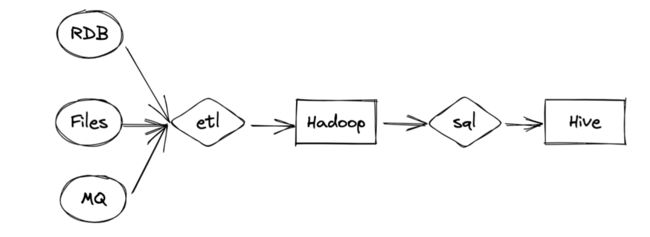
你看,借助Hadoop,ETL工程师很轻易地实现了外部各种结构化,半结构化以及非结构化数据的清洗和同步,然后数据仓库开发工程师将清洗后的结构化数据进一步加工处理,生成符合数据仓库规范要求的数据,最后数据分析师在数据仓库的基础上开发各种运营需要的业务数据指标。
只要公司愿意,数据团队各小组相安无事,这套系统虽然原始,但也基本能满足日常需要。但是,人不会只停留在满足基本需求的阶段,随着需求的增加,系统也变得复杂起来,数据平台的边界也拓展到了Hadoop之外,原因可以列举几点:
Hadoop提供了数据存储的能力,但是如何将不同数据源的数据同步到Hadoop平台,则是用户自己的事情。于是,大数据部门需要解决如何抽取、转换并加载到Hadoop,业界也有很多开源工具,比如Crunch,Cascading类库以及集成工具Kettle、Sqoop、Datax,Flume、Kafka、SeaTunnel以及可视化同步产品Airbyte等。
2. Hadoop提供了数据计算的能力,但是MapReduce计算框架因为涉及到频繁地数据落盘和读盘,性能很低,于是催生了Tez和Spark计算框架。
3. Hadoop和Hive提供了批处理的能力,但是批处理的拓扑结构如何设计,以及批处理按照何种方式执行,都是用户自己的事情。因为在数据仓库实施阶段,为了保证数据的新鲜度和准确性,需要周期性的进行数据同步以及数据重计算,因此需要一套任务编排与调度系统,按照用户指定的拓扑结构定时执行。开源界出现的很多分布式任务调度系统,比如面向Hadoop平台的Oozie、Azkaban、Airflow、Prefect以及国产 DolphinScheduler等都是为满足这一需求而出现的。
4. Hive提供了数据查询能力,并且提供了JDBC接口以及Shell接口,但是总不能让数据团队每个人每次查询数据,都打开Hive shell控制台吧,于是需要借助一些外部工具,比如Hue,Zeppelin等。特别地,Hive作为一种典型的老牛负重型工具,在大规模复杂场景下查询分析数据,老牛没有累死,也许用的人先急死了,于是出现了替代Hive,用于交互式查询分析的工具,如 Impala、Kyligence、Presto和Trino等。
5. Hadoop和Hive是为离线应用服务的,但是经过数据仓库阶段产生的资产信息(如业务指标)等数据最终要为在线服务,为了提升响应性能,这些资产应用数据往往需要回流到在线服务如RDB、KV数据库,如Mysql、Redis、Hbase等以及搜索引擎。
6. 数据从源头到业务指标数据,中间经过了一些列的转化操作,如何可视化的监控每个环节的数据质量、数据合规、数据冷热度等问题,这需要数据治理工具以及权限控制工具,这类开源工具有Atlas、DataHub、Metacat、Kerberos、Sentry、Ranger、Prometheus、Grafana、Ambari等。
这么多工具,如何选型,如何集成,如何运维,不是找几个员工就能搞定的事情,有钱有技术的互联网公司确实可以这么干(也只能这么干),他们可以在开源的基础上集成,优化甚至自研替换一些工具,但是对没有技术实力的公司,只能望技术兴叹了。这不,Cloudera公司带来了冬天的一把火,提供了开源版本的CDH,它将常用的大数据组件集成在一起,并夹带了一些私货,提供自动化部署能力,这些组件包括(以CDH 6.3.4为例):
参考
https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_63_packaging.html
Component |
Component Version |
Apache Avro |
1.8.2 |
Apache Flume |
1.9.0 |
Apache Hadoop |
3.0.0 |
Apache HBase |
2.1.4 |
HBase Indexer |
1.5 |
Apache Hive |
2.1.1 |
Hue |
4.4.0 |
Apache Impala |
3.2.0 |
Apache Kafka |
2.2.1 |
Kite SDK |
1.0.0 |
Apache Kudu |
1.10.0 |
Apache Solr |
7.4.0 |
Apache Oozie |
5.1.0 |
Apache Parquet |
1.9.0 |
Parquet-format |
2.4.0 |
Apache Pig |
0.17.0 |
Apache Sentry |
2.1.0 |
Apache Spark |
2.4.0 |
Apache Sqoop |
1.4.7 |
Apache ZooKeeper |
3.4.5 |
CDH有没有价值?确实有,至少给想尝鲜大数据但是苦于没有技术实力的公司带来了极大的便利,甚至也能为有一定技术实力的公司节省大把的时间和金钱(但是如果想进一步扩大集群节点数量以及享用高级特性,那就得付费了)。
CDH的价值仅此而已,它只是提升了运维部署的效率,但是对于现有的技术生态并没有什么实质的改进,特别地,随着下面几个重大趋势的改变,使得CDH的价值荡然无存:
1 流计算
实时数据往往以流数据的形式出现,特别是随着物联网IoT的出现,流式数据的应用场景更进一步推动流计算,传统Hadoop优势在批处理,此时在流式处理方面简直是被降维打击。因为几乎不需要落盘,以Storm、Spark Streamng、Kafka Streaming、Flink为代表的流计算框架都不需要Hadoop计算框架,甚至都直接跳过HDFS存储,直接将实时处理后的数据写入到在线服务或者直接推送到看板、终端等前端应用中。
2 数据湖
数据湖的出现可以归结为以下几点:
存储成本:HDFS存储大规模的数据仍然成本过高,而基于对象存储成本更低;
非结构化:无结构数据的快速写入需求使得数据入湖不再像数据仓库那样必须是结构化数据,数据湖可以做到事后读取的结构化;
实时性:实时数据期望变更的数据像数据库那样支持更新,并保证事务
3 云原生
云原生的弹性扩容能力以及无服务化模式进一步解放人力,让企业更关注业务价值创造。虽然短期看,云原生改造对企业的成本要远大于私有化部署,但是从长期看,云服务化仍然是企业的最佳选项。
对CDH,如果说流式数据相比批处理带来的只是计算模式的改变,对象存储替代文件存储只是存储介质的改变,那么云原生相比私有化部署,就是釜底抽薪,基于云原生实现的EMR干脆把CDH一锅端了。甚至是Hadoop技术生态本身,现在还剩下什么?
MapReduce计算框架被Spark、Flink替代;
HDFS被对象存储替代,开源的对象存储系统有MinIo、商业版的有S3、OSS、OBS等;
YARN资源调度框架已经让位于Mesos、Kubernetes等;
Hive分析查询被Impala、Kylingence、Presto、Trino取代,当然也有企业尝试应用Flink做OLAP。另外 DorisDB、StarRocks、Clickhouse、Snowflake等更不用说。
唯一令Hadoop欣慰的是,虽然丢了江山,但赢得了“美人”啊,因为其先发优势以及稳定可靠的品质,牢牢占据了大量用户的心。此时,企业如果再让用户从Hadoop体系迁移到其他技术体系,这时候双方都要好好掂量掂量了。
在面向流数据应用中,流处理的架构模式大致是这样的:
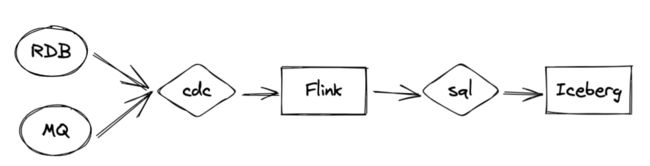
RDB或者MQ中的数据,通过CDC(如Debezium)实时摄入进入Flink,在Flink SQL的处理之后入湖。该图跟批处理看起来相差无几,但是处理方式却有着实质的差异:
1 时效性更高,批处理以天,小时为单位,流处理则以分钟,秒为单位;
2 Flink 处理过程中的数据可以不用落盘,还可以实时关联外部在线服务系统中的维度数据,如Mysql、Redis、Hbase等,创建聚合数据,相比批处理方式,数据获取更灵活;
3 Flink处理结果数据直接事务性入湖
于是新技术的出现带来了新的问题:如何跟旧的、但是广泛引用的技术相处?在新生政权没有取得完全性的统治权之前,看在这么多无辜的用户的面子上,起码还得要尊重下现任当权者嘛,总不能自己一骑飙尘,做空中楼阁吧。
至于如何跟现任当权者相处,还是从颠覆CDH的三个趋势来讲吧。
1 流计算与批处理如何统一
在企业的实际应用中,批处理仍然占大头,流计算只是小部分场景,于是就在架构设计上就存在两条数据链路:

一条实时链路,一条批处理链路,前者处理实时增量数据,后者处理全量数据,由于目前实时处理不是很成熟,比如Flink存在丢数据,重复数据等问题,数据湖Iceberg存在小文件、大数据量删除更新合并慢等,批处理还担负着异常数据修正的职责。两条数据链路不仅维护成本高,计算逻辑难以保证统一,因此它只是临时状态,最终要合并为一条链路,这方面Flink的流批一体特性被寄予厚望。
实际上,除了统一流式计算和批处理之外,在计算引擎上,同样存在着HIve、Spark、Flink等多种引擎,如何统一多种引擎,给最终用户统一的入口是to B企业不得不考虑的问题。
2 数据仓库与数据湖如何统一
数据仓库的优势在于查询结构化数据,数据湖的优势在于海量无结构化数据的写入能力,数据湖在查询上需要先转化为结构化数据,无法像数据仓库那样进行底层数据的针对性存储和查询优化。另外,数据湖常基于云上对象存储,相较数据仓库的本地化存储,天然多了网络延迟开销。为统一数据仓库与数据湖,开源界出现了几三大数据湖技术:Iceberg、Hudi、Delta lake,在此基础上,业界提出了湖仓一体的概念,但是如何实施湖仓一体,业界还不统一,但基本都是在湖中建仓,就像下面这张图描绘的模式:

值得一提的是,这么看仓和湖确实是一体,但是仓寄生在湖上,仓通过ETL工具处理湖上的数据,结果仍存储在湖上。如果这就代表湖仓一体,那么传统的基于Hadoop的数仓实施是不是也是湖仓一体?也算啊,区别就是基于湖技术的湖仓一体做到了更新和事务能力,而传统的Hadoop湖仓一体做不到,阿里云的Maxcompute和AWS的Redshift就属于传统的湖仓一体。不管是传统的湖仓一体还是基于数据湖技术的湖仓一体,它们都是临时态,都是为了兼容传统的数仓和现代的数据湖而存在的,只有当数据湖技术足够成熟,能够完全替代数仓功能,才会转向最终态:数据湖。
实现这一目标的关键在于ETL:如果把ETL拿掉,弱化仓的作用,甚至没有仓,数据的加工过程全部在查询时进行,或者通过物化视图的方式屏蔽掉ETL,显然NoETL才是最终态的标志。就像Snowflake那样,通过各种数据重分布、索引,cache等方法加速数据查询效率,目的也是为了减少ETL,只不过它先从仓入手。相反,datalakes 是从湖入手,虽然两者可能最终都会涉及到对方的领域,但这只是业务的布局,非数据湖终态,二者最终殊途同归。
在湖仓管理中,另一个无法回避的能力:元数据管理。上文提到Hadoop生态基本被剥离、替代干净了,还有一个幸存者:HiveMetastore。而且它也是大数据元数据管理的事实标准,怎么体现呢?Spark、Flink足够牛吧,但是 还得向 HiveMetastore 靠拢,离开了HiveMetastore,自己就失去了群众基础--数据。HiveMetastore之所以是目前这种格局,除了先发优势之外,最重要的是它是最专业的、最完善的,别无竞争者,连AWS Glue也以它为蓝本定制开发。HiveMetastore当前存在一些较大的问题,比如不同版本存在兼容性问题,低版本不支持数据目录管理,不支持多租户。大部分用户还停在早期低版本阶段,存在升级困难,对 to B企业,提供通用的统一元数据服务,就必须着手解决这些问题。
3 离线资源调度和在线资源调度如何统一
传统的Hadoop通过YARN来统一管控计算资源,但是在云原生领域,管理资源变成了Kubernetes,而后者适合于在线服务。在企业中,这两种集群往往是独立部署,计算成本和运维成本都很高,能不能混合部署来提升资源利用率呢?目前字节和阿里都有相关的实践,并且在生产中取得较好的效果,阿里还开源了这套混部系统:Koordinator。
好,到目前为止,基本明确了大数据平台的核心能力,我们总结为下图:
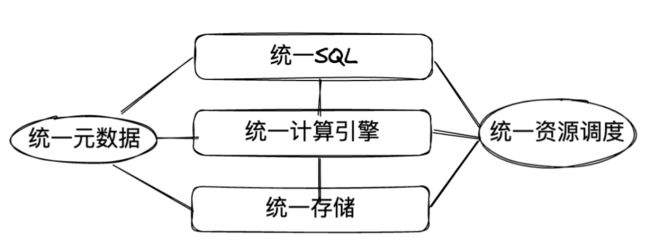
它分别对应了大数据平台的核心能力:查询分析、计算、存储,元数据管理和资源管理是基础能力。如果把这个图作为设计模板,你也许可以把DorisDB、StarRocks、Clickhouse以及Hologres等单一系统当做这个模板的实例化。在没有历史包袱的情况下,比如从0-1搭建企业服务的时候,上述系统随便一个都能满足你的需求,但是当面临系统升级换代,特别是服务to B企业的时候,这个模板的实例化难度就是几个数量级的提升,毕竟连AWS这样的云厂商都回避了某些问题:在统一SQL上干脆直接封装了Presto,简单省事;在统一计算引擎上,直接通过EMR打包部署,将CDH干的事在云上再干一遍。用户如果要用EMR,对不起,那就上云吧。
但我们的目标是星辰大海,统一宇宙:

实现该目标的总体原则就是组件统一,分层迭代,具体实施可以参考以下几个判断标准:
1. 我设计的查询SQL语言是否涉及到迁移,是否增加了用户的学习成本;
2. SQL执行的计算引擎能否指定或者自适应,是否同时支持批处理、流计算以及交互式查询;
3. 数据存储是否支持分布式文件存储,对象存储,数据格式是否是开放式数据格式;
4. 资源调度是否支持弹性伸缩,是否支持批处理、流计算以及交互式查询硬件资源共享;
5. 不同的计算引擎是否共用元数据,元数据服务能否支持开放式使用。