Jmeter压力测试和性能调优
1.压力测试的概念
压力测试是模拟实际应用的软硬件环境及用户使用过程的系统负荷,长时间或超大负荷地运行测试软件,来测试被测系统的性能、可靠性、稳定性等
2.压力测试的目的
1)给出系统当前的性能状况
2)定位系统性能瓶颈或潜在性能瓶颈
3.压力测试工具(Jmeter)
1)安装:Apache JMeter - Download Apache JMeter
2)使用:下载对应的压缩包,解压运行 jmeter.bat 即可(注意:JDK版本最好是8,太高可能启动不了)
3)JMeter 压测示例:
a)大家如英文界面,可以改为中文
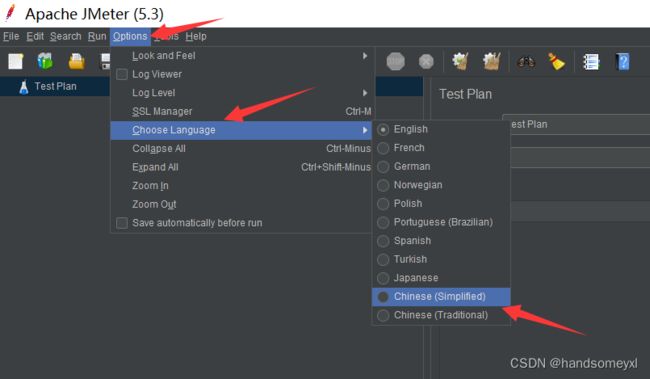
b) 右击TestPlan添加线程组

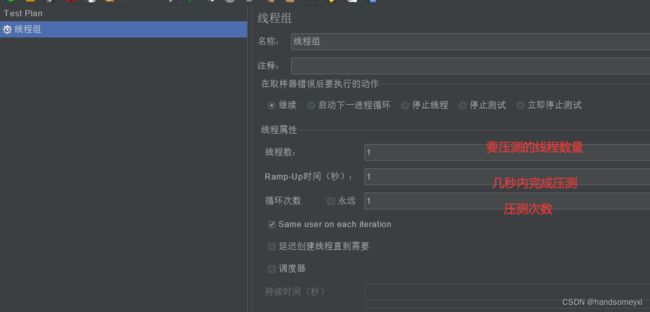
线程组参数详解:
1)线程数:虚拟用户数。一个虚拟用户占用一个进程或线程。设置多少虚拟用户数在这里
也就是设置多少个线程数。
2) Ramp-Up Period(in seconds)准备时长:设置的虚拟用户数需要多长时间全部启动。如果
线程数为 10,准备时长为 2,那么需要 2 秒钟启动 10 个线程,也就是每秒钟启动 5 个
线程。
3)循环次数:每个线程发送请求的次数。如果线程数为 10,循环次数为 100,那么每个线
程发送 100 次请求。总请求数为 10*100=1000 。如果勾选了“永远”,那么所有线程会
一直发送请求,一到选择停止运行脚本。
4) Delay Thread creation until needed:直到需要时延迟线程的创建。
5)调度器:设置线程组启动的开始时间和结束时间(配置调度器时,需要勾选循环次数为
永远)
6) 持续时间(秒):测试持续时间,会覆盖结束时间
7) 启动延迟(秒):测试延迟启动时间,会覆盖启动时间
8)启动时间:测试启动时间,启动延迟会覆盖它。当启动时间已过,手动只需测试时当前
时间也会覆盖它。
9) 结束时间:测试结束时间,持续时间会覆盖它。
加粗的几个参数比较重要
c)添加http请求
请求内容
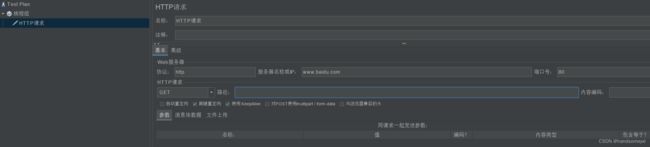
d)添加监听器,一般使用红框中的三个就够了

查看结果数:

汇总报告:

聚合报告和汇总报告差不多,我就不解释了
4.性能调优
给你一段代码,结合整个项目如何优化这个代码?
//获取当前一级分类下的子分类
@Override
public Map> getCatalogJson() {
List list = this.list(null);
//查出一级菜单
List categorys = this.list(new QueryWrapper().eq("cat_level", 1));
Map> collect1 = categorys.stream().collect(Collectors.toMap((k) -> {
return k.getCatId().toString();
}, (v) -> {
List categoryEntity2 = getParent_cid(list, v.getCatId());
List catelog2Vos = categoryEntity2.stream().map((obj) -> {
Catelog2Vo catelog2Vo = new Catelog2Vo();
catelog2Vo.setCatalog1Id(v.getCatId().toString());
catelog2Vo.setId(obj.getCatId().toString());
catelog2Vo.setName(obj.getName());
List catelog3Vo = getParent_cid(list, obj.getParentCid());
List collect = catelog3Vo.stream().map((vo3) -> {
Catelog2Vo.Catalog3Vo catelo3Vo = new Catelog2Vo.Catalog3Vo();
catelo3Vo.setName(vo3.getName());
catelo3Vo.setId(vo3.getCatId().toString());
catelo3Vo.setCatalog2Id(obj.getCatId().toString());
return catelo3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
return catelog2Vo;
}).collect(Collectors.toList());
return catelog2Vos;
}));
return collect1;
} 优化手段:
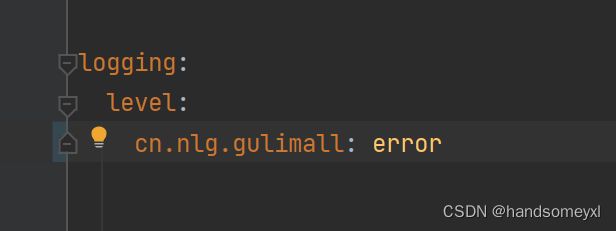
1)调整日志输出级别为error
2)开启thymeleaf缓存(前后端分离项目忽略)

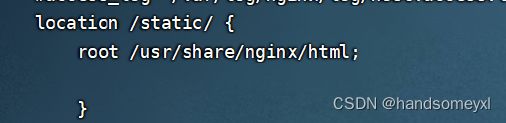
3)动静分离,将静态资源交个nginx来处理

4)优化代码本身,减少与DB交互的次数,优化后代码:
//获取当前一级分类下的子分类
public Map> getCatalogJsonForDB() {
List list = this.list(null);
//查出一级菜单
List categorys = this.list(new QueryWrapper().eq("cat_level", 1));
Map> collect1 = categorys.stream().collect(Collectors.toMap((k) -> {
return k.getCatId().toString();
}, (v) -> {
List categoryEntity2 = this.list(new QueryWrapper().eq("parent_cid", v.getCatId()));
List catelog2Vos = categoryEntity2.stream().map((obj) -> {
Catelog2Vo catelog2Vo = new Catelog2Vo();
catelog2Vo.setCatalog1Id(v.getCatId().toString());
catelog2Vo.setId(obj.getCatId().toString());
catelog2Vo.setName(obj.getName());
List catelog3Vo = this.list(new QueryWrapper().eq("parent_cid", obj.getCatId()));
List collect = catelog3Vo.stream().map((vo3) -> {
Catelog2Vo.Catalog3Vo catelo3Vo = new Catelog2Vo.Catalog3Vo();
catelo3Vo.setName(vo3.getName());
catelo3Vo.setId(vo3.getCatId().toString());
catelo3Vo.setCatalog2Id(obj.getCatId().toString());
return catelo3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
return catelog2Vo;
}).collect(Collectors.toList());
return catelog2Vos;
}));
return collect1;
}
private List getParent_cid(List categoryEntities,Long parentCid) {
List collect = categoryEntities.stream().filter((obj) -> {
return obj.getParentCid() == parentCid;
}).collect(Collectors.toList());
return collect;
} 5) 给where后面的字段创建索引(parent_cid)
create index idx_pid on pms_category(parent_cid)
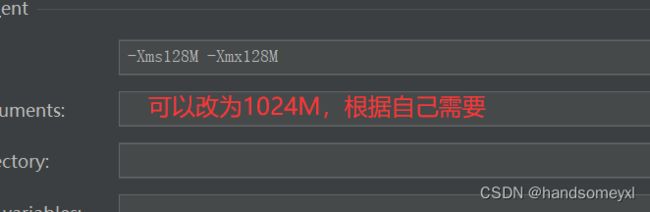
6)设置JVM的参数(大一些)
7)加入本地缓存(Map),代码:
//获取数据带有map的缓存
public Map> getCatalogJsonForMapCache() {
Map map = new HashMap<>();
Map> cache = (Map>) map.get("catalogJson");
if (cache==null){
List list = this.list(null);
//查出一级菜单
List categorys = this.list(new QueryWrapper().eq("cat_level", 1));
Map> collect1 = categorys.stream().collect(Collectors.toMap((k) -> {
return k.getCatId().toString();
}, (v) -> {
List categoryEntity2 = getParent_cid(list,v.getCatId());
List catelog2Vos = categoryEntity2.stream().map((obj) -> {
Catelog2Vo catelog2Vo = new Catelog2Vo();
catelog2Vo.setCatalog1Id(v.getCatId().toString());
catelog2Vo.setId(obj.getCatId().toString());
catelog2Vo.setName(obj.getName());
List catelog3Vo = getParent_cid(list,obj.getParentCid());
List collect = catelog3Vo.stream().map((vo3) -> {
Catelog2Vo.Catalog3Vo catelo3Vo = new Catelog2Vo.Catalog3Vo();
catelo3Vo.setName(vo3.getName());
catelo3Vo.setId(vo3.getCatId().toString());
catelo3Vo.setCatalog2Id(obj.getCatId().toString());
return catelo3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
return catelog2Vo;
}).collect(Collectors.toList());
return catelog2Vos;
}));
map.put("catalogJson",collect1);
} //查出所有菜单
return cache;
} 8)加入redis缓存
//使用了redis缓存获取数据
@Override
public Map> getCatalogJson() {
String jsonData = stringRedisTemplate.opsForValue().get("jsonData");
if (jsonData==null){
Map> catalogJsonForDB = getCatalogJsonForDB();
stringRedisTemplate.opsForValue().set("jsonData",JSON.toJSONString(catalogJsonForDB));
return catalogJsonForDB;
}
return JSON.parseObject(jsonData, new TypeReference>>(){});
} 用redis做也会出现很多问题:比如缓存击穿,缓存雪崩,缓存穿透,关于这些大家可以参考我的这篇博客:
redis缓存雪崩,缓存穿透,缓存击穿_handsomeyxl的博客-CSDN博客
以及使用分布式锁(Redisson)所来解决问题,参考我的博客:
Redis分布式锁(不使用会出现哪些问题)_handsomeyxl的博客-CSDN博客
当然还有更多优化:比如线程池,异步编排,大家有兴趣可以了解一下
这篇文章希望对你有帮助,有问题私信一起交流!