0 | pytorch环境安装及一个Resnet图像分类模型测试
先说说我的环境
硬件方面:一台联想笔记本,搭载了NVIDIA P2000 显卡,查了一下属于GTX1060乞丐版
系统方面:Windows 10,预装好了Anaconda,Python版本3.7.4
要开始学习PyTorch,第一步肯定先把PyTorch装上。
上PyTorch官网看一下。
一上来就是明晃晃的Install大字,直接点进去
官网给推荐了配置
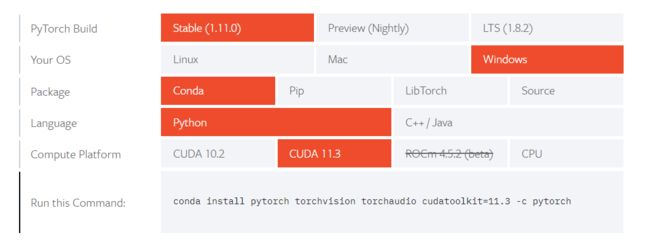
照着官网说的命令在cmd里面执行,当然前提是先激活你要用的conda环境,conda环境配置这里就不说了。
安装过程很慢,PyTorch包挺大的,有1G多,所以需要配置一个下载比较快的镜像源,或者像这种Windows系统的话,其实可以直接在Anaconda的界面上进行安装,这里就不细讲了。
安装好了环境,我们就开始跑测试的例子了。
启动我们的Jupyter
这里先看一下PyTorch的视觉库里都有什么模型

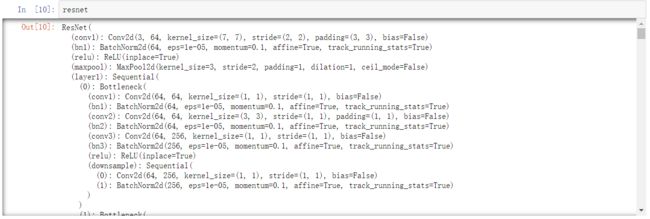
这里面已经预设的模型还是挺全面的,我们这次测试需要跑的是ResNet模型,众所周知的图像分类模型,这里实例化的是resnet101,使用的是有101层的resnet模型,后面加了pretrained=True我理解是确认下载预训练模型?
resnet = models.resnet101(pretrained=True)
执行完之后就开始下载预训练模型了

image.png
下载完了,一共170m+,这个模型有4450w个参数。我们看一下,每一行就是一个模块的细节
接下来我们定义预处理方法,并加载图片。预处理环节我大概能看出做了图像大小的重置,中心裁剪,并进行了值的标准化?
from torchvision import transforms
preprocess = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
from PIL import Image
img = Image.open("../data/p1ch2/bobby.jpg")
用的是这张狗狗图
接着就是导入激动人心的torch包,然后把图像向量化,并塞到batch里面,这里用了一个方法unsqueeze,查了一下,大概可以理解成为升维的方法,也就是给图像做了一个编号?
import torch
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
之后我们就要把图像特征放进模型里去运行了,在这里称为inference(推理),不过这里面还有一步要做,就是把网络设置为eval模式。具体为什么这么做书上也没说清楚,只是说会导致模型后面的优化部分失效,具体原因我们后面再探究,这里只是为了跑通这个测试,就先不追究了。
eval模式就需要下面这个代码。
resnet.eval()
然后定义输出,也就是模型开始运行了
out = resnet(batch_t)
模型运行完并不会有什么结果显示,需要我们手动的执行一下输出
但是这个输出我们还是不能很直观的看明白,这里是输出了一个长度为1000的向量,每一个值表示一个类别的置信度,1000个这么多我们很难肉眼找到最高的那个,这里需要把类别的信息加载进来方便我们阅读
with open('../data/p1ch2/imagenet_classes.txt') as f:
labels = [line.strip() for line in f.readlines()]
_, index = torch.max(out, 1)
给输出的结果加上了类别信息之后,我们就可以输出类别和对应的置信度了
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
labels[index[0]], percentage[index[0]].item()
这一句输出结果就比较靠谱了,可以看到最高的是金毛犬

到这里还不够,我们只看到了第一高的结果,还想看看第二高的结果是不是跟第一高差不多,所以这里再对结果排一下序,然后输出top5的结果
_, indices = torch.sort(out, descending=True)
[(labels[idx], percentage[idx].item()) for idx in indices[0][:5]]
输出的结果如下,可以看出来第二个是拉布拉多,这个也是狗,第三个和第四个经过查谷歌翻译了解了也是一种狗,中文名叫啥我就不知道了,第五个是网球就有点意思了,估计是训练集里面狗狗和网球同时出现的情况比较多吧,不过可以看出来从第二个开始置信度有了大幅度的下降,所以金毛胜出。

好了,这一课就到这里,下次再见。