Faster RCNN原理及Pytorch代码解读——RPN(三):RPN训练标签的生成
上一篇大体介绍了RPN的网络结构,这一篇开始介绍RPN训练时标签是怎么生成的。
RPN真值
上一篇已经知道了RPN两个分支的输出了,分别是18×37×50和36×37×50(9个锚框的前景背景分类预测和中心点横纵坐标及宽高这4个量相对于真值的偏移量)。预测值有了,想要训练网络,还需要知道真值。
在介绍怎么生成真值时,还要多解释几句基础知识,如果已经知道这部分知识的跳过就好了。
RPN的真值究竟是什么?
对于物体检测任务来讲, 模型需要预测每一个物体的类别及其出现的位置, 即类别、 中心点坐标x与y、 宽w与高h这5个量。 由于有了Anchor这个先验框, RPN可以预测Anchor的类别作为预测边框的类别, 并且可以预测真实的边框相对于Anchor的偏移量, 而不是直接预测边框的中心点坐标x与y、 宽高w与h。
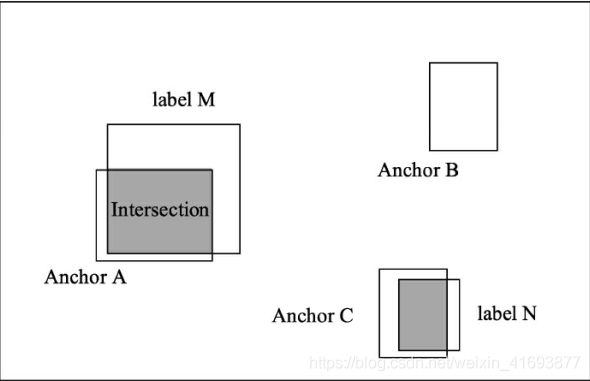
举个例子,如图所示,输入图像中有3个Anchors与两个标签,从位置来看,Anchor A、C分别和标签M、 N有一定的重叠,可以认为Anchor A和C属于前景区域,而Anchor B位置更像是背景。
分类真值
对于分类的真值, 由于RPN只负责区域生成,为了保证尽可能多的recall, 所以没必要细分每一个区域属于哪一个类别, 因此只需要前景与背景两个类别, 前景即有物体, 背景则没有物体。
为了确定锚框属于前景还是属于背景,Faster RCNN通过计算RPN通过计算Anchor与标签的IoU来判断一个Anchor是属于前景还是背景。 IoU的含义是两个框的公共部分占所有部分的比例, 即重合比例。 在上图中, Anchor A与标签M的IoU计算公式如式所示。
I o U ( A , M ) = A ⋂ M A ⋃ M IoU(A,M)= \frac{A \bigcap M}{A \bigcup M} IoU(A,M)=A⋃MA⋂M
当IoU大于一定值时,该Anchor的真值为前景,低于一定值时,该Anchor的真值为背景。
偏移量的真值
对于偏移量的真值,需要知道的一点我们生成锚框坐标形式是左上角和右下角坐标,真实边框的坐标形式也是是左上角和右下角坐标,而RPN网络输出的是中心点横纵坐标及宽高相对于真值的偏移量,所以在实际使用中,我们需要先将左上角和右下角坐标形式先变换成中心点横纵坐标及宽高的形式。
仍以上图的Anchor A与标签M为例,假设Anchor A的中心坐标为xa与ya,宽高分别为wa与ha, 标签M的中心坐标为x与y,宽高分别为w与h,则对应的偏移真值计算公式如式下所示。
{ t x = ( x − x a ) w a t y = ( y − y a ) h a t w = log w w a t h = log h h a \begin{cases} t_x=\frac{(x-x_a)}{w_a} \\ t_y=\frac{(y-y_a)}{h_a} \\ t_w = \log \frac{w}{w_a} \\ t_h = \log \frac{h}{h_a}\end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧tx=wa(x−xa)ty=ha(y−ya)tw=logwawth=loghah
从上式中可以看到, 位置偏移tx与ty利用宽与高进行了归一化, 而宽高偏移tw与th进行了对数处理, 这样的好处是进一步限制了偏移量的范围,便于预测。
如果没有Anchor,做物体检测需要直接预测每个框的坐标,由于框的坐标变化幅度大, 使网络很难收敛与准确预测,而Anchor相当于提供了一个先验的阶梯,使得模型去预测Anchor的偏移量, 即可更好地接近真实物体。
实际上,Anchor是我们想要预测属性的先验参考值,并不局限于矩形框。如果需要,我们也可以增加其他类型的先验,如多边形框、 角度和速度等。
真值生成
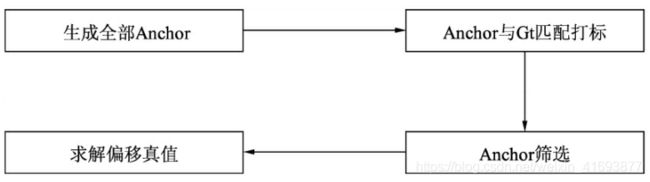
上面我们已经知道了怎么得到分类与偏移预测的真值, 具体指的是每一个Anchor是否对应着真实物体, 以及每一个Anchor对应物体的真实偏移值。 求真值的具体实现过程如下图所示, 主要包含4步, 下面具体介绍,代码列关键部分,就不全部展示了,感兴趣的话,可以从总览那里面提供GitHub链接下载全部代码。本篇博客所讲的具体源码在lib/model/rpn/anchor_target_layer.py下
Anchor生成
这一部分的内容以及在RPN(一)里已经提了一些了,但是需要注意的一点是,在(一)里面只是生成了特征图上最左上角的特征点的锚框(特征图上的每一个特征点都对应着9个锚框,所以可以得到37×50×9=16650个锚框),所以需要这九个锚框复制到整个特征图上。此外,由于按照这种方式生成的Anchor会有一些边界在图像边框外,因此还需要把这部分超过图像边框的Anchors过滤掉。
源码
rpn_cls_score = input[0] # RPN网络分类分支的输出,shape为[batch,18,37,50]
gt_boxes = input[1] # 真实边框的左上角和右下角坐标,shape[batch, K, 5]
im_info = input[2] # 图像的宽和高
num_boxes = input[3] # 真实边框的数量
# 特征图的高和宽,分别是37,50
height, width = rpn_cls_score.size(2), rpn_cls_score.size(3)
# 批处理大小
batch_size = gt_boxes.size(0)
feat_height, feat_width = rpn_cls_score.size(2), rpn_cls_score.size(3)
# 生成锚框坐标的移动量
shift_x = np.arange(0, feat_width) * self._feat_stride # [0, 16, 32, ...., 784]
shift_y = np.arange(0, feat_height) * self._feat_stride # [0, 16, 32, ...., 576]
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
# x = [[0, 16, 32, ...., 784], [0, 16, 32, ...., 784],...., [0, 16, 32, ...., 784]]
# y = [[0, 0, 0, ....., 0], [16, 16, ...., 16], ....,[576, 576, ...., 576]]
# 利用numpy首先得到锚框每个坐标的移动量,并利用contiguous保证内存连续
shifts = torch.from_numpy(np.vstack((shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel())).transpose())
# shifts = [[0, 0, 0, 0], [16, 0, 16, 0], .....[784, 576, 784, 576]]
shifts = shifts.contiguous().type_as(rpn_cls_score).float()
A = self._num_anchors # 每个特征点锚框的数量, 数量为9
K = shifts.size(0) # 特征点的数量, 数量为1850
# 调用基础anchor加上偏移量生成所有anchors
self._anchors = self._anchors.type_as(gt_boxes) # move to specific gpu.
all_anchors = self._anchors.view(1, A, 4) + shifts.view(K, 1, 4) # 利用pytorch的广播机制
all_anchors = all_anchors.view(K * A, 4) # 修改形状,(16650, 4)
total_anchors = int(K * A)
# 生成满足条件的0-1向量,满足条件为1,不满足为0,长度为(16650,)
keep = ((all_anchors[:, 0] >= -self._allowed_border) &
(all_anchors[:, 1] >= -self._allowed_border) &
(all_anchors[:, 2] < long(im_info[0][1]) + self._allowed_border) &
(all_anchors[:, 3] < long(im_info[0][0]) + self._allowed_border))
# 保留边框内的anchors
inds_inside = torch.nonzero(keep).view(-1) # 返回不为0的索引位置
anchors = all_anchors[inds_inside, :] # 取满足条件的锚框,shape为[N, 4]
Anchor与标签的匹配
为了计算Anchor的损失,在生成Anchor之后,我们还需要得到每个Anchor的类别, 由于RPN的作用是建议框生成,而非详细的分类,因此只需要区分正样本与负样本,即每个Anchor是属于正样本还是负样本。前面已经介绍了通过计算Anchor与标签的IoU来判断是正样本还是负样本。在具体实现时,需要计算每一个Anchor与每一个标签的IoU,因此会得到一个IoU矩阵, 具体的判断标准如下:
1. 对于任何一个Anchor, 与所有标签的最大IoU小于0.3, 则视为负样本。
2. 对于任何一个标签, 与其有最大IoU的Anchor视为正样本。
3. 对于任何一个Anchor, 与所有标签的最大IoU大于0.7, 则视为正样本。
# 生成标签向量,对应每一个anchor的状态,1为正,0为负,初始化为-1
labels = gt_boxes.new(batch_size, inds_inside.size(0)).fill_(-1)
bbox_inside_weights = gt_boxes.new(batch_size, inds_inside.size(0)).zero_()
bbox_outside_weights = gt_boxes.new(batch_size, inds_inside.size(0)).zero_()
# 生成IoU矩阵,每一行代表一个anchor,每一列代表一个标签,
# shape为(B,N, K),B为batch, N为锚框数量,K为真实边框数量
overlaps = bbox_overlaps_batch(anchors, gt_boxes)
# 对每一行求最大值,返回的第一个为最大值,第二个为最大值的位置
max_overlaps, argmax_overlaps = torch.max(overlaps, 2)
# 对每一列取最大值,返回的是每一个标签对应的IoU最大值
gt_max_overlaps, _ = torch.max(overlaps, 1)
# 如果一个anchor最大的IoU小于0.3,视为负样本
if not cfg.TRAIN.RPN_CLOBBER_POSITIVES:
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
# 与所有anchors的最大IoU为0的标签要过滤掉
gt_max_overlaps[gt_max_overlaps==0] = 1e-5
# 将与标签有最大IoU的anchor赋予正样本
keep = torch.sum(overlaps.eq(gt_max_overlaps.view(batch_size,1,-1).expand_as(overlaps)), 2)
if torch.sum(keep) > 0:
labels[keep>0] = 1
# 如果一个anchor最大的IoU大于0.7,视为正样本
labels[max_overlaps >= cfg.TRAIN.RPN_POSITIVE_OVERLAP] = 1
需要注意的是, 述三者的顺序不能随意变动,要保证一个Anchor既符合正样本,也符合负样本时 赋予正样本。并且为了保证这一阶段的召回率,允许多个Anchors对应一个标签,而不允许一个标签对应多个Anchors。
生成IoU矩阵函数:bbox_overlaps_batch
因为anchors的维度只有二维,所以主要运行的是anchors.dim() == 2内的代码,注释也只注释这一部分
def bbox_overlaps_batch(anchors, gt_boxes):
"""
anchors: (N, 4) ndarray of float
gt_boxes: (b, K, 5) ndarray of float
overlaps: (N, K) ndarray of overlap between boxes and query_boxes
"""
batch_size = gt_boxes.size(0)
if anchors.dim() == 2:
N = anchors.size(0) # 在边界内的锚框数量, 大小为N
K = gt_boxes.size(1) # 真实边框的数量,大小为K
anchors = anchors.view(1, N, 4).expand(batch_size, N, 4).contiguous() # 将锚框复制batch份,并利用contiguous保证内存连续
gt_boxes = gt_boxes[:,:,:4].contiguous() # 取前四维,第五维是物体类别
gt_boxes_x = (gt_boxes[:,:,2] - gt_boxes[:,:,0] + 1) # 获取真实边框的宽
gt_boxes_y = (gt_boxes[:,:,3] - gt_boxes[:,:,1] + 1) # 获取真实边框的高
gt_boxes_area = (gt_boxes_x * gt_boxes_y).view(batch_size, 1, K) # 获取真实边框的面积
anchors_boxes_x = (anchors[:,:,2] - anchors[:,:,0] + 1) # 获取锚框的宽
anchors_boxes_y = (anchors[:,:,3] - anchors[:,:,1] + 1) # 获取锚框的宽
anchors_area = (anchors_boxes_x * anchors_boxes_y).view(batch_size, N, 1) # 获取锚框的面积
gt_area_zero = (gt_boxes_x == 1) & (gt_boxes_y == 1)
anchors_area_zero = (anchors_boxes_x == 1) & (anchors_boxes_y == 1)
# 修改形状使得真实边框和锚框的shape一致
boxes = anchors.view(batch_size, N, 1, 4).expand(batch_size, N, K, 4)
query_boxes = gt_boxes.view(batch_size, 1, K, 4).expand(batch_size, N, K, 4)
# 求解IoU
iw = (torch.min(boxes[:,:,:,2], query_boxes[:,:,:,2]) -
torch.max(boxes[:,:,:,0], query_boxes[:,:,:,0]) + 1)
iw[iw < 0] = 0
ih = (torch.min(boxes[:,:,:,3], query_boxes[:,:,:,3]) -
torch.max(boxes[:,:,:,1], query_boxes[:,:,:,1]) + 1)
ih[ih < 0] = 0
ua = anchors_area + gt_boxes_area - (iw * ih)
overlaps = iw * ih / ua
# mask the overlap here.
overlaps.masked_fill_(gt_area_zero.view(batch_size, 1, K).expand(batch_size, N, K), 0)
overlaps.masked_fill_(anchors_area_zero.view(batch_size, N, 1).expand(batch_size, N, K), -1)
elif anchors.dim() == 3:
N = anchors.size(1)
K = gt_boxes.size(1)
if anchors.size(2) == 4:
anchors = anchors[:,:,:4].contiguous()
else:
anchors = anchors[:,:,1:5].contiguous()
gt_boxes = gt_boxes[:,:,:4].contiguous()
gt_boxes_x = (gt_boxes[:,:,2] - gt_boxes[:,:,0] + 1)
gt_boxes_y = (gt_boxes[:,:,3] - gt_boxes[:,:,1] + 1)
gt_boxes_area = (gt_boxes_x * gt_boxes_y).view(batch_size, 1, K)
anchors_boxes_x = (anchors[:,:,2] - anchors[:,:,0] + 1)
anchors_boxes_y = (anchors[:,:,3] - anchors[:,:,1] + 1)
anchors_area = (anchors_boxes_x * anchors_boxes_y).view(batch_size, N, 1)
gt_area_zero = (gt_boxes_x == 1) & (gt_boxes_y == 1)
anchors_area_zero = (anchors_boxes_x == 1) & (anchors_boxes_y == 1)
boxes = anchors.view(batch_size, N, 1, 4).expand(batch_size, N, K, 4)
query_boxes = gt_boxes.view(batch_size, 1, K, 4).expand(batch_size, N, K, 4)
iw = (torch.min(boxes[:,:,:,2], query_boxes[:,:,:,2]) -
torch.max(boxes[:,:,:,0], query_boxes[:,:,:,0]) + 1)
iw[iw < 0] = 0
ih = (torch.min(boxes[:,:,:,3], query_boxes[:,:,:,3]) -
torch.max(boxes[:,:,:,1], query_boxes[:,:,:,1]) + 1)
ih[ih < 0] = 0
ua = anchors_area + gt_boxes_area - (iw * ih)
overlaps = iw * ih / ua
# mask the overlap here.
overlaps.masked_fill_(gt_area_zero.view(batch_size, 1, K).expand(batch_size, N, K), 0)
overlaps.masked_fill_(anchors_area_zero.view(batch_size, N, 1).expand(batch_size, N, K), -1)
else:
raise ValueError('anchors input dimension is not correct.')
return overlaps
锚框的筛选
之前我们也算过啦,一共有37×50×9=16650个锚框,就算丢弃掉超出边界的锚框,还是剩下很多锚框。在这些锚框中大部分的标签都是背景,如果都计算损失的话则正、负样本失去了均衡,不利于网络的收敛。对此,Faster RCNN的解决办法就是只选择一部分锚框进行训练,RPN默认选择256个Anchors进行损失的计算,其中最多不超过128个的正样本。如果数量超过了限定值,则进行随机选取。 当然,这里的256与128都可以根据实际情况进行调整, 而不是固定死的。
# 取正样本的数量
# TRAIN.RPN_FG_FRACTION是指取正样本的比例,默认是0.5
# TRAIN.RPN_BATCHSIZE是指选择锚框的数量
num_fg = int(cfg.TRAIN.RPN_FG_FRACTION * cfg.TRAIN.RPN_BATCHSIZE)
# 计算前景锚框和背景锚框分别有多少
sum_fg = torch.sum((labels == 1).int(), 1)
sum_bg = torch.sum((labels == 0).int(), 1)
for i in range(batch_size):
# 如果正样本数量太多,则进行下采样随机选取
if sum_fg[i] > num_fg:
fg_inds = torch.nonzero(labels[i] == 1).view(-1) # 取labels中正样本的索引
# torch.randperm seems has a bug on multi-gpu setting that cause the segfault.
# See https://github.com/pytorch/pytorch/issues/1868 for more details.
# use numpy instead.
#rand_num = torch.randperm(fg_inds.size(0)).type_as(gt_boxes).long()
# 生成长度跟正样本数量一致的随机数
rand_num = torch.from_numpy(np.random.permutation(fg_inds.size(0))).type_as(gt_boxes).long()
disable_inds = fg_inds[rand_num[:fg_inds.size(0)-num_fg]] # 取不参与训练的正样本索引
labels[i][disable_inds] = -1 # 将不参与练的正样本置为-1
# 负样本同上
num_bg = cfg.TRAIN.RPN_BATCHSIZE - torch.sum((labels == 1).int(), 1)[i]
# subsample negative labels if we have too many
if sum_bg[i] > num_bg:
bg_inds = torch.nonzero(labels[i] == 0).view(-1)
#rand_num = torch.randperm(bg_inds.size(0)).type_as(gt_boxes).long()
rand_num = torch.from_numpy(np.random.permutation(bg_inds.size(0))).type_as(gt_boxes).long()
disable_inds = bg_inds[rand_num[:bg_inds.size(0)-num_bg]]
labels[i][disable_inds] = -1
求解回归真值
前面第二步在真实边框与锚框匹配时,已经将每个Anchor赋予正样本或者负样本代表了预测类别的真
值,当然锚框的标签属于负样本的话。是不参与计算回归损失的。现在我们需要知道那些标签为正样本的锚框与真实边框的偏移值,以便后面计算回归损失,具体公式见偏移量的真值。
得到偏移量的真值后,将其保存在bbox_targets中。与此同时, 还需要求解两个权值矩阵bbox_inside_weights和bbox_outside_weights,前者是用来设置正样本回归的权重,正样本设置为1,负样本设置为0,因为负样本对应的是背景, 不需要进行回归; 后者的作用则是平衡RPN分类损失与回归损失的权重,在此设置为1/256。
# batch长度的偏移量
offset = torch.arange(0, batch_size)*gt_boxes.size(1)
# argmax_overlaps为前面IoU矩阵时求的每一行的最大值索引,shape为(b,N),因为后面在取gt_boxes会将其从
#(b,K,5)修改成(b*K,5),所以需要对argmax_overlaps的值加上每个batch内的真实边框的数量,即N
argmax_overlaps = argmax_overlaps + offset.view(batch_size, 1).type_as(argmax_overlaps)
# 选择每一个anchor对应最大IoU的标签进行偏移计算,shape(b, N, 4)
bbox_targets = _compute_targets_batch(anchors, gt_boxes.view(-1,5)[argmax_overlaps.view(-1), :].view(batch_size, -1, 5))
# 设置两个权重向量, 正样本权重为1,负样本权重为0
bbox_inside_weights[labels==1] = cfg.TRAIN.RPN_BBOX_INSIDE_WEIGHTS[0]
# RPN_POSITIVE_WEIGHT如果设定了,那么正样本的权重为p*1/{num posities},负样本一个权重(1-p)
#如果设定为-1.0以使用统一的示例权重
if cfg.TRAIN.RPN_POSITIVE_WEIGHT < 0:
num_examples = torch.sum(labels[i] >= 0)
positive_weights = 1.0 / num_examples.item()
negative_weights = 1.0 / num_examples.item()
else:
assert ((cfg.TRAIN.RPN_POSITIVE_WEIGHT > 0) &
(cfg.TRAIN.RPN_POSITIVE_WEIGHT < 1))
bbox_outside_weights[labels == 1] = positive_weights
bbox_outside_weights[labels == 0] = negative_weights
# 将labels、bbox_targets、bbox_inside_weights、bbox_outside_weights还原到最初锚框
# 数量状态,即还原后的形状为(batch,16650),bbox_targets的shape(batch,16650,4)
# inds_inside保存的没有超出边界的锚框索引
labels = _unmap(labels, total_anchors, inds_inside, batch_size, fill=-1)
bbox_targets = _unmap(bbox_targets, total_anchors, inds_inside, batch_size, fill=0)
bbox_inside_weights = _unmap(bbox_inside_weights, total_anchors, inds_inside, batch_size, fill=0)
bbox_outside_weights = _unmap(bbox_outside_weights, total_anchors, inds_inside, batch_size, fill=0)
outputs = []
# A是锚框数量,height和width分别是特征图的高宽
# 修改后的labels的shape为(batch, 1, 333, 50)
labels = labels.view(batch_size, height, width, A).permute(0,3,1,2).contiguous()
labels = labels.view(batch_size, 1, A * height, width)
outputs.append(labels)
# 修改后的bbox_targets的shape为(batch, 36, 37, 50)
bbox_targets = bbox_targets.view(batch_size, height, width, A*4).permute(0,3,1,2).contiguous()
outputs.append(bbox_targets)
# 修改后的bbox_inside_weights的shape为(batch, 36, 37, 50)
anchors_count = bbox_inside_weights.size(1)
bbox_inside_weights = bbox_inside_weights.view(batch_size,anchors_count,1).expand(batch_size, anchors_count, 4)
bbox_inside_weights = bbox_inside_weights.contiguous().view(batch_size, height, width, 4*A)\
.permute(0,3,1,2).contiguous()
outputs.append(bbox_inside_weights)
# 修改后的bbox_outside_weights的shape为(batch, 36, 37, 50)
bbox_outside_weights = bbox_outside_weights.view(batch_size,anchors_count,1).expand(batch_size, anchors_count, 4)
bbox_outside_weights = bbox_outside_weights.contiguous().view(batch_size, height, width, 4*A)\
.permute(0,3,1,2).contiguous()
outputs.append(bbox_outside_weights)
def _compute_targets_batch(ex_rois, gt_rois):
"""Compute bounding-box regression targets for an image."""
return bbox_transform_batch(ex_rois, gt_rois[:, :, :4])
因为anchors的维度只有二维,所以主要运行的是anchors.dim() == 2内的代码,注释也只注释这一部分
def bbox_transform_batch(ex_rois, gt_rois):
"""
ex_rois: (N, 4) ndarray of float or (b, N, 4) ndarray of float
gt_rois: (b, N, 4) ndarray of float
targets: (b, N, 4) ndarray of bounding-box regression targets for an image
"""
if ex_rois.dim() == 2:
# 计算锚框的中心坐标和宽高
ex_widths = ex_rois[:, 2] - ex_rois[:, 0] + 1.0
ex_heights = ex_rois[:, 3] - ex_rois[:, 1] + 1.0
ex_ctr_x = ex_rois[:, 0] + 0.5 * ex_widths
ex_ctr_y = ex_rois[:, 1] + 0.5 * ex_heights
# 计算与每一个锚框有最大IoU的真实边框的中心坐标和宽高
gt_widths = gt_rois[:, :, 2] - gt_rois[:, :, 0] + 1.0
gt_heights = gt_rois[:, :, 3] - gt_rois[:, :, 1] + 1.0
gt_ctr_x = gt_rois[:, :, 0] + 0.5 * gt_widths
gt_ctr_y = gt_rois[:, :, 1] + 0.5 * gt_heights
# 计算每一个锚框的回归偏移量
targets_dx = (gt_ctr_x - ex_ctr_x.view(1,-1).expand_as(gt_ctr_x)) / ex_widths
targets_dy = (gt_ctr_y - ex_ctr_y.view(1,-1).expand_as(gt_ctr_y)) / ex_heights
targets_dw = torch.log(gt_widths / ex_widths.view(1,-1).expand_as(gt_widths))
targets_dh = torch.log(gt_heights / ex_heights.view(1,-1).expand_as(gt_heights))
elif ex_rois.dim() == 3:
ex_widths = ex_rois[:, :, 2] - ex_rois[:, :, 0] + 1.0
ex_heights = ex_rois[:,:, 3] - ex_rois[:,:, 1] + 1.0
ex_ctr_x = ex_rois[:, :, 0] + 0.5 * ex_widths
ex_ctr_y = ex_rois[:, :, 1] + 0.5 * ex_heights
gt_widths = gt_rois[:, :, 2] - gt_rois[:, :, 0] + 1.0
gt_heights = gt_rois[:, :, 3] - gt_rois[:, :, 1] + 1.0
gt_ctr_x = gt_rois[:, :, 0] + 0.5 * gt_widths
gt_ctr_y = gt_rois[:, :, 1] + 0.5 * gt_heights
targets_dx = (gt_ctr_x - ex_ctr_x) / ex_widths
targets_dy = (gt_ctr_y - ex_ctr_y) / ex_heights
targets_dw = torch.log(gt_widths / ex_widths)
targets_dh = torch.log(gt_heights / ex_heights)
else:
raise ValueError('ex_roi input dimension is not correct.')
targets = torch.stack(
(targets_dx, targets_dy, targets_dw, targets_dh),2)
return targets
def _unmap(data, count, inds, batch_size, fill=0):
""" Unmap a subset of item (data) back to the original set of items (of
size count) """
if data.dim() == 2:
ret = torch.Tensor(batch_size, count).fill_(fill).type_as(data)
ret[:, inds] = data
else:
ret = torch.Tensor(batch_size, count, data.size(2)).fill_(fill).type_as(data)
ret[:, inds,:] = data
return ret