For each of the classes predict the presence/absence of atleast one object of that class in a test image
Detection
识别
For each of the classes predict the bounding boxes of each object of that class in a test image (if any).
Segmentation
实例分割
For each pixel in a test image, predict the class of the object containing that pixel or ‘background’ if the pixel does not belong to one of the twenty specified classes. NOTE`:实例分割,不是语义分割
Action Classification
动作分类
For each of the action classes predict if a specifiedperson (indicated by their bounding box) in a test image is performingthe corresponding action. There are ten action classes:
jumping; phoning; playing a musical instrument; reading; riding abicycle or motorcycle; riding a horse; running; taking a photograph;using a computer; walking
Large Scale Recognition
大规模识别
This task is run by the ImageNet organizers.Further details can be found at their website:http://www.image-net.org/challenges/LSVRC/2012/index.
Boxless Action Classification
For each of the action classes predict if aspecified person in a test image is performing the corresponding action.The person is indicated only by a single point lying somewhere on theirbody, rather than by a tight bounding box
Person Layout
or each ‘person’ object in a test image (indicated bya bounding box of the person), predict the presence/absence of parts(head/hands/feet), and the bounding boxes of those parts.
Images were largely taken from exising public datasets, and were not as challenging as the flickr images subsequently used. This dataset is obsolete.图片大部分是从现有的公共数据集中获取的,并不像随后使用的flickr图片那样具有挑战性。此数据集已过时。
Images from flickr (www.flickr.com)and from Microsoft Research Cambridge (MSRC) dataset
The MSRC images were easier than flickr as the photos often concentrated on the object of interest. This dataset is obsolete.MSRC的图片比flickr容易,因为照片通常集中在感兴趣的对象上。此数据集已过时。
Evaluation measure for the classification challenge changed to Average Precision. Previously it had been ROC-AUC.
This year established the 20 classes, and these have been fixed since then. This was the final year that annotation was released for the testing data.07年起设立了20个类别,从那时起就固定下来了。这是为测试数据发布注释的最后一年。
2008
20 classes. The data is split (as usual) around 50% train/val and 50% test. The train/val data has 4,340 images containing 10,363 annotated objects.
Occlusion flag added to annotations
Test data annotation no longer made public.
The segmentation and person layout data sets include images from the corresponding VOC2007 sets.
2009
20 classes. The train/val data has 7,054 images containing 17,218 ROI annotated objects and 3,211 segmentations.
From now on the data for all tasks consists of the previous years' images augmented with new images. In earlier years an entirely new data set was released each year for the classification/detection tasks.
Augmenting allows the number of images to grow each year, and means that test results can be compared on the previous years' images.
Segmentation becomes a standard challenge (promoted from a taster)
No difficult flags were provided for the additional images (an omission).
Test data annotation not made public.
2010
20 classes. The train/val data has 10,103 images containing 23,374 ROI annotated objects and 4,203 segmentations.
Action Classification taster introduced.
Associated challenge on large scale classification introduced based on ImageNet.
Amazon Mechanical Turk used for early stages of the annotation.
Method of computing AP changed. Now uses all data points rather than TREC style sampling.
Test data annotation not made public.
2011
20 classes. The train/val data has 11,530 images containing 27,450 ROI annotated objects and 5,034 segmentations.
Action Classification taster extended to 10 classes + "other".
Layout annotation is now not "complete": only people are annotated and some people may be unannotated.
2012
20 classes. The train/val data has 11,530 images containing 27,450 ROI annotated objects and 6,929 segmentations.
Size of segmentation dataset substantially increased.
People in action classification dataset are additionally annotated with a reference point on the body.
Datasets for classification, detection and person layout are the same as VOC2011.
The detection task will be judged by the precision/recall curve. The principalquantitative measure used will be the average precision (AP) (see section 3.4.1).Example code for computing the precision/recall and AP measure is providedin the development kit.Detections are considered true or false positives based on the area of overlap with ground truth bounding boxes. To be considered a correct detection, thearea of overlapaobetween the predicted bounding boxBp and ground truth bounding boxBgt must exceed 50% by the formula
检测任务将根据精度/召回曲线进行判断。使用的主要定量指标是平均精度(AP)。开发工具包中提供了计算精度/召回和AP指标的示例代码。true or false用IoU评估,大于 50%为true。
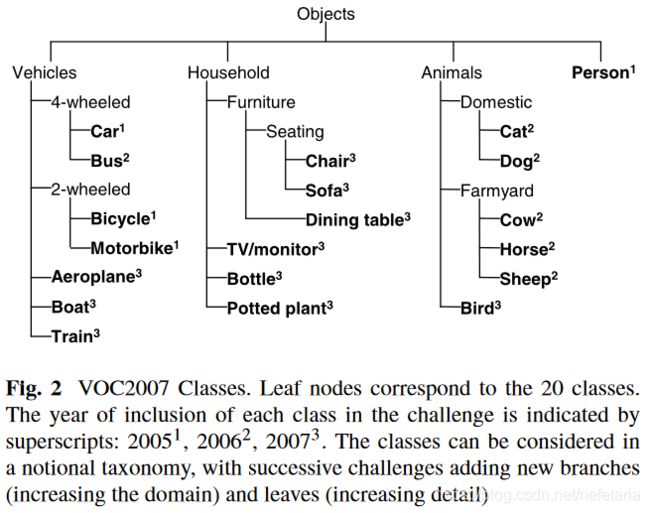
1.4 类别的选择
The choice of object classes, which can be considered a sub-tree of a taxonomy defined in terms of both semantic and visual similarity, also supports research in two areas which show promise in solving the scaling of object recognition to many thousands of classes: (i) exploiting visual properties common to classes e.g. vehicle wheels, for example in the form of “feature sharing” (Torralba et al.2007);(ii) exploiting external semantic information about the relations between object classes e.g. WordNet (Fellbaum1998),for example by learning a hierarchy of classifiers (Marsza-lek and Schmid2007). The availability of a class hierarchy may also prove essential in future evaluation efforts if the number of classes increases to the extent that there is implicit ambiguity in the classes, allowing individual objects to be annotated at different levels of the hierarchy e.g. hatch-back/car/vehicle. We return to this point in Sect.7.3.
.oracle层次查询(connect by)
oracle的emp表中包含了一列mgr指出谁是雇员的经理,由于经理也是雇员,所以经理的信息也存储在emp表中。这样emp表就是一个自引用表,表中的mgr列是一个自引用列,它指向emp表中的empno列,mgr表示一个员工的管理者,
select empno,mgr,ename,sal from e
SAPHANA平台有各种各样的应用场景,这也意味着客户的实施方法有许多种选择,关键是如何挑选最适合他们需求的实施方案。
在 《Implementing SAP HANA》这本书中,介绍了SAP平台在现实场景中的运作原理,并给出了实施建议和成功案例供参考。本系列文章节选自《Implementing SAP HANA》,介绍了行存储和列存储的各自特点,以及SAP HANA的数据存储方式如何提升空间压
学习Java有没有什么捷径?要想学好Java,首先要知道Java的大致分类。自从Sun推出Java以来,就力图使之无所不包,所以Java发展到现在,按应用来分主要分为三大块:J2SE,J2ME和J2EE,这也就是Sun ONE(Open Net Environment)体系。J2SE就是Java2的标准版,主要用于桌面应用软件的编程;J2ME主要应用于嵌入是系统开发,如手机和PDA的编程;J2EE
JSF 2.0 introduced annotation @ViewScoped; A bean annotated with this scope maintained its state as long as the user stays on the same view(reloads or navigation - no intervening views). One problem w
很多文档说Zookeeper是强一致性保证,事实不然。关于一致性模型请参考http://bit1129.iteye.com/blog/2155336
Zookeeper的数据同步协议
Zookeeper采用称为Quorum Based Protocol的数据同步协议。假如Zookeeper集群有N台Zookeeper服务器(N通常取奇数,3台能够满足数据可靠性同时
Spring Security提供了一个实现了可以缓存UserDetails的UserDetailsService实现类,CachingUserDetailsService。该类的构造接收一个用于真正加载UserDetails的UserDetailsService实现类。当需要加载UserDetails时,其首先会从缓存中获取,如果缓存中没