python保存模型_python保存模型
 广告关闭
广告关闭
腾讯云11.11云上盛惠 ,精选热门产品助力上云,云服务器首年88元起,买的越多返的越多,最高返5000元!
来源于知乎模型上线一般通过java处理 此时最好用pmml,github上有sklearntopmml的模块可以免费使用,强烈推荐。 这和r语言有点类似完整的一个例子# conding = utf-8from sklearn import svmfromsklearn.externals import joblibimport osx = ,]y= clf = svm.svc(probability=true)clf.fit(x,y)# 测试样本test = ...
在r中,在运行“随机森林”模型之后,我可以使用save.image(***.rdata)来存储模型。 之后,我可以直接加载模型来做预测。 python中模型文件中:rf= randomforestregressor(n_estimators=250, max_features=9,compute_importances=true)fit= rf.fit(predx, predy) 我试着回来rf或fit, ,但是不起作用...
how to save an arima time series forecasting model in python 原文作者:jason brownlee 原文地址:https:machinelearningmastery.comsave-arima-time-series-forecasting-model-python译者微博:@从流域到海域 译者博客:blog.csdn.netsolo95 如何在python中保存arima时间序列预测模型自回归积分滑动平均模型...
差分自回归移动平均模型(arima)是时间序列分析和预测领域流行的一个线性模型。 statsmodels库实现了在python中使用arima。 (对当前序列得到的)arima模型可以被保存到文件中,用于对未来的新数据进行预测。 但statsmodels库的当前版本中存在一个缺陷(2017.2),这个bug会导致模型无法被加载。 在本教程中,你将了解...
自回归移动平均模型(arima)是一种常用于时间序列分析和预测的线性模型。 statsmodels库提供了python中使用arima的实现。 arima模型可以保存到文件中,以便以后对新数据进行预测。 在当前版本的statsmodels库中有一个bug,它阻止了保存的模型被加载。 在本教程中,你将了解如何诊断并解决此问题。 让我们开始吧。?...
pickle.dump(model, f) # 读取模型 with open(model.pickle, rb) as f:model = pickle.load(f) model.predict(x_test) # sklearn自带方法joblib fromsklearn.externals import joblib # 保存模型 joblib.dump(model, model.pickle)#载入模型 model = joblib.load(model.pickle)...
self.size = len(self.trainset) self.m = max() # p91中的m #计算p82页最下面的期望 self.ep_ = * len(self.feats) # 保存期望值 for i,f in enumerate...maxent.predict(sunny sad) print (prob) github上发现的一份最大熵模型实现代码。 具体链接找不到了...
how to save an arima time series forecasting model in python原文作者:jason brownlee 原文地址:https:machinelearningmastery.comsave-arima-time-series-forecasting-model-python译者微博:@从流域到海域 译者博客:blog.csdn.netsolo95如何在python中保存arima时间序列预测模型自回归积分滑动平均模型(auto...
然而,这个模型的主要参考,blei etal 2003可以在线免费获得,我认为将语料库(文档集)中的文档分配给基于单词矢量的潜在(隐藏)主题的主要思想是相当容易理解的而这个例子(来自lda)将有助于巩固我们对lda模型的理解。 那么,让我们开始..... 安装lda在之前的帖子中,我介绍了使用pip和 virtualenwrapper安装...
概率lda主题模型的评估方法使用未标记的数据时,模型评估很难。 这里描述的指标都试图用理论方法评估模型的质量,以便找到“最佳”模型。评估后部分布的...无法使用griffiths和steyvers方法,因为它需要一个特殊的python包(gmpy2) ,这在我运行评估的cpu集群机器上是不可用的。 但是,“对数似然”将报告非常...
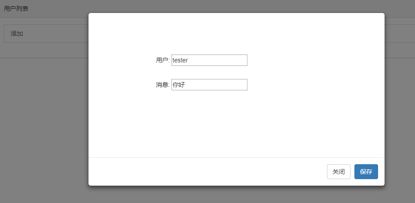
▲图1 再点击保存,那么数据库就存入了以上输入的数据,查看界面的用户列表会显示tester,如下图2所示:? ▲图22、开发过程接下来根据以上实例,一步一步教你编写代码。 首先搭建好python环境--python3,django2,mysql,pycharm,等。 一 python数据模型 models.py,用于创建数据库表存储数据clastest(models.model)...
状态空间模型——state space models2.10 多元统计模型——因子主成分分析3相关模型demo3.1 线性回归模型3.2 广义线性模型——glm3.3 稳健回归4 其他4.1模型结果如何csv导出? 4.2 画模型图以及保存4.3 快速获取模型输出参数:p检验、f检验、p统计量----1 安装pip install statsmodels不过有可能会报错:importerror...
the_model.load_state_dict(torch.load(path))使用这种方法,我们需要自己导入模型的结构信息。 方法二:使用这种方法,将会保存模型的参数和结构信息。 保存torch.save(the_model, path)恢复the_model =torch.load(path)一个相对完整的例子savingtorch.save({epoch: epoch + 1,arch: argsarch,state_dict: model...
学习了那么多机器学习模型,一切都是为了实践,动手自己写写这些模型的实现对自己很有帮助的,坚持,共勉。 本文主要致力于总结贝叶斯实战中程序代码的实现(python)及朴素贝叶斯模型原理的总结。 python的numpy包简化了很多计算,另外本人推荐使用pandas做数据统计。 一 引言 让你猜测一个身高2.16的人的职业,你...
其他应用在这里演示的字符级模型的歌词预测功能可以被扩展到其他更有用的应用上。 例如,可以利用相同的原理对iphone键盘上要输入的下一个单词进行预测。 图8. 键盘输入预测下一个单词 想象假如你建立一个高准确度的python语言模型,不但能够自动填充关键词或者变量名,还可以填充大段的代码,这将帮助码农们节省多少...
这里主要有三个核心函数:torch.save :把序列化的对象保存到硬盘。 它利用了 python 的 pickle 来实现序列化。 模型、张量以及字典都可以用该函数进行保存; torch.load:采用 pickle 将反序列化的对象从存储中加载进来。 torch.nn.module.load_state_dict:采用一个反序列化的 state_dict加载一个模型的参数字典...
信用评分模型可用“四张卡”来表示,分别是a卡(application score card,申请评分卡)、b卡(behavior score card,行为评分卡、c卡(collection score card,催收评分卡)和f卡(anti-fraud card,反欺诈评分卡),分别应用于贷前、贷中、贷后。 本篇我们主要讨论基于python的信用评分模型开发,并在各部分附上了...

译者 | vk 来源 | analyticsvidhya概述了解如何使用计算机视觉和深度学习技术处理视频数据我们将在python中构建自己的视频分类模型这是一个非常实用的视频分类教程,所以准备好jupyter notebook介绍我们可以使用计算机视觉和深度学习做很多事情,例如检测图像中的对象,对这些对象进行分类,从电影海报中生成标签...

将info、warning、error等不同的记录分开存储rabbitmq消息模型 这里使用 python 的pika 这个库来实现rabbitmq中常见的6种消息模型。 没有的可以先安装:pip install pika1. 单生产单消费模型:即完成基本的一对一消息转发。? # 生产者代码import pika credentials = pika.plaincredentials(chuan, 123) #mq用户名和...
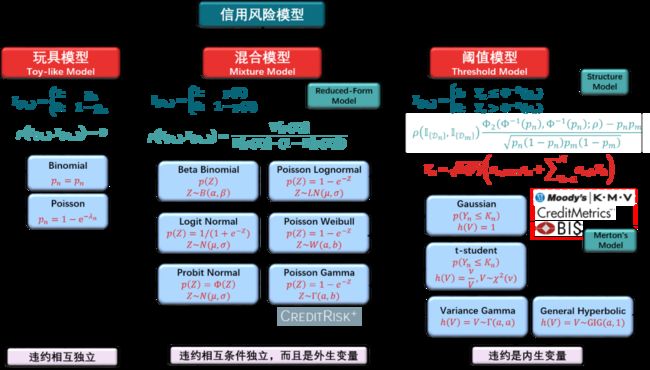
0引言本文是「信用风险建模 in python」系列的第三篇,其实在之前的 cufflinks 那篇已经埋下了信用风险的伏笔,信用组合可视化信用风险 101独立模型 - 伯努利模型独立模型 - 泊松模型在伯努利模型中,我们用一下违约指示函数来对第 n个借贷人违约建模这种建模方式是直接赋值给违约事件和存活事件一个概率...