Python机器学习:多个模型的调用
在做项目的过程中一个个模型地试验太耗费时间,我们可以把多个模型封装到一个方法里,一起调用,统一输出结果,这样对比不同模型的得分就非常便捷啦。
基础的分类算法大全(前8个是十大经典机器学习算法里面的):
| 英文简称 |
模型 |
调用 |
| LR |
LogisticRegression() |
from sklearn.linear_model import LogisticRegression |
| NB |
MultinomialNB() |
from sklearn.naive_bayes import MultinomialNB |
| DT |
DecisionTreeClassifier() |
from sklearn.tree import DecisionTreeClassifier |
| RF |
RandomForestClassifier() |
from sklearn.ensemble import RandomForestClassifier |
| SVM |
svm.SVC() Support Vector Machine |
from sklearn import svm |
| KNN |
KNeighborsClassifier() |
from sklearn.neighbors import KNeighborsClassifier |
| GBDT |
GradientBoostingClassifier() |
from sklearn.ensemble import GradientBoostingClassifier |
| XGBoost |
XGBClassifier() |
from xgboost import XGBClassifier |
| AdaBoost |
AdaBoostClassifier() |
from sklearn.ensemble import AdaBoostClassifier |
| LGB |
lgb.LGBMClassifier() Light Gradient Boosting Machine Classifier |
import lightgbm as lgb |
以上模型都可以用在有监督学习的分类任务里。前8个都是十大经典机器模型里面的,后2个也是比较常用的模型。十大经典机器学习算法还有 线性回归和K-means,线性回归用来预测连续型变量,K-means用在无监督学习的聚类任务,这一期主要解决分类问题就不介绍啦。
调包调用模型:
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn import svm #支持向量机
from sklearn.neighbors import KNeighborsClassifier #K近邻算法
from sklearn.ensemble import GradientBoostingClassifier #梯度提升树
from xgboost import XGBClassifier #极度梯度提升树
from sklearn.ensemble import AdaBoostClassifier #AdaBoost
import lightgbm as lgb #LGB
from sklearn.metrics import roc_auc_score #auc定义方法train_and_score():
def train_and_score(X_train,y_train,X_test,y_test):
models = [
LogisticRegression(), #逻辑回归 LR
DecisionTreeClassifier(), #决策树 DT
RandomForestClassifier(), #随机森林 RF
SVC(probability=True), #支持向量机 SVM
KNeighborsClassifier(), #K近邻算法 KNN
GradientBoostingClassifier(), # 梯度提升树 GBDT
XGBClassifier(),#极度梯度提升树 XGBoost
AdaBoostClassifier(), #集成学习分类器
lgb.LGBMClassifier() #lightgbm
]
for model in models:
model.fit(X_train,y_train)
y_test_proba = model.predict_proba(X_test)[:, 1]
auc = roc_auc_score(y_test, y_test_proba)
print("模型:%s,auc得分:%f;"%(model,auc))代码讲解:
def train_and_score()是方法名,后续调用可以直接使用,里面定义了4个输入参数,分别是训练集的x和y,以及测试集的x和y,是在训练模型和计算得分时要用到的;
models是定义的数组名,存放要用到的模型;
for循环是因为模型有很多个,要把每个模型都遍历一次输出结果;
model in models指数组里面其中一个模型,model.fit()是训练模型的固定语法;
predict_proba()是计算概率值,在用auc作为评分标准的时候使用;而predict()是生成0-1的结果,在计算准确率accuracy、召回率recall、F1值、精确率precision的时候使用;
计算auc是调用包sklearn.metrics 里面的roc_auc_score()方法;
%s和%f是占位符,%s是文本的占位符,%f是浮点数的占位符;
封装好代码后,就可以直接调用方法啦:
train_and_score(X_train,y_train,X_test,y_test)运行结果:
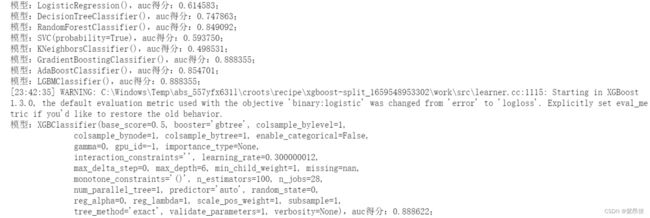
可见得分0.888是这些模型的最高得分了,下一步还可以继续调参或者优化特征提高分数。