机器学习训练_金融风控_Task2_EDA
此部分为零基础入门金融风控的 Task2 数据分析部分,带你来了解数据,熟悉数据,为后续的特征工程做准备,欢迎大家后续多多交流。
赛题:零基础入门数据挖掘 - 零基础入门金融风控之贷款违约
目的:
1.EDA价值主要在于熟悉了解整个数据集的基本情况(缺失值,异常值),对数据集进行验证是否可以进行接下来的机器学习或者深度学习建模.
2.了解变量间的相互关系、变量与预测值之间的存在关系。
3.为特征工程做准备
这里主要记录了代码部分
一、导入第三方模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
pd.options.display.max_columns = None
pd.set_option('display.float_format', lambda x: '%.2f' % x)
二、数据读取
train = pd.read_csv(r'D:\Users\Felixteng\Documents\Pycharm Files\loanDefaultForecast\data\train.csv')
由于数据量有 80w 左右,做一个数据的压缩处理,方便计算和训练,这里创建一个reduce_mem_usage函数,通过调整数据类型,减少数据在内存中占用的空间
def reduce_mem_usage(df):
'''
遍历DataFrame的所有列并修改它们的数据类型以减少内存使用
:param df: 需要处理的数据集
:return:
'''
start_mem = df.memory_usage().sum() / 1024 ** 2 # 记录原数据的内存大小
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtypes
if col_type != object: # 这里只过滤了object格式,如果代码中还包含其他类型,要一并过滤
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int': # 如果是int类型的话,不管是int64还是int32,都加入判断
# 依次尝试转化成in8,in16,in32,in64类型,如果数据大小没溢出,那么转化
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else: # 不是整形的话,那就是浮点型
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else: # 如果不是数值型的话,转化成category类型
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024 ** 2 # 看一下转化后的数据的内存大小
print('Memory usage after optimization is {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem)) # 看一下压缩比例
return df
压缩数据
train = reduce_mem_usage(train)
'''
Memory usage of dataframe is 286.87 MB
Memory usage after optimization is 69.46 MB
Decreased by 75.8%
'''
可以看出,压缩率不低。
三、仔细看看特征
train.info()
'''
loanAmnt - 贷款金额
term - 贷款期限(年)
interestRate - 贷款利率
installment - 分期付款金额
grade - 贷款等级
subGrade - 贷款等级之子集
employmentTitle - 就业职称
employmentLength - 就业年限(年)
homeOwnership - 借款人在登记时提供的房屋所有权状况 --- int型,建议检查是否转化为类别型
annualIncome - 年收入
verificationStatus - 验证状态 --- int型,建议检查是否转化为类别型
issueDate - 贷款发放的月份 --- category型,建议检查是否转化为日期格式
purpose - 借款人在贷款申请时的贷款用途类别 --- int型,建议检查是否转化为类别型
postCode - 借款人在贷款申请中提供的邮政编码的前3位数字 --- float型,建议检查是否转化为类别型/category
regionCode - 地区编码 --- int型,建议检查是否转化为类别型/category
dti - 债务收入比
delinquency_2years - 借款人过去2年信用档案中逾期30天以上的违约事件数 --- float型,建议检查是否转化为int型
ficoRangeLow - 借款人在贷款发放时的fico所属的下限范围
ficoRangeHigh - 借款人在贷款发放时的fico所属的上限范围
openAcc - 借款人信用档案中未结信用额度的数量 --- float型,建议检查是否转化为int型
pubRec - 贬损公共记录的数量 --- float型,建议检查是否转化为int型
pubRecBankruptcies - 公开记录清除的数量 --- float型,建议检查是否转化为int型
revolBal - 信贷周转余额合计
revolUtil - 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额
totalAcc - 借款人信用档案中当前的信用额度总数
initialListStatus - 贷款的初始列表状态 --- int型,建议检查是否转化成类别型/category
applicationType - 表明贷款是个人申请还是与两个共同借款人的联合申请 --- int型,建议检查是否转化成类别型/category
earliesCreditLine 借款人最早报告的信用额度开立的月份 --- category型,建议检查是否转化为日期格式
title - 借款人提供的贷款名称 --- float型,建议检查是否转化成类别型/category
policyCode - 公开可用的策略_代码 = 1 / 新产品不公开可用的策略_代码 = 2 --- float型,建议检查是否转化成类别型/category
n0-n14 - 匿名特征
'''
分析可疑待调整数据类型的特征
'''
homeOwnership - 借款人在登记时提供的房屋所有权状况 --- int型,建议检查是否转化为类别型
verificationStatus - 验证状态 --- int型,建议检查是否转化为类别型
issueDate - 贷款发放的月份 --- category型,建议检查是否转化为日期格式
purpose - 借款人在贷款申请时的贷款用途类别 --- int型,建议检查是否转化为类别型
postCode - 借款人在贷款申请中提供的邮政编码的前3位数字 --- float型,建议检查是否转化为类别型/category
regionCode - 地区编码 --- int型,建议检查是否转化为类别型/category
delinquency_2years - 借款人过去2年信用档案中逾期30天以上的违约事件数 --- float型,建议检查是否转化为int型
openAcc - 借款人信用档案中未结信用额度的数量 --- float型,建议检查是否转化为int型
pubRec - 贬损公共记录的数量 --- float型,建议检查是否转化为int型
pubRecBankruptcies - 公开记录清除的数量 --- float型,建议检查是否转化为int型
initialListStatus - 贷款的初始列表状态 --- int型,建议检查是否转化成类别型/category
applicationType - 表明贷款是个人申请还是与两个共同借款人的联合申请 --- int型,建议检查是否转化成类别型/category
earliesCreditLine 借款人最早报告的信用额度开立的月份 --- category型,建议检查是否转化为日期格式
title - 借款人提供的贷款名称 --- float型,建议检查是否转化成类别型/category
policyCode - 公开可用的策略_代码 = 1 / 新产品不公开可用的策略_代码 = 2 --- float型,建议检查是否转化成类别型/category
'''
homeOwnership - 借款人在登记时提供的房屋所有权状况 — int型,建议检查是否转化为类别型
train.groupby('homeOwnership')['id'].count()
'''
这个字段大概率为借款人的房屋拥有量,无需转化为类别型
homeOwnership
0 395732
1 317660
2 86309
3 185
4 33
5 81
Name: id, dtype: int64
'''
verificationStatus - 验证状态 — int型,建议检查是否转化为类别型
train.groupby('verificationStatus')['id'].count()
'''转化成类别型'''
train['verificationStatus'] = train['verificationStatus'].astype('category')
issueDate - 贷款发放的月份 — category型,建议检查是否转化为日期格式
train.groupby('issueDate')['id'].count()
'''转化成时间类型'''
train['issueDate'] = train['issueDate'].astype('datetime64')
purpose - 借款人在贷款申请时的贷款用途类别 — int型,建议检查是否转化为类别型
train.groupby('purpose')['id'].count()
'''转化成类别型'''
train['purpose'] = train['purpose'].astype('category')
postCode - 借款人在贷款申请中提供的邮政编码的前3位数字 — float型,建议检查是否转化为类别型/category
train.groupby('postCode')['id'].count()
'''转化成类别型,并去掉后三位字符'''
train['postCode'] = train['postCode'].astype('category')
train['postCode'] = train['postCode'].apply(lambda x: str(x)[:-2])
regionCode - 地区编码 — int型,建议检查是否转化为类别型/category
train.groupby('regionCode')['id'].count()
'''转化成类别型'''
train['regionCode'] = train['regionCode'].astype('category')
delinquency_2years - 借款人过去2年信用档案中逾期30天以上的违约事件数 — float型,建议检查是否转化为int型
train['delinquency_2years'].head(50)
'''转化成整形'''
train['delinquency_2years'] = train['delinquency_2years'].astype('int8')
openAcc - 借款人信用档案中未结信用额度的数量 — float型,建议检查是否转化为int型
train['openAcc'].head(50)
'''转化成整形'''
train['openAcc'] = train['openAcc'].astype('int8')
pubRec - 贬损公共记录的数量 — float型,建议检查是否转化为int型
train['pubRec'].head(50)
train.groupby('pubRec')['id'].count()
'''转化成整形'''
train['pubRec'] = train['pubRec'].astype('int8')
pubRecBankruptcies - 公开记录清除的数量 — float型,建议检查是否转化为int型
train['pubRecBankruptcies'].head(50)
train.groupby('pubRecBankruptcies')['id'].count()
'''将缺失值标记为-99后,转化成整形'''
train.fillna({'pubRecBankruptcies': -99}, inplace=True)
train['pubRecBankruptcies'] = train['pubRecBankruptcies'].astype('int8')
initialListStatus - 贷款的初始列表状态 — int型,建议检查是否转化成类别型/category
train['initialListStatus'].head(50)
train.groupby('initialListStatus')['id'].count()
'''
转化为类别型
initialListStatus
0 466438
1 333562
'''
train['initialListStatus'] = train['initialListStatus'].astype('category')
applicationType - 表明贷款是个人申请还是与两个共同借款人的联合申请 — int型,建议检查是否转化成类别型/category
train.groupby('applicationType')['id'].count()
'''
转化为类别型
applicationType
0 784586
1 15414
'''
train['applicationType'] = train['applicationType'].astype('category')
earliesCreditLine 借款人最早报告的信用额度开立的月份 — category型,建议检查是否转化为日期格式
train.groupby('earliesCreditLine')['id'].count()
train['earliesCreditLine'].head()
'''转化成时间类型'''
创建辅助列
train['earliesCreditLine_year'] = train['earliesCreditLine'].apply(lambda x: x[-4:])
train['earliesCreditLine_month'] = train['earliesCreditLine'].apply(lambda x: x[0:3])
def month_re(x):
if x == 'Jan':
return '01'
elif x == 'Feb':
return '02'
elif x == 'Mar':
return '03'
elif x == 'Apr':
return '04'
elif x == 'May':
return '05'
elif x == 'Jun':
return '06'
elif x == 'Jul':
return '07'
elif x == 'Aug':
return '08'
elif x == 'Sep':
return '09'
elif x == 'Oct':
return '10'
elif x == 'Nov':
return '11'
else:
return '12'
train['earliesCreditLine_month_2'] = train['earliesCreditLine_month'].apply(lambda x: month_re(x))
train['earliesCreditLine_date'] = train['earliesCreditLine_year'] + '-' + train['earliesCreditLine_month_2']
train['earliesCreditLine'] = train['earliesCreditLine_date'].astype('datetime64')
del train['earliesCreditLine_date']
del train['earliesCreditLine_year']
del train['earliesCreditLine_month']
del train['earliesCreditLine_month_2']
title - 借款人提供的贷款名称 — float型,建议检查是否转化成类别型/category
train.groupby('title')['id'].count()
'''类别很多,不适合转化为category,转化成object'''
train['title'] = train['title'].astype('str')
policyCode - 公开可用的策略_代码 = 1 / 新产品不公开可用的策略_代码 = 2 — float型,建议检查是否转化成类别型/category
train.groupby('policyCode')['id'].count()
'''全是类别1,这个字段没用,可以删了'''
del train['policyCode']
四、看一下各个特征的缺失情况
print(f'There are {train.isnull().any().sum()} columns in train dataset with miss values.')
'''There are 20 columns in train dataset with miss values.'''
进一步查看特征缺失率
have_null_fea_dict = (train.isnull().sum() / len(train)).to_dict()
for key, value in have_null_fea_dict.items():
print(key, value)
'''
整体上没有缺失比例很高的特征
id 0.0
loanAmnt 0.0
term 0.0
interestRate 0.0
installment 0.0
grade 0.0
subGrade 0.0
employmentTitle 1.25e-06
employmentLength 0.05849875
homeOwnership 0.0
annualIncome 0.0
verificationStatus 0.0
issueDate 0.0
isDefault 0.0
purpose 0.0
postCode 1.25e-06
regionCode 0.0
dti 0.00029875
delinquency_2years 0.0
ficoRangeLow 0.0
ficoRangeHigh 0.0
openAcc 0.0
pubRec 0.0
pubRecBankruptcies 0.0
revolBal 0.0
revolUtil 0.00066375
totalAcc 0.0
initialListStatus 0.0
applicationType 0.0
earliesCreditLine 0.0
title 0.0
n0 0.0503375
n1 0.0503375
n2 0.0503375
n2.1 0.0503375
n4 0.04154875
n5 0.0503375
n6 0.0503375
n7 0.0503375
n8 0.05033875
n9 0.0503375
n10 0.04154875
n11 0.08719
n12 0.0503375
n13 0.0503375
n14 0.0503375
'''
绘图看下
missing = train.isnull().sum() / len(train)
missing = missing[missing > 0]
missing.sort_values(inplace=True)
# missing.plot.bar()
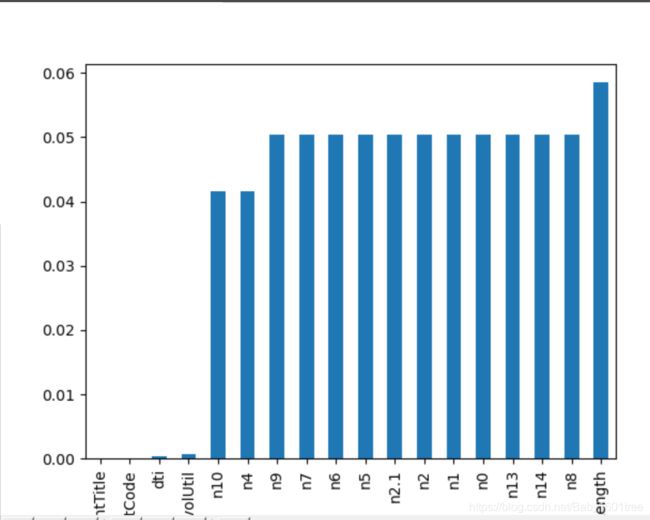
查看特征的数值类型有哪些,对象类型有哪些,将数值型的特征挑出
'''
数值型特征本是可以直接入模的,但往往风控人员要对其做分箱,转化为WOE编码进而做标准评分卡等操作。
从模型效果上来看,特征分箱主要是为了降低变量的复杂性,减少变量噪音对模型的影响,提高自变量和因变量的相关度,从而使模型更加稳定
'''
numerical_fea = list(train.select_dtypes(exclude=['category', 'object']).columns)
category_fea = list(filter(lambda x: x not in numerical_fea, list(train.columns)))
'''
select_dtypes()函数能够根据数据类型选择特征
filter(f, list)
filter()接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False
filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list
'''
数值型变量分析,数值型包括连续型变量和离散型变量的
def get_numerical_serial_fea(data, feas):
numerical_serial_fea = []
numerical_noserial_fea = []
for fea in feas:
temp = data[fea].nunique()
# 如果特征的数值数据不超过10中,那么纳入离散特征范畴,反之纳入连续性数值范畴
if temp <= 10:
numerical_noserial_fea.append(fea)
continue
numerical_serial_fea.append(fea)
return numerical_serial_fea, numerical_noserial_fea
numerical_serial_fea, numerical_noserial_fea = get_numerical_serial_fea(train, numerical_fea)
numerical_serial_fea.remove('earliesCreditLine')
numerical_serial_fea.remove('issueDate')
看看还有有哪些离散型的数值变量
print(numerical_noserial_fea)
'''['term', 'homeOwnership', 'isDefault', 'n11', 'n12']'''
term - 贷款期限(年)
train.groupby('term')['id'].count()
'''只有3年和5年两种,可以考虑转换成类别型数据'''
train['term'] = train['term'].astype('category')
'homeOwnership’已经分析过, 'isDefault’是标签,不动
‘n11’ 匿名变量
train.groupby('n11')['id'].count()
'''分类相差悬殊,几乎都是0.00,无分析价值直接剔除'''
del train['n11']
‘n12’ 匿名变量
train.groupby('n12')['id'].count()
'''同n11一样,分类相差悬殊,几乎都是0.00,无分析价值直接剔除'''
del train['n12']
五、数值连续型变量分析
f = pd.melt(train, value_vars=numerical_serial_fea)
'''melt() - 行列自定义转化'''
g = sns.FacetGrid(f, col='variable', col_wrap=2, sharex=False, sharey=False)
'''
sns.FaceGrid()
一个FacetGrid可以与多达三个维度可以得出:row,col,和hue。前两个与得到的轴阵列有明显的对应关系;
将色调变量视为沿深度轴的第三个维度,其中不同的级别用不同的颜色绘制。
通过使用FacetGrid数据框初始化对象以及将形成网格的行,列或色调维度的变量名称来使用该类。
这些变量应该是分类的或离散的,然后变量的每个级别的数据将用于沿该轴的小平面。
data - 处理后的(“长格式”)dataframe数据,其中每一列都是一个变量(特征),每一行都是一个样本
col - 定义数据子集的变量,这些变量将在网格的不同方面绘制
col_wrap - 图网格列维度限制,比如col_wrap =3,那么在这个画布里最多只能画3列,行不限制,这样就限制了列的个数
'''
g = g.map(sns.distplot, 'value')
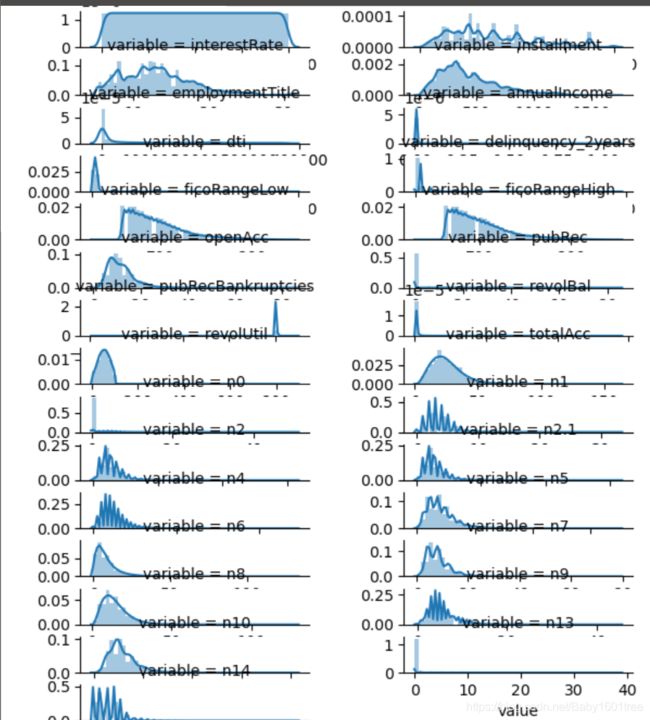
查看某一个数值型变量的分布,查看变量是否符合正态分布,如果不符合正太分布的变量可以log化后再观察下是否符合正态分布
六、变量分布可视化
单一变量分布可视化,以employmentLength为例
plt.figure(figsize=(8, 8))
sns.barplot(train['employmentLength'].value_counts(dropna=False)[:20],
train['employmentLength'].value_counts(dropna=False).keys()[:20])
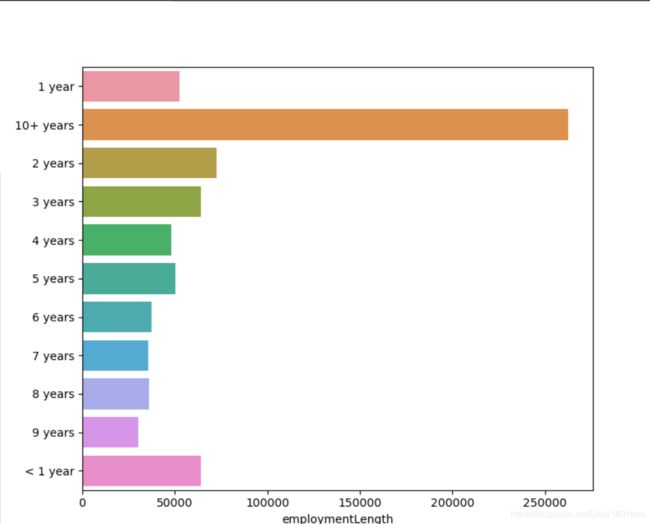
根据标签不同可视化x某个特征的分布
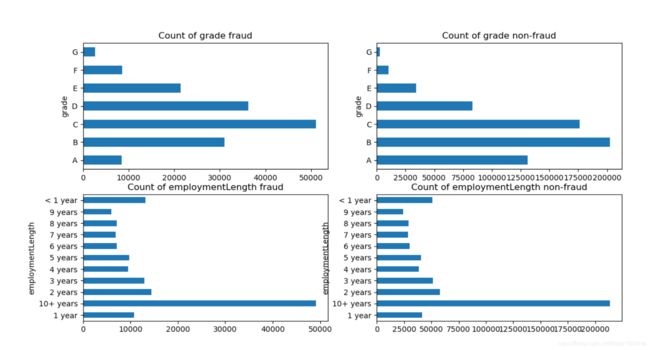
首先查看类别型变量在不同标签值上的分布
'''将不同标签的数据分开'''
train_loan_fr = train.loc[train['isDefault'] == 1]
train_loan_nofr = train.loc[train['isDefault'] == 0]
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 8))
'''建立画布'''
train_loan_fr.groupby('grade')['id'].count().plot(kind='barh', ax=ax1, title='Count of grade fraud')
'''逾期数据下,不同grade的分布情况,画在子画布1上'''
train_loan_nofr.groupby('grade')['id'].count().plot(kind='barh', ax=ax2, title='Count of grade non-fraud')
'''非逾期数据下,不同grade的分布情况,画在子画布2上'''
train_loan_fr.groupby('employmentLength')['id'].count().plot(kind='barh', ax=ax3,
title='Count of employmentLength fraud')
'''逾期数据下,不同employmentLength的分布情况,画在子画布3上'''
train_loan_nofr.groupby('employmentLength')['id'].count().plot(kind='barh', ax=ax4,
title='Count of employmentLength non-fraud')
'''非逾期数据下,不同employmentLength的分布情况,画在子画布4上'''
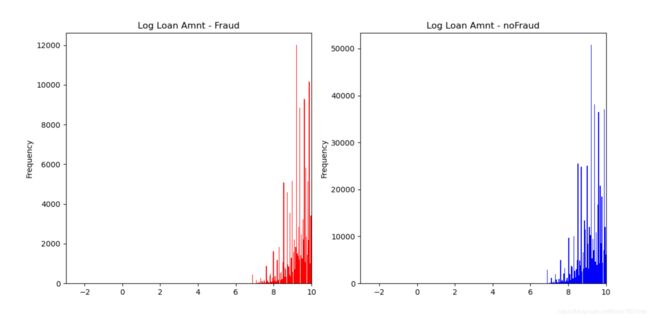
再查看连续数值型变量在不同标签值上的分布,以loanAmnt为例
fig2, ((ax5, ax6)) = plt.subplots(1, 2, figsize=(15, 6))
train_loan_fr['loanAmnt'].apply(np.log).plot(kind='hist', bins=100,
title='Log Loan Amnt - Fraud', color='r', xlim=(-3, 10), ax=ax5)
train_loan_nofr['loanAmnt'].apply(np.log).plot(kind='hist', bins=100,
title='Log Loan Amnt - noFraud', color='b', xlim=(-3, 10), ax=ax6)
七、总结
EDA阶段是对数据的一个探索,大致了解一下数据的类型、分布、基本质量、相关性等。详细的处理在下一章节特征工程会涉及。