simple-faster-rcnn-pytorch-master代码解读——模型部分
simple-faster-rcnn-pytorch-master代码解读——模型部分
比起数据处理部分,我个人觉得模型部分好难理解,认真阅读了代码理解1和代码理解2,并且参考了模型准备部分,结合自己的理解,下面按照我的理解程度从深到浅进行讲述。
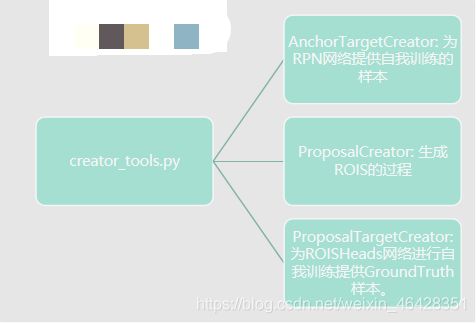
一、module下有_init_.py、faster_rcnn.py、faster_rcnn_vgg16.py、region_proposal_network.py和utils文件夹,utils下有bbox_tools.py、creator_tool.py和_init_.py文件,下图为组会汇报时的ppt截图,是对bbox_tools.py、creator_tool.py函数的总结。
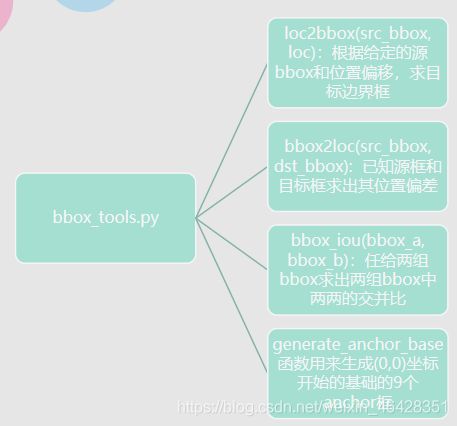
 1.bbox_tools.py
1.bbox_tools.py
import numpy as np
import numpy as xp
import six
from six import __init__
# 输入的是源bbox和参数组,输出的是目标bbox,正好是下面的逆过程。bbox2loc称编码过程,那loc2bbox即为解码过程。
def loc2bbox(src_bbox, loc) #根据给定的源bbox和位置偏移,求目标边界框
if src_bbox.shape[0] == 0:
return xp.zeros((0, 4), dtype=loc.dtype) #src_bbox(R,4) R代表边界框数,4表示4个坐标`p_{ymin}, p_{xmin}, p_{ymax}, p_{xmax}`
src_bbox = src_bbox.astype(src_bbox.dtype, copy=False)
#之所以这么做是因为进行回归是要将数据格式从左上右下的坐标表示形式转化到中心点和长宽的表示形式,而bbox框的源位置类型应该是x0,y0,x1,y1这样用第三个减去第一个得到的自然是高度h,同理求出宽度w,
#然后函数进行了中心点的求解,就是用左上角的x0+1/2h,y0+1/2w得到中心点的坐标
src_height = src_bbox[:, 2] - src_bbox[:, 0] # 求出源框架的高度p_{ymax}-p_{ymin}
src_width = src_bbox[:, 3] - src_bbox[:, 1] # 求出源框架的宽度p_{xmax}-p_{xmin}
src_ctr_y = src_bbox[:, 0] + 0.5 * src_height #计算中心坐标
src_ctr_x = src_bbox[:, 1] + 0.5 * src_width
# P表示proposal边框,src_height为Ph,src_width为Pw,src_ctr_y为Py,src_ctr_x为Px
dy = loc[:, 0::4] #位置偏差dx,dy,dh,dw
dx = loc[:, 1::4]
dh = loc[:, 2::4]
dw = loc[:, 3::4]
#RCNN中提出的边框回归:寻找原始proposal与近似目标框G之间的映射关系,
ctr_y = dy * src_height[:, xp.newaxis] + src_ctr_y[:, xp.newaxis] #ctr_y为Gy
ctr_x = dx * src_width[:, xp.newaxis] + src_ctr_x[:, xp.newaxis] # ctr_x为Gx
h = xp.exp(dh) * src_height[:, xp.newaxis] #h为Gh
w = xp.exp(dw) * src_width[:, xp.newaxis] #w为Gw
dst_bbox = xp.zeros(loc.shape, dtype=loc.dtype) #loc.shape:(R,4),同src_bbox
dst_bbox[:, 0::4] = ctr_y - 0.5 * h ##由中心点转换为左上角和右下角坐标
dst_bbox[:, 1::4] = ctr_x - 0.5 * w
dst_bbox[:, 2::4] = ctr_y + 0.5 * h
dst_bbox[:, 3::4] = ctr_x + 0.5 * w
return dst_bbox
#输入的是源bbox和目标bbox,然后输出的是参数组,即源bbox相对于bbox的offset和scales。注意对坐标的转换(顶点坐标转为中心、宽高)。
def bbox2loc(src_bbox, dst_bbox): #已知源框和目标框求出其位置偏差
height = src_bbox[:, 2] - src_bbox[:, 0] #计算出源框中心点坐标和长宽
width = src_bbox[:, 3] - src_bbox[:, 1]
ctr_y = src_bbox[:, 0] + 0.5 * height
ctr_x = src_bbox[:, 1] + 0.5 * width
base_height = dst_bbox[:, 2] - dst_bbox[:, 0] #计算出目标框中心点坐标和长宽
base_width = dst_bbox[:, 3] - dst_bbox[:, 1]
base_ctr_y = dst_bbox[:, 0] + 0.5 * base_height
base_ctr_x = dst_bbox[:, 1] + 0.5 * base_width
eps = xp.finfo(height.dtype).eps #求出最小的正数
height = xp.maximum(height, eps) #将height,width与最小正数比较保证全部是非负
width = xp.maximum(width, eps)
# 根据上面的公式计算dx,dy,dh,dw
dy = (base_ctr_y - ctr_y) / height # dy=(Gy-Py)/Ph
dx = (base_ctr_x - ctr_x) / width # dx=(Gx-Px)/Pw
dh = xp.log(base_height / height) # dh=log(Gh/Ph)
dw = xp.log(base_width / width) # dw=log(Gw/Pw)
loc = xp.vstack((dy, dx, dh, dw)).transpose() #np.vstack按照行的顺序把数组堆叠起来
return loc
#实现的是任给两组bbox求出两组bbox中两两的交并比。
def bbox_iou(bbox_a, bbox_b):
if bbox_a.shape[1] != 4 or bbox_b.shape[1] != 4: #确保bbox第二维为bbox的四个坐标(ymin,xmin,ymax,xmax)
raise IndexError
# top left
tl = xp.maximum(bbox_a[:, None, :2], bbox_b[:, :2]) #tl为交叉部分边界框左上角坐标最大值,为了利用numpy的广播性质,bbox_a[:, None, :2]的shape是(N,1,2),bbox_b[:, :2]shape是(K,2),由numpy的广播性质,两个数组shape都变成(N,K,2),也就是对a里每个bbox都分别和b里的每个bbox求左上角点坐标最大值
# bottom right
br = xp.minimum(bbox_a[:, None, 2:], bbox_b[:, 2:]) ##br为交叉部分框右下角坐标最小值
area_i = xp.prod(br - tl, axis=2) * (tl < br).all(axis=2) #所有坐标轴上tl
area_a = xp.prod(bbox_a[:, 2:] - bbox_a[:, :2], axis=1) #利用numpy.prod返回给定轴上数组元素的乘积,计算bboxa的面积
area_b = xp.prod(bbox_b[:, 2:] - bbox_b[:, :2], axis=1) #计算bboxb的面积
return area_i / (area_a[:, None] + area_b - area_i) #计算IOU
def __test():
pass
if __name__ == '__main__':
__test()
#实现生成(0,0)坐标开始的基础的9个anchor框
def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2], ##base_size就是基础的anchor的宽和高其实是16的大小、再根据不同的放缩比和宽高比进行进一步的调整。(选择长度为16的原因是图片大小为600*800左右,基准长度16对应的原图区域是256*256,考虑放缩后的大小有128*128,512*512比较合适)
anchor_scales=[8, 16, 32]): # anchor_scales也就是在base_size的基础上再增加的量,本代码中对应着三种面积的大小(16*8)2 ,(16*16)2 (16*32)2 也就是128,256,512的平方大小,三种面积乘以三种放缩比就刚刚好是9种
# 根据基准点生成9个基本的anchor的功能,ratios=[0.5,1,2],anchor_scales=[8,16,32]是长宽比和缩放比例,anchor_scales也就是在base_size的基础上再增加的量,本代码中对应着三种面积的大小(16*8)^2 ,(16*16)^2 (16*32)^2 也就是128,256,512的平方大小
py = base_size / 2.
px = base_size / 2.
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4),
dtype=np.float32) #(9,4),注意:这里只是以特征图的左上角点为基准产生的9个anchor
for i in six.moves.range(len(ratios)): #six.moves 是用来处理那些在python2和3里面函数的位置有变化的,直接用six.moves就可以屏蔽掉这些变化
for j in six.moves.range(len(anchor_scales)): #生成9种不同比例的h和w
h = base_size * anchor_scales[j] * np.sqrt(ratios[i])
w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i])
index = i * len(anchor_scales) + j
anchor_base[index, 0] = py - h / 2.
anchor_base[index, 1] = px - w / 2.
anchor_base[index, 2] = py + h / 2.
anchor_base[index, 3] = px + w / 2.
return anchor_base
2.creator_tool.py
import numpy as np
import torch
from torchvision.ops import nms
from model.utils.bbox_tools import bbox2loc, bbox_iou, loc2bbox
# 提供GroundTruth样本供ROISHeads网络(接收ROIS对它进行n_class类别的预测以及最终目标检测位置的)进行自我训练。从ProposalCreator产生的2000个ROIS筛选产生128个用于自身的训练。返回(sample_RoI, gt_RoI_loc, gt_RoI_label)
class ProposalTargetCreator(object):
def __init__(self,
n_sample=128,
pos_ratio=0.25, pos_iou_thresh=0.5,
neg_iou_thresh_hi=0.5, neg_iou_thresh_lo=0.0
):
self.n_sample = n_sample
self.pos_ratio = pos_ratio
self.pos_iou_thresh = pos_iou_thresh
self.neg_iou_thresh_hi = neg_iou_thresh_hi
self.neg_iou_thresh_lo = neg_iou_thresh_lo # NOTE:default 0.1 in py-faster-rcnn
def __call__(self, roi, bbox, label,
loc_normalize_mean=(0., 0., 0., 0.),
loc_normalize_std=(0.1, 0.1, 0.2, 0.2)):
n_bbox, _ = bbox.shape # 边界框数量
roi = np.concatenate((roi, bbox), axis=0) # 将bbox和rois连接起来
pos_roi_per_image = np.round(self.n_sample * self.pos_ratio) # n_sample = 128,pos_ratio=0.5,round 对传入的数据进行四舍五入
iou = bbox_iou(roi, bbox) # 计算iou
gt_assignment = iou.argmax(axis=1) # 按行找到最大值,返回最大值对应的序号(每个roi与**bbox的最大)以及其真正的IOU
max_iou = iou.max(axis=1) #每个roi与对应bbox最大的iou
# Offset range of classes from [0, n_fg_class - 1] to [1, n_fg_class].
# The label with value 0 is the background.值为0的标签是背景
gt_roi_label = label[gt_assignment] + 1 # 利用最大值的序号将那些挑出的最大值的label+1从0,n_fg_class-1 (0-19)变到1,n_fg_class(1-20)
# Select foreground RoIs as those with >= pos_iou_thresh IoU. 根据IOUS的最大值将正样本找出来,如果找出的样本数目过多就随机丢掉一些
pos_index = np.where(max_iou >= self.pos_iou_thresh)[0]
pos_roi_per_this_image = int(min(pos_roi_per_image, pos_index.size)) # 需要保留的roi个数
if pos_index.size > 0:
pos_index = np.random.choice(
pos_index, size=pos_roi_per_this_image, replace=False) # 找出的样本数目过多就随机丢掉一些
# Select background RoIs as those within
# [neg_iou_thresh_lo, neg_iou_thresh_hi).找出负样本,如果找出的样本数目过多就随机丢掉一些
neg_index = np.where((max_iou < self.neg_iou_thresh_hi) &
(max_iou >= self.neg_iou_thresh_lo))[0] # #neg_iou_thresh_hi=0.5,neg_iou_thresh_lo=0.0
neg_roi_per_this_image = self.n_sample - pos_roi_per_this_image # #需要保留的roi个数
neg_roi_per_this_image = int(min(neg_roi_per_this_image,
neg_index.size))
if neg_index.size > 0:
neg_index = np.random.choice(
neg_index, size=neg_roi_per_this_image, replace=False)
# The indices that we're selecting (both positive and negative).
keep_index = np.append(pos_index, neg_index) # 将正负样本序号连接起来,得到它们对应的真实的label
gt_roi_label = gt_roi_label[keep_index]
gt_roi_label[pos_roi_per_this_image:] = 0 # negative labels --> 0,统一将负样本的label全部置为0
sample_roi = roi[keep_index]
# 那么此时输出的128*4的sample_roi就可以去扔到 RoIHead网络里去进行分类与回归了。同样, RoIHead网络利用这sample_roi+featue为输入,输出是分类(21类)和回归(进一步微调bbox)的预测值,那么分类回归的groud truth就是ProposalTargetCreator输出的gt_roi_label和gt_roi_loc。
# Compute offsets and scales to match sampled RoIs to the GTs.计算偏移量和比例,使采样ROI与GTs匹配
gt_roi_loc = bbox2loc(sample_roi, bbox[gt_assignment[keep_index]]) # 根据sample_rois和bbox的偏移量计算这128个样本的groundtruth
gt_roi_loc = ((gt_roi_loc - np.array(loc_normalize_mean, np.float32)
) / np.array(loc_normalize_std, np.float32)) # ProposalTargetCreator首次用到了真实的21个类的label,且该类最后对loc进行了归一化处理,所以预测时要进行均值方差处理
return sample_roi, gt_roi_loc, gt_roi_label
# AnchorTargetCreator的作用就是为RPN网络提供自我训练的样本(从20000多个Anchor选出256个用于二分类和所有的位置回归!为预测值提供对应的真实值,即返回gt_rpn_loc和gt_rpn_label)
class AnchorTargetCreator(object):
def __init__(self,
n_sample=256,
pos_iou_thresh=0.7, neg_iou_thresh=0.3,
pos_ratio=0.5): # 正样本阈值pos_iou_thresh=0.7 , 负样本阈值neg_iou_thresh=0.3
self.n_sample = n_sample
self.pos_iou_thresh = pos_iou_thresh
self.neg_iou_thresh = neg_iou_thresh
self.pos_ratio = pos_ratio
def __call__(self, bbox, anchor, img_size):
img_H, img_W = img_size # 图像的高度和宽度
n_anchor = len(anchor) # 用len(anchor)读取anchor的个数
inside_index = _get_inside_index(anchor, img_H, img_W) # 调用_get_inside_index将那些超出图片范围的anchor全部去掉,
anchor = anchor[inside_index] # 只保留位于图片内部的anchor
argmax_ious, label = self._create_label(
inside_index, anchor, bbox) # 筛选出符合条件的正例128个负例128并给它们附上相应的label
# compute bounding box regression targets计算边界框回归目标
loc = bbox2loc(anchor, bbox[argmax_ious]) # 求偏差
# map up to original set of anchors 映射到原始锚集
label = _unmap(label, n_anchor, inside_index, fill=-1)
loc = _unmap(loc, n_anchor, inside_index, fill=0)
return loc, label
def _create_label(self, inside_index, anchor, bbox):
# label: 1 is positive, 0 is negative, -1 is dont care
label = np.empty((len(inside_index),), dtype=np.int32) # #inside_index是所有在图片范围内的anchor序号
label.fill(-1) # 将所有标号全部置为-1
argmax_ious, max_ious, gt_argmax_ious = \
self._calc_ious(anchor, bbox, inside_index) # 调用_calc_ious()函数得到每个anchor与哪个bbox的iou最大以及这个iou值、每个bbox与哪个anchor的iou最大(需要体会从行和列取最大值的区别)
# assign negative labels first so that positive labels can clobber them。比较每个anchor与对应的框求得的iou值,再分别与负样本阈值和正样本阈值比较, 若小于负样本阈值, 则label设为0;若大于正样本阈值, 则label设为1
label[max_ious < self.neg_iou_thresh] = 0 # 负样本(所得anchor与对应框iou的重叠度小于0.3)
# positive label: for each gt, anchor with highest iou
label[gt_argmax_ious] = 1 # 正样本(gt_argmax_ious就是和gt_bbox重叠读最高的anchor,直接定义为正样本)
# positive label: above threshold IOU
label[max_ious >= self.pos_iou_thresh] = 1 # 正样本(所得anchor与对应框iou的重叠度大于0.7)
# subsample positive labels if we have too many如果我们有太多的子样本正标签
n_pos = int(self.pos_ratio * self.n_sample) # 按照比例计算出正样本数量
pos_index = np.where(label == 1)[0] # 选出的label=1的个数,即正样本的索引
if len(pos_index) > n_pos: # 正样本如果按照这个规则选取多了,超过了预设定的正样本数,就调用np.random.choice总数不变随机丢弃掉一些正样本,被抛弃的标记为-1
disable_index = np.random.choice(
pos_index, size=(len(pos_index) - n_pos), replace=False)
label[disable_index] = -1
# subsample negative labels if we have too many如果我们有太多的负标签
n_neg = self.n_sample - np.sum(label == 1) # 设定的负样本的数量
neg_index = np.where(label == 0)[0] # 负样本label=0的索引
if len(neg_index) > n_neg: # 如果负样本选择多了随机丢弃掉一些
disable_index = np.random.choice(
neg_index, size=(len(neg_index) - n_neg), replace=False)
label[disable_index] = -1
return argmax_ious, label
def _calc_ious(self, anchor, bbox, inside_index):
# ious between the anchors and the gt boxes
ious = bbox_iou(anchor, bbox) # 调用bbox_iou函数计算anchor与bbox的IOU, ious:(N,K),N为anchor中第N个,K为bbox中第K个,N大概有15000个
argmax_ious = ious.argmax(axis=1) # 1代表行,0代表列
max_ious = ious[np.arange(len(inside_index)), argmax_ious] # 求出每个anchor与哪个bbox的iou最大以及这个最大值,max_ious:[1,N]
gt_argmax_ious = ious.argmax(axis=0)
gt_max_ious = ious[gt_argmax_ious, np.arange(ious.shape[1])] # 求出每个bbox与哪个anchor的iou最大以及这个最大值,gt_max_ious:[1,K]
gt_argmax_ious = np.where(ious == gt_max_ious)[0] # 返回最大iou的索引
return argmax_ious, max_ious, gt_argmax_ious
def _unmap(data, count, index, fill=0):
# Unmap a subset of item (data) back to the original set of items (of
# size count)
if len(data.shape) == 1:
ret = np.empty((count,), dtype=data.dtype)
ret.fill(fill)
ret[index] = data
else:
ret = np.empty((count,) + data.shape[1:], dtype=data.dtype)
ret.fill(fill)
ret[index, :] = data
return ret
def _get_inside_index(anchor, H, W):
# Calc indicies of anchors which are located completely inside of the image
# whose size is speficied.
index_inside = np.where(
(anchor[:, 0] >= 0) &
(anchor[:, 1] >= 0) &
(anchor[:, 2] <= H) &
(anchor[:, 3] <= W)
)[0]
return index_inside
#proposalCreator做的就是生成ROIS的过程
class ProposalCreator: # RPN从上万个anchor中选择一定数目(2000或者300)调整大小和位置生成ROIS的过程,这些RoIs用以Fast R-CNN训练或者测试
# unNOTE: I'll make it undifferential
# unTODO: make sure it's ok
# It's ok
"""Proposal regions are generated by calling this object.
Args:
nms_thresh (float):调用非最大抑制NMS时使用的阈值。
n_train_pre_nms (int):在训练模式下通过NMS之前要保留的顶部得分边界框的数量
n_train_post_nms (int):在训练模式下通过NMS后要保留的顶部得分边界框数。
n_test_pre_nms (int):在测试模式下传递给NMS之前要保留的顶部得分边界框的数量。
n_test_post_nms (int):在测试模式下通过NMS后要保留的顶部得分边界框的数量。
force_cpu_nms (bool): `True`,CPU mode. `False`,根据输入类型选择NMS模式。
min_size (int): 一个用于根据边界框的大小来确定丢弃边界框阈值的参数。
"""
def __init__(self,
parent_model,
nms_thresh=0.7,
n_train_pre_nms=12000,
n_train_post_nms=2000,
n_test_pre_nms=6000,
n_test_post_nms=300,
min_size=16
):
self.parent_model = parent_model
self.nms_thresh = nms_thresh
self.n_train_pre_nms = n_train_pre_nms
self.n_train_post_nms = n_train_post_nms
self.n_test_pre_nms = n_test_pre_nms
self.n_test_post_nms = n_test_post_nms
self.min_size = min_size
def __call__(self, loc, score,
anchor, img_size, scale=1.):
# NOTE: when test, remember
# faster_rcnn.eval()
# to set self.traing = False
if self.parent_model.training:
n_pre_nms = self.n_train_pre_nms
n_post_nms = self.n_train_post_nms
else:
n_pre_nms = self.n_test_pre_nms
n_post_nms = self.n_test_post_nms
# Convert anchors into proposal via bbox transformations.
# roi = loc2bbox(anchor, loc)
roi = loc2bbox(anchor, loc) # 利用预测的修正值,对12000个anchor进行修正
# Clip predicted boxes to image.
roi[:, slice(0, 4, 2)] = np.clip(
roi[:, slice(0, 4, 2)], 0, img_size[0]) # 将产生的rois的大小全部裁剪到图片范围以内
roi[:, slice(1, 4, 2)] = np.clip(
roi[:, slice(1, 4, 2)], 0, img_size[1])
# Remove predicted boxes with either height or width < threshold.移除高度或宽度小于阈值的预测框
min_size = self.min_size * scale
hs = roi[:, 2] - roi[:, 0] # 计算图片的高度和宽度
ws = roi[:, 3] - roi[:, 1]
keep = np.where((hs >= min_size) & (ws >= min_size))[0] # 保留大于规定的min_size的Rois,高度和宽度任何一个小于开始我们规定的min_size都直接mask掉
roi = roi[keep, :]
score = score[keep] # 对剩下的ROIs进行打分
# Sort all (proposal, score) pairs by score from highest to lowest.将所有(建议、得分)对按得分从最高到最低排序
# Take top pre_nms_topN (e.g. 6000).
order = score.ravel().argsort()[::-1] # 得到的分数进行合并然后进行排序,保留属于前景的概率排序后的前12000/6000个(分别对应训练和测试时候的配置)
if n_pre_nms > 0: # 调用非极大值抑制函数,将重复的抑制掉
order = order[:n_pre_nms]
roi = roi[order, :]
score = score[order]
# Apply nms (e.g. threshold = 0.7).
# Take after_nms_topN (e.g. 300).
# unNOTE: somthing is wrong here!
# TODO: remove cuda.to_gpu
keep = nms(
torch.from_numpy(roi).cuda(),
torch.from_numpy(score).cuda(),
self.nms_thresh)
if n_post_nms > 0:
keep = keep[:n_post_nms]
roi = roi[keep.cpu().numpy()]
return roi
二、对faster_rcnn.py、faster_rcnn_vgg16.py、region_proposal_network.py的理解。
1.region_proposal_network.py
该.py文件中有一个很重要的函数就是_enumerate_shifted_anchor(anchor_base, feat_stride, height, width),主要功能生成所有对应feature map的anchor。

import numpy as np
from torch.nn import functional as F
import torch as t
from torch import nn
from model.utils.bbox_tools import generate_anchor_base
from model.utils.creator_tool import ProposalCreator
class RegionProposalNetwork(nn.Module):
def __init__(
self, in_channels=512, mid_channels=512, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32], feat_stride=16, # feat_stride=16,因为经过四次pooling所以feature map的尺寸是原图的1/16
proposal_creator_params=dict(),
):
super(RegionProposalNetwork, self).__init__()
self.anchor_base = generate_anchor_base(
anchor_scales=anchor_scales, ratios=ratios)
self.feat_stride = feat_stride
self.proposal_layer = ProposalCreator(self, **proposal_creator_params)
n_anchor = self.anchor_base.shape[0]
self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
self.score = nn.Conv2d(mid_channels, n_anchor * 2, 1, 1, 0)
self.loc = nn.Conv2d(mid_channels, n_anchor * 4, 1, 1, 0)
normal_init(self.conv1, 0, 0.01) # 归一化
normal_init(self.score, 0, 0.01)
normal_init(self.loc, 0, 0.01)
def forward(self, x, img_size, scale=1.): # 前向RPN
n, _, hh, ww = x.shape # feature map的宽hh高ww,n为batch_size,此代码n=1
anchor = _enumerate_shifted_anchor(
np.array(self.anchor_base),
self.feat_stride, hh, ww) # 在9个base_anchor基础上生成hh*ww*9个anchor
n_anchor = anchor.shape[0] // (hh * ww) # 9= hh*ww*9/(hh*ww)
h = F.relu(self.conv1(x)) # 512个3x3卷积(512, H/16,W/16)
rpn_locs = self.loc(h) # 9*4个1x1卷积,回归坐标偏移量.(9*4,hh,ww)
# UNNOTE: check whether need contiguous检查是否需要连接
# A: Yes
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4) # 转换为(n,hh,ww,9*4)后变为(n,hh*ww*9,4)
rpn_scores = self.score(h) # 9*2个1x1卷积,回归类别.(9*2,hh,ww)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous() # 转换为(n,hh,ww,9*2)
rpn_softmax_scores = F.softmax(rpn_scores.view(n, hh, ww, n_anchor, 2), dim=4) # 计算softmax
rpn_fg_scores = rpn_softmax_scores[:, :, :, :, 1].contiguous() # 前景的分类概率
rpn_fg_scores = rpn_fg_scores.view(n, -1) # 所有anchor的前景分类概率
rpn_scores = rpn_scores.view(n, -1, 2) # 得到每一张feature map上所有anchor的网络输出值
rois = list()
roi_indices = list()
for i in range(n): # n=1,代表batch_size数
roi = self.proposal_layer(
rpn_locs[i].cpu().data.numpy(),
rpn_fg_scores[i].cpu().data.numpy(),
anchor, img_size,
scale=scale) # rpn_locs的维度(hh*ww*9,4),rpn_fg_scores的维度为(hh*ww*9),anchor的的维度为(hh*ww*9,4), img_size的维度为(3,H,W),H和W是数据预处理后的。计算(H/16)x(W/16)x9(大概20000)个anchor属于前景的概率,取前12000个并经过NMS得到2000个近似目标框G^的坐标。roi的维度为(2000,4)
batch_index = i * np.ones((len(roi),), dtype=np.int32)
rois.append(roi)
roi_indices.append(batch_index)
rois = np.concatenate(rois, axis=0) # 按行拼接(即没有batch_size的区分,每一个[]里都是一个anchor的四个坐标)
roi_indices = np.concatenate(roi_indices, axis=0) # roi_indices用在多张图像中,通过存储索引以找到对应图像的roi
return rpn_locs, rpn_scores, rois, roi_indices, anchor # rpn_locs的维度(hh*ww*9,4),rpn_scores维度为(hh*ww*9,2),rois的维度为(2000,4),roi_indices在本代码中用不到,anchor的维度为(hh*ww*9,4)
def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width):
# Enumerate all shifted anchors: 生成所有对应feature map的anchor
#
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
# return (K*A, 4)
# !TODO: add support for torch.CudaTensor
# xp = cuda.get_array_module(anchor_base)
# it seems that it can't be boosed using GPU
import numpy as xp
shift_y = xp.arange(0, height * feat_stride, feat_stride) # 就是以feat_stride为间距产生从(0,height*feat_stride)的一行,纵向偏移量(0,16,32,...)
shift_x = xp.arange(0, width * feat_stride, feat_stride) # 就是以feat_stride产生从(0,width*feat_stride)的一行,横向偏移量(0,16,32,...)
shift_x, shift_y = xp.meshgrid(shift_x, shift_y) # shift_x = [[0,16,32,..],[0,16,32,..],[0,16,32,..]...],shift_x = [[0,0,0,..],[16,16,16,..],[32,32,32,..]...],就是形成了一个纵横向偏移量的矩阵,也就是特征图的每一点都能够通过这个矩阵找到映射在原图中的具体位置
# 上行代码就是shift_x是以shift_x为行,以shift_y的行为列产生矩阵,同样shift_y是以shift_y的行为列,以shift_x的行的个数为列数产生矩阵
# 例如:x=[-3, -2, -1]; y=[-2, -1]; X,Y=np.meshgrid(x,y), 则得到X=([[-3, -2, -1],[-3, -2, -1]]);Y=([[-2, -1],[-2, -1],[-2, -1]]) 产生的X以x的行为行,以y的元素个数为列构成矩阵,同样的产生的Y以y的行作为列,以x的元素个数作为列数产生矩阵
shift = xp.stack((shift_y.ravel(), shift_x.ravel(),
shift_y.ravel(), shift_x.ravel()), axis=1) # 产生偏移坐标对,一个朝x方向,一个朝y方向偏移。此时X,Y的元素个数及矩阵大小都是相同的,(X.ravel()之后变成一行,此时shift_x,shift_y的元素个数是相同的,都等于特征图的长宽的乘积(像素点个数),不同的是此时的shift_x里面装得是横向看的x的一行一行的偏移坐标,而此时的y里面装得是对应的纵向的偏移坐标)
# 此时的shift变量就变成了以特征图像素总个数为行,4列的这样的数据格式(堆叠成四列是因为anchor的表示是左上右下坐标的形式,所有有四个坐标,而每两列恰好代表了横纵坐标的偏移量也就是一个点,所以最后用四列代表了两个点的偏移量。)
A = anchor_base.shape[0] # 读取anchor_base的个数,A=9
K = shift.shape[0] # 读取特征图中元素的总个数
anchor = anchor_base.reshape((1, A, 4)) + \
shift.reshape((1, K, 4)).transpose((1, 0, 2)) # 用基础的9个anchor的分别和偏移量相加,得出所有anchor的坐标(四列可以看作是左上角的坐标和右下角的坐标加偏移量的同步执行。一共K个特征点,每个点有9个基本的anchor,reshape成((K*A),4)的形式,得到了最后的所有的anchor坐标)
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
return anchor
def _enumerate_shifted_anchor_torch(anchor_base, feat_stride, height, width):
# Enumerate all shifted anchors:
#
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
# return (K*A, 4)
# !TODO: add support for torch.CudaTensor
# xp = cuda.get_array_module(anchor_base)
import torch as t
shift_y = t.arange(0, height * feat_stride, feat_stride)
shift_x = t.arange(0, width * feat_stride, feat_stride)
shift_x, shift_y = xp.meshgrid(shift_x, shift_y)
shift = xp.stack((shift_y.ravel(), shift_x.ravel(),
shift_y.ravel(), shift_x.ravel()), axis=1)
A = anchor_base.shape[0]
K = shift.shape[0]
anchor = anchor_base.reshape((1, A, 4)) + \
shift.reshape((1, K, 4)).transpose((1, 0, 2))
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
return anchor
def normal_init(m, mean, stddev, truncated=False): # 权重初始化
"""
weight initalizer: truncated normal and random normal.
"""
# x is a parameter
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
2.faster_rcnn_vgg16.py
from __future__ import absolute_import
import torch as t
from torch import nn
from torchvision.models import vgg16
from torchvision.ops import RoIPool
from model.region_proposal_network import RegionProposalNetwork
from model.faster_rcnn import FasterRCNN
from utils import array_tool as at
from utils.config import opt
def decom_vgg16():
# the 30th layer of features is relu of conv5_3
if opt.caffe_pretrain:
model = vgg16(pretrained=False) # 设置为True使用的是下载下来的caffe预训练模型,设置为False使用的是torchvision的预训练模型
if not opt.load_path:
model.load_state_dict(t.load(opt.caffe_pretrain_path)) # 加载参数
else:
model = vgg16(not opt.load_path)
features = list(model.features)[:30] # 加载预训练模型vgg16的conv5_3之前的部分
classifier = model.classifier
classifier = list(classifier)
del classifier[6]
if not opt.use_drop:
del classifier[5]
del classifier[2]
classifier = nn.Sequential(*classifier)
# freeze top4 conv前四层卷积层的学习率设为0
for layer in features[:10]: # 冻结vgg16前2个stage
for p in layer.parameters():
p.requires_grad = False
return nn.Sequential(*features), classifier # 拆分为特征提取网络和分类网络
# 分别对VGG16的特征提取部分、分类部分、RPN网络、VGG16RoIHead网络进行了实例化
class FasterRCNNVGG16(FasterRCNN):
feat_stride = 16 # downsample 16x for output of conv5 in vgg16
def __init__(self,
n_fg_class=20,
ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]
): # 总类别数为20类,anchor三种尺度为[8, 16, 32]三种比例为[0.5, 1, 2]
extractor, classifier = decom_vgg16()
rpn = RegionProposalNetwork(
512, 512,
ratios=ratios,
anchor_scales=anchor_scales,
feat_stride=self.feat_stride,
) # 返回rpn_locs, rpn_scores, rois, roi_indices, anchor
head = VGG16RoIHead(
n_class=n_fg_class + 1,
roi_size=7,
spatial_scale=(1. / self.feat_stride),
classifier=classifier
) # n_class为20类目标加上背景n_class= 21
super(FasterRCNNVGG16, self).__init__(
extractor,
rpn,
head,
) # 给faster_rcnn传入extractor, rpn, head参数
class VGG16RoIHead(nn.Module):
def __init__(self, n_class, roi_size, spatial_scale,
classifier):
# n_class includes the background
super(VGG16RoIHead, self).__init__()
self.classifier = classifier
self.cls_loc = nn.Linear(4096, n_class * 4)
self.score = nn.Linear(4096, n_class)
normal_init(self.cls_loc, 0, 0.001)
normal_init(self.score, 0, 0.01) # 全连接层权重初始化
self.n_class = n_class # 加背景21类
self.roi_size = roi_size # 7(使用RoIPooling将不同尺寸的区域全部pooling到同一个尺度(7×7))
self.spatial_scale = spatial_scale # 1/16
self.roi = RoIPool( (self.roi_size, self.roi_size),self.spatial_scale) # 将不同尺寸的区域全部pooling到7×7,得到pooling后的特征,大小为[300, 512, 7, 7]
def forward(self, x, rois, roi_indices):
"""
rois (Tensor): 包含建议框坐标的边界框数组。
roi_indices (Tensor): 包含边界框对应的图像索引的数组。
"""
# in case roi_indices is ndarray
roi_indices = at.totensor(roi_indices).float() # ndarray->tensor
rois = at.totensor(rois).float()
indices_and_rois = t.cat([roi_indices[:, None], rois], dim=1)
# NOTE: important: yx->xy
xy_indices_and_rois = indices_and_rois[:, [0, 2, 1, 4, 3]]
indices_and_rois = xy_indices_and_rois.contiguous() # 把tensor变成在内存中连续分布的形式
pool = self.roi(x, indices_and_rois) # 分析RoI()
pool = pool.view(pool.size(0), -1)
fc7 = self.classifier(pool) # decom_vgg16()得到的calssifier,得到4096
roi_cls_locs = self.cls_loc(fc7) # 用于回归(4096->84)
roi_scores = self.score(fc7) # 用于分类(4096->21)
return roi_cls_locs, roi_scores # roi回归输出的是128*84,真实位置参数是128*4,真实标签是128*1
def normal_init(m, mean, stddev, truncated=False):
"""
weight initalizer: truncated normal and random normal.
"""
# x is a parameter
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
3.faster_rcnn.py
from __future__ import absolute_import
from __future__ import division
import torch as t
import numpy as np
from utils import array_tool as at
from model.utils.bbox_tools import loc2bbox
from torchvision.ops import nms
# from model.utils.nms import non_maximum_suppression
from torch import nn
from data.dataset import preprocess
from torch.nn import functional as F
from utils.config import opt
def nograd(f):
def new_f(*args,**kwargs):
with t.no_grad():
return f(*args,**kwargs)
return new_f
class FasterRCNN(nn.Module):
def __init__(self, extractor, rpn, head,
loc_normalize_mean = (0., 0., 0., 0.),
loc_normalize_std = (0.1, 0.1, 0.2, 0.2)
):
super(FasterRCNN, self).__init__()
self.extractor = extractor
self.rpn = rpn
self.head = head
# mean and std
self.loc_normalize_mean = loc_normalize_mean
self.loc_normalize_std = loc_normalize_std
self.use_preset('evaluate')
@property
def n_class(self):
# Total number of classes including the background.
return self.head.n_class
def forward(self, x, scale=1.)
img_size = x.shape[2:]
h = self.extractor(x) # 输入一张图片得到其特征图feature map
rpn_locs, rpn_scores, rois, roi_indices, anchor = \
self.rpn(h, img_size, scale) # 给定feature map后产生一系列RoIs
roi_cls_locs, roi_scores = self.head(
h, rois, roi_indices) # 利用这些RoIs对应的feature map对这些RoIs中的类别进行分类
return roi_cls_locs, roi_scores, rois, roi_indices
def use_preset(self, preset):
if preset == 'visualize': # 预设是可视化的,则非最大值抑制的阈值=0.3,用于随机丢弃区域建议的阈值=0.7
self.nms_thresh = 0.3
self.score_thresh = 0.7
elif preset == 'evaluate': # 预设是评价性的,则非最大值抑制的阈值=0.3,用于随机丢弃区域建议的阈值=0.05
self.nms_thresh = 0.3
self.score_thresh = 0.05
else:
raise ValueError('preset must be visualize or evaluate')
def _suppress(self, raw_cls_bbox, raw_prob):
bbox = list()
label = list()
score = list()
# skip cls_id = 0 because it is the background class
for l in range(1, self.n_class):
cls_bbox_l = raw_cls_bbox.reshape((-1, self.n_class, 4))[:, l, :]
prob_l = raw_prob[:, l]
mask = prob_l > self.score_thresh
cls_bbox_l = cls_bbox_l[mask]
prob_l = prob_l[mask]
keep = nms(cls_bbox_l, prob_l,self.nms_thresh)
# import ipdb;ipdb.set_trace()
# keep = cp.asnumpy(keep)
bbox.append(cls_bbox_l[keep].cpu().numpy())
# The labels are in [0, self.n_class - 2].
label.append((l - 1) * np.ones((len(keep),)))
score.append(prob_l[keep].cpu().numpy())
bbox = np.concatenate(bbox, axis=0).astype(np.float32)
label = np.concatenate(label, axis=0).astype(np.int32)
score = np.concatenate(score, axis=0).astype(np.float32)
return bbox, label, score
@nograd
def predict(self, imgs,sizes=None,visualize=False): # 从图像中检测对象
"""
* **bboxes**: (R, 4),`R`是图像中边界框的数目 \
* **labels** : (R,).每个值表示边界框的类
* **scores** : (R,)每个值表示预测的可信度
"""
self.eval()
if visualize:
self.use_preset('visualize')
prepared_imgs = list()
sizes = list()
for img in imgs:
size = img.shape[1:]
img = preprocess(at.tonumpy(img))
prepared_imgs.append(img)
sizes.append(size)
else:
prepared_imgs = imgs
bboxes = list()
labels = list()
scores = list()
for img, size in zip(prepared_imgs, sizes):
img = at.totensor(img[None]).float()
scale = img.shape[3] / size[1]
roi_cls_loc, roi_scores, rois, _ = self(img, scale=scale)
# We are assuming that batch size is 1.
roi_score = roi_scores.data
roi_cls_loc = roi_cls_loc.data
roi = at.totensor(rois) / scale
# Convert predictions to bounding boxes in image coordinates.
# Bounding boxes are scaled to the scale of the input images.
mean = t.Tensor(self.loc_normalize_mean).cuda(). \
repeat(self.n_class)[None]
std = t.Tensor(self.loc_normalize_std).cuda(). \
repeat(self.n_class)[None]
roi_cls_loc = (roi_cls_loc * std + mean)
roi_cls_loc = roi_cls_loc.view(-1, self.n_class, 4)
roi = roi.view(-1, 1, 4).expand_as(roi_cls_loc)
cls_bbox = loc2bbox(at.tonumpy(roi).reshape((-1, 4)),
at.tonumpy(roi_cls_loc).reshape((-1, 4)))
cls_bbox = at.totensor(cls_bbox)
cls_bbox = cls_bbox.view(-1, self.n_class * 4)
# clip bounding box
cls_bbox[:, 0::2] = (cls_bbox[:, 0::2]).clamp(min=0, max=size[0])
cls_bbox[:, 1::2] = (cls_bbox[:, 1::2]).clamp(min=0, max=size[1])
prob = (F.softmax(at.totensor(roi_score), dim=1))
bbox, label, score = self._suppress(cls_bbox, prob)
bboxes.append(bbox)
labels.append(label)
scores.append(score)
self.use_preset('evaluate')
self.train()
return bboxes, labels, scores
def get_optimizer(self):
"""
return optimizer, It could be overwriten if you want to specify
special optimizer
"""
lr = opt.lr
params = []
for key, value in dict(self.named_parameters()).items():
if value.requires_grad:
if 'bias' in key:
params += [{'params': [value], 'lr': lr * 2, 'weight_decay': 0}]
else:
params += [{'params': [value], 'lr': lr, 'weight_decay': opt.weight_decay}]
if opt.use_adam:
self.optimizer = t.optim.Adam(params)
else:
self.optimizer = t.optim.SGD(params, momentum=0.9)
return self.optimizer
def scale_lr(self, decay=0.1):
for param_group in self.optimizer.param_groups:
param_group['lr'] *= decay
return self.optimizer
这部分没有理解很明白,所以有很多没标注,待弄明白再重新标注,也希望懂的前辈可以给我评论教教我,科研之路任重而道远,大家一起学习~~
另外,推荐一个很好的从编程角度理解Faster R-CNN的文章。