视频插帧—学习笔记(算法+配置+云服务+Google-Colab)
恰好碰到同学项目需要,了解了一下关于利用深度学习视频插帧的相关知识,在这里做一个简单的记录。
目录
一、方法+论文
1.DAIN (Depth-Aware Video Frame Interpolation)
2.FLAVR (Flow-Agnostic Video Representations for Fast Frame Interpolation)
3.RRIN(Video Frame Interpolation via Residue Refinement)
4. AdaCoF(Adaptive Collaboration of Flows for Video Frame Interpolation)
5.CDFI(Compression-Driven Network Design for Frame Interpolation)
6.EDSC( Multiple Video Frame Interpolation via Enhanced Deformable Separable Convolution)
7. UTI-VFI(Video Frame Interpolation without Temporal Priors)
8.CAIN(Channel Attention Is All You Need for Video Frame Interpolation)
9.RIFE v2.4 - Real Time Video Interpolation
10.EQVI(Enhanced Quadratic Video Interpolation)
11.BMBC(Bilateral Motion Estimation with Bilateral Cost Volume for Video Interpolation)
12.ABME(Asymmetric Bilateral Motion Estimation for Video Frame Interpolation)
二、环境配置篇(可能用到的网站)
2.1 Pytorch
2.2CUDA
2.3CUPY
2.4Python Packaging User Guide
2.5python拓展库
三、云服务篇
3.1阿里云
3.2AWS亚马逊云
3.3华为云(免费试用-华为云)
3.4 以上说的几朵云的GPU都是需要付费
四、google colab篇
4.1google 云盘
4.2链接
一、方法+论文
1.DAIN (Depth-Aware Video Frame Interpolation)
论文:https://arxiv.org/pdf/1904.00830.pdf

摘要
视频帧插值旨在合成原始帧之间不存在的帧。虽然最近的深卷积神经网络已经取得了重大进展,但由于大对象运动或遮挡,插值质量往往会降低。在这项工作中,我们提出了一种视频帧插值方法,该方法通过探索深度信息来明确检测遮挡。具体地说,我们开发了一个深度回流投影层来合成中间流,该中间流最好对距离较近的物体进行采样,而不是对距离较远的物体进行采样。此外,我们还学习了层次特征来从相邻像素收集上下文信息。然后,该模型基于opticalflow和局部插值核扭曲输入帧、深度贴图和上下文特征,以合成输出帧。我们的模型是紧凑的,有效的,完全可微的。定量和定性结果表明,该模型在各种数据集上均优于最新的帧插值方法。
GitHub - baowenbo/DAIN: Depth-Aware Video Frame Interpolation (CVPR 2019)
Requirements and Dependencies
- Ubuntu (We test with Ubuntu = 16.04.5 LTS)
- Python (We test with Python = 3.6.8 in Anaconda3 = 4.1.1)
- Cuda & Cudnn (We test with Cuda = 9.0 and Cudnn = 7.0)
- PyTorch (The customized depth-aware flow projection and other layers require ATen API in PyTorch = 1.0.0)
- GCC (Compiling PyTorch 1.0.0 extension files (.c/.cu) requires gcc = 4.9.1 and nvcc = 9.0 compilers)
- NVIDIA GPU (We use Titan X (Pascal) with compute = 6.1, but we support compute_50/52/60/61 devices, should you have devices with higher compute capability, please revise this)
2.FLAVR (Flow-Agnostic Video Representations for Fast Frame Interpolation)
论文:https://arxiv.org/pdf/2012.08512.pdf
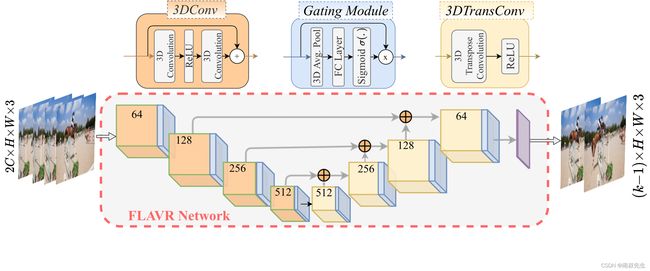
摘要
视频帧插值的大多数方法计算视频相邻帧之间的双向光流,然后使用合适的扭曲算法生成输出帧。然而,依靠光流的方法往往无法直接从视频中模拟遮挡和复杂的非线性运动,并引入不适合广泛部署的额外瓶颈。我们使用FLAVR、灵活高效的体系结构来解决这些限制,该体系结构使用3D时空卷积来实现视频帧插值的端到端学习和推理。我们的方法有效地学习了关于非线性运动、复杂遮挡和时间抽象的推理,从而提高了视频插值的性能,同时不需要以光流或深度贴图的形式进行额外的输入。由于其简单性,与当前最精确的多帧插值方法相比,FLAVR可以在不损失插值精度的情况下提供3倍更快的推理速度。此外,我们在广泛的具有挑战性的环境中评估了FLAVR,并一致证明了与各种流行基准(包括Vimeo-90K、UCF101、DAVIS、Adobe和GoPro)上的先前方法相比,该方法在定性和定量方面具有优越性。最后,我们证明了用于视频帧插值的FLAVR可以作为一个有用的自我监督借口任务,用于动作识别、光流估计和运动放大。
代码:https://github.com/tarun005/FLAVR
Requirements and Dependencies
- Ubuntu 18.04
- Python==3.7.4
- numpy==1.19.2
- PyTorch==1.5.0, torchvision==0.6.0, cudatoolkit==10.1
3.RRIN(Video Frame Interpolation via Residue Refinement)
论文:Video Frame Interpolation Via Residue Refinement | IEEE Conference Publication | IEEE Xplore

论文:Video Frame Interpolation Via Residue Refinement | IEEE Conference Publication | IEEE Xplore
摘要
视频帧插值通过在帧之间生成平滑的过渡来实现时间超分辨率。虽然深度神经网络已经取得了巨大的成功,但合成图像仍然存在视觉效果差和伪影不理想的问题。在本文中,我们提出了一种新的网络结构,利用残差细化和自适应权重在帧间进行合成。残差细化技术用于opticalflow和图像生成,以获得更高的精度和更好的视觉外观,而自适应权重贴图将前向和后向扭曲帧结合起来以减少伪影。此外,该方法中的所有子模块均采用深度较小的U-Net实现,从而保证了效率。在公共数据集上的实验证明了我们的方法的有效性和优越性。
代码:GitHub - HopLee6/RRIN: PyTorch Implementation of "Video Frame Interpolation via Residue Refinement"
Requirements and Dependencies
- Python = 3.6.8 in Anaconda3 = 4.7.5
- CUDA = 9.2 & cuDNN = 7.0
- PyTorch = 1.0
4. AdaCoF(Adaptive Collaboration of Flows for Video Frame Interpolation)
论文:https://arxiv.org/pdf/1907.10244.pdf
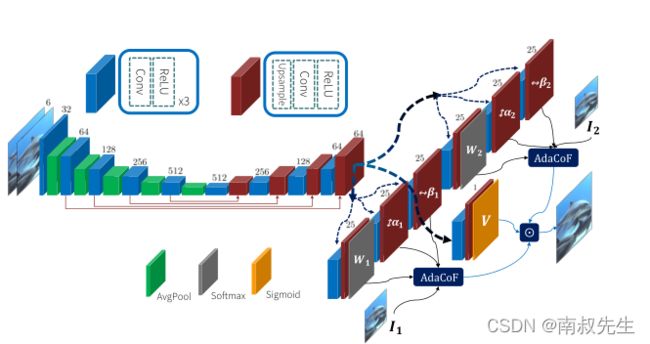
摘要
视频帧插值是视频处理研究中最具挑战性的任务之一。最近,许多基于深度学习的研究被提出。这些方法中的大多数侧重于使用有用信息查找位置,以使用各自的帧扭曲操作估计每个输出像素。然而,它们中的许多都有自由度(DoF)限制,无法处理现实世界视频中的复杂运动。为了解决这个问题,我们提出了一个新的扭曲模块AdaptiveCollaborationofFlows(AdaCoF)。我们的方法估计每个目标像素的核权重和偏移向量来合成输出帧。与其他方法相比,AdaCoF是最通用的翘曲模块之一,并将其中的大多数作为它的特例进行了介绍。因此,它可以处理相当广泛的复杂运动领域。为了进一步改进我们的框架并合成更真实的输出,我们引入了双帧对抗性丢失,它只适用于视频帧插值任务。实验结果表明,对于固定训练集环境和Middlebury基准测试,我们的方法都优于最新的方法。
代码:https://github.com/HyeongminLEE/AdaCoF-pytorch
Requirements and Dependencies
- GPU: GTX1080Ti
- Ubuntu 16.04.4
- CUDA 10.0
- python 3.6
- torch 1.2.0
- torchvision 0.4.0
- cupy 6.2.0
- scipy 1.3.1
- pillow 6.1.0
- numpy 1.17.0
5.CDFI(Compression-Driven Network Design for Frame Interpolation)
论文:https://arxiv.org/pdf/2103.10559.pdf

摘要
基于DNN的帧插值生成给定两个连续帧的中间帧,通常依赖于具有大量功能的重模型体系结构,从而防止它们部署在资源有限的系统上,例如移动设备。我们提出了一种用于帧插值的压缩驱动网络设计(CDFI),它通过稀疏引入优化来利用模型修剪,以显著减小模型大小,同时实现优异的性能。具体地说,wefirst压缩了最近提出的AdaCoF模型,并表明一个10×压缩的AdaCoF与其原始对应物的性能相似;然后,我们通过引入多分辨率扭曲模块进一步改进该压缩模型,该模块通过多层次细节增强视觉一致性。因此,与最初的AdaCoF相比,我们仅使用了四分之一的大小,就实现了显著的性能提升。此外,我们的模型在广泛的数据集上表现出与其他最新技术相比的优越性。最后,所提出的压缩驱动框架是通用的,并且可以很容易地转移到其他基于DNN的帧插值算法中。
代码:GitHub - tding1/CDFI: Code of paper "CDFI: Compression-Driven Network Design for Frame Interpolation", CVPR 2021
Requirements and Dependencies
-
CUDA 11.0
-
python 3.8.3
-
torch 1.6.0
-
torchvision 0.7.0
-
cupy 7.7.0
-
scipy 1.5.2
-
numpy 1.19.1
-
Pillow 7.2.0
-
scikit-image 0.17.2
6.EDSC( Multiple Video Frame Interpolation via Enhanced Deformable Separable Convolution)
论文:https://arxiv.org/pdf/2006.08070.pdf
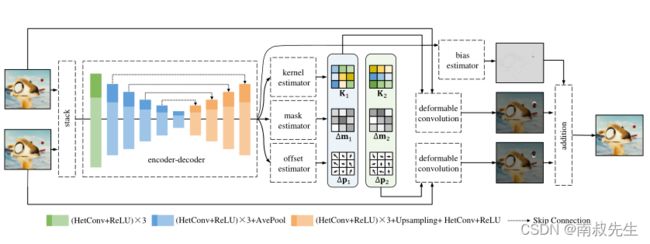
摘要
从连续视频序列生成不存在的帧一直是视频处理领域中一个有趣且具有挑战性的问题。典型的基于核的插值方法通过单个卷积过程预测像素,该卷积过程使用空间自适应局部核卷积源帧,从而避免了以光流形式进行耗时的显式运动估计。然而,当场景运动大于预定义的内核大小时,这些方法容易产生不太可信的结果。此外,它们不能直接在任意时间位置生成帧,因为学习的内核绑定到输入帧之间的时间中点。在本文中,我们试图解决这些问题,并提出了一种新的基于非流核的方法,我们称之为增强可变形可分离卷积(EDSC),不仅可以估计自适应核,还可以估计偏移量、掩码和偏差,使网络从非局部邻域获取信息。在学习过程中,通过对coord-conv技巧的扩展,可以将不同的中间时间步长作为控制变量,使估计的分量随输入时间信息的不同而变化。这使得我们的方法能够在帧之间产生多个帧。此外,我们还研究了我们的方法与其他典型的基于内核和流的方法之间的关系。实验结果表明,我们的方法在广泛的数据集上优于最新的方法。
代码:GitHub - Xianhang/EDSC-pytorch: Code for Multiple Video Frame Interpolation via Enhanced Deformable Separable Convolution
Requirements and Dependencies
python 3.7
CUDA 10.1
Pytorch 1.0.0
opencv-python 4.2.0
numpy 1.18.1
cupy 6.0.0
7. UTI-VFI(Video Frame Interpolation without Temporal Priors)
论文:https://link.zhihu.com/?target=https%3A//github.com/yjzhang96/UTI-VFI/raw/master/paper/nips_camera_ready.pdf

摘要
视频帧插值是计算机视觉中的一个重要研究课题,其目的是合成视频序列中不存在的中间帧。现有的视频帧插值方法在特定的假设条件下,如瞬间或已知的曝光时间,取得了显著的效果。然而,在复杂的现实环境中,视频的时间优先级,即每秒帧数(FPS)和帧曝光时间,可能因不同的相机传感器而异。当测试视频在不同的曝光设置下与训练视频拍摄时,插值帧将出现严重的错位问题。在这项工作中,我们解决了一般情况下的视频帧插值问题,其中输入帧可以在不确定的曝光(和间隔)时间下获得。与以往只能应用于特定时间先验的方法不同,我们从四个连续的尖锐帧或两个连续的模糊帧中推导出一个通用的曲线运动轨迹公式,而不需要时间先验。此外,利用相邻运动轨迹内的约束,我们设计了一种新的光流细化策略,以获得更好的插值结果。最后,实验表明,一个训练有素的模型就足以在复杂的现实环境下合成高质量的慢动作视频。
代码:GitHub - yjzhang96/UTI-VFI: Video Frame Interpolation without Temporal Priors (a general method for blurry video interpolation)
Requirements and Dependencies
- NVIDIA GPU + CUDA 9.0 + CuDNN 7.6.5
- Pytorch 1.1.0
8.CAIN(Channel Attention Is All You Need for Video Frame Interpolation)
论文:https://aaai.org/ojs/index.php/AAAI/article/view/6693/6547

摘要
流行的视频帧插值技术严重依赖于光流估计,需要额外的模型复杂度和计算成本;在大运动和严重遮挡的挑战场景中,它也容易受到错误传播的影响。为了缓解这一限制,我们提出了一种简单但有效的视频帧内插深度神经网络,它是端到端可训练的,并且不需要运动估计网络组件。我们的算法采用了一种特殊的特征重塑操作,称为PixelShuffle,带有通道注意,它取代了opticalflow计算模块。该设计的主要思想是将特征地图中的信息分布到多个通道中,并通过参与像素级帧合成的通道来提取运动信息。该原理给出的模型在存在挑战性运动和遮挡时是有效的。我们构建了一个综合评估基准,并证明了与现有的带有光流计算组件的模型相比,该方法取得了优异的性能。
代码:GitHub - myungsub/CAIN: Source code for AAAI 2020 paper "Channel Attention Is All You Need for Video Frame Interpolation"
Requirements and Dependencies
- Ubuntu 18.04
- Python==3.7.5
- numpy==1.17
- PyTorch==1.3.1, torchvision==0.4.2, cudatoolkit==10.1
- tensorboard==2.0.0 (If you want training logs)
- opencv==3.4.2
- tqdm==4.39.0
9.RIFE v2.4 - Real Time Video Interpolation
论文:https://arxiv.org/pdf/2011.06294.pdf
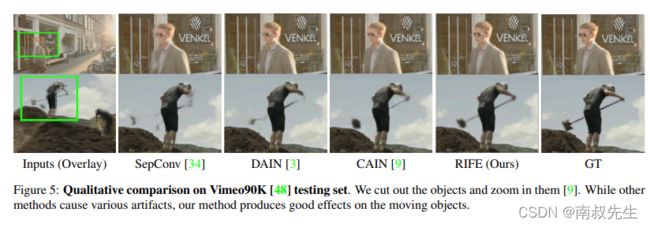
摘要
我们提出了RIFE,一种用于视频帧插值(VFI)的实时中间流估计算法。许多基于recentflow的VFI方法首先估计双向光流,然后缩放和反转它们以近似中间流,从而在运动边界和复杂管道上产生伪影。RIFE使用一个名为IFNet的神经网络,它可以以更快的速度从粗到细直接估计中间流。我们设计了一个特权蒸馏方案来训练IFNet,从而大大提高了性能。RIFE不依赖于预先训练的光流模型,可以支持带有时间编码输入的任意时间步帧插值。实验表明,RIFE在几个公共基准上实现了最先进的性能。与流行的SuperSlomo和DAIN方法相比,RIFE速度快4-27倍,效果更好。
代码:“GitHub - hzwer/arXiv2020-RIFE: RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
10.EQVI(Enhanced Quadratic Video Interpolation)
论文:https://arxiv.org/pdf/2009.04642.pdf

摘要
随着数字视频产业的蓬勃发展,视频帧插值技术引起了计算机视觉界的持续关注,并成为一股新的产业热潮。许多基于学习的方法已经被提出并取得了进步的成果。其中,最近提出的二次视频插值(QVI)算法取得了令人满意的性能。它利用高阶运动信息(例如加速度)并成功地对插值流的估计建模。然而,其生成的中间帧仍然包含一些不令人满意的重影、伪影和不准确的运动,尤其是在发生大而复杂的运动时。在这项工作中,我们从三个方面进一步改进了QVI的性能,并提出了一种增强的二次视频插值(EQVI)模型。特别是,我们采用修正的二次流预测(RQFP)公式和最小二乘法来更准确地估计运动。作为对图像像素级混合的补充,我们引入了残差上下文合成网络(RCSN)来利用高维特征空间中的上下文信息,这有助于模型处理更复杂的场景和运动模式。此外,为了进一步提高性能,我们设计了一种新的多尺度融合网络(MS-fusion),它可以看作是一个可学习的增强过程。提出的EQVI模型在AIM2020视频时间超分辨率挑战赛中获得第一名。
代码:GitHub - lyh-18/EQVI: Winning solution of AIM2020 VTSR Challenge (video interpolation). EQVI-Enhanced Quadratic Video Interpolation. Requirements and Dependencies
- Python >= 3.6
- Tested on PyTorch==1.2.0 (may work for other versions)
- Tested on Ubuntu 18.04.1 LTS
- NVIDIA GPU + CUDA
11.BMBC(Bilateral Motion Estimation with Bilateral Cost Volume for Video Interpolation)
论文:https://arxiv.org/abs/2108.06815

摘要
视频插值通过合成两个连续帧之间的中间帧来提高视频序列的时间分辨率。提出了一种基于双边运动估计的深度学习视频插值算法。首先,我们利用双边成本量建立双边运动网络,以准确估计双边运动。然后,我们近似双向运动来预测不同类型的双边运动。然后,我们使用估计的双边运动扭曲两个输入帧。接下来,我们开发动态过滤器生成网络以生成动态混合过滤器。最后,我们使用动态混合过滤器组合扭曲帧以生成中间帧。实验结果表明,在多个基准数据集上,该算法的性能优于现有的视频插值算法。
代码:GitHub - JunHeum/BMBC: BMBC: Bilateral Motion Estimation with Bilateral Cost Volume for Video Interpolation, ECCV 2020
Requirements and Dependencies
- PyTorch 1.3.1 (Other versions can cause different results)
- CUDA 10.0
- CuDNN 7.6.5
- python 3.6
12.ABME(Asymmetric Bilateral Motion Estimation for Video Frame Interpolation)
论文:https://arxiv.org/abs/2108.06815

摘要
我们提出了一种新的基于非对称双边运动估计(ABME)的视频帧插值算法,该算法在两个输入帧之间合成一个中间帧。首先,我们预测对称的双边运动场来插值锚框架。其次,我们估计从锚帧到输入帧的不对称双边运动场。第三,我们使用不对称场向后扭曲输入帧并重建中间帧。最后,为了细化中间帧,我们开发了一个新的合成网络,该网络使用局部和全局信息生成一组动态滤波器和一个剩余帧。实验结果表明,该算法在各种数据集上都取得了良好的性能。
代码:https://github.com/JunHeum/ABME
Requirements and Dependencies
- PyTorch 1.7
- CUDA 11.0
- CuDNN 8.0.5
- python 3.8
二、环境配置篇(可能用到的网站)
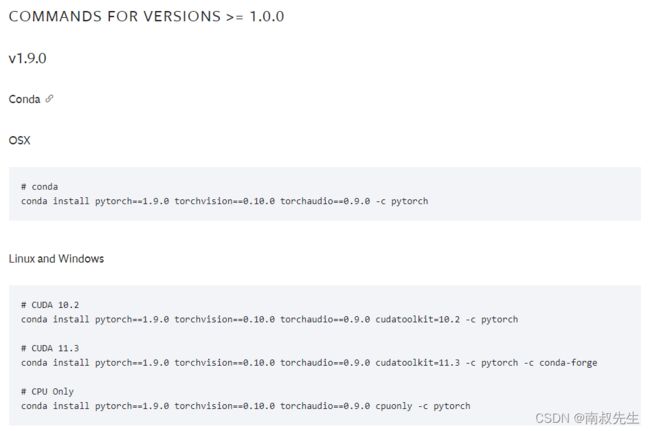
2.1 Pytorch
新版本:Start Locally | PyTorch

旧版本:Previous PyTorch Versions | PyTorch
2.2CUDA
CUDA Toolkit Archive | NVIDIA Developer

2.3CUPY
CuPy – NumPy & SciPy for GPU — CuPy 10.0.0 documentation

2.4Python Packaging User Guide
2.5python拓展库
https://www.lfd.uci.edu/~gohlke/pythonlibs/

三、云服务篇
基于算法对于GPU的高性能要求,一般的电脑即便是一切都配置完成了,最后在跑程序的时候还是没法进行下去,可能出现两个问题:
1.broken pipe
2.cuda out of memory
![]()
网上的解决办法是更改batch size,但是在我的电脑中即便是更改为1,也是无法解决的,应该是显存不够。所以,云服务器就被考虑进来了。
3.1阿里云
在阿里云的首页产品上,可以申请各种服务器。
下面的介绍主要是CPU版本的,作为记录,与主题无关。
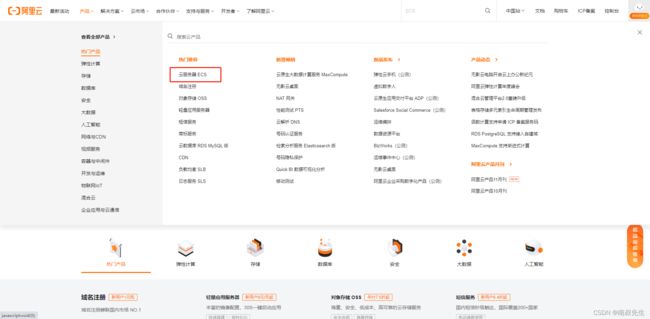
在这个网站下,阿里云提供了一个一个月免费试用项目。阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台

申请完毕后可以进入,EOC控制台。点击远程控制,就可以进入自己的服务器了。
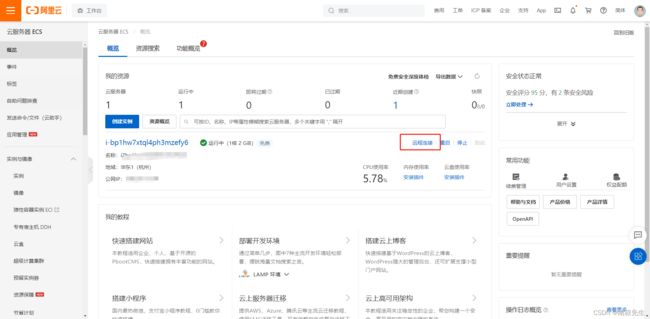
第一次登录可能需要设置密码,所以,先设置一下密码

点击重置示例密码。

完成之后,点击远程连接,立即登录。

然后就进来了,输入密码就可以了。


下面看一下阿里云的GPU服务器阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
价格比较昂贵。

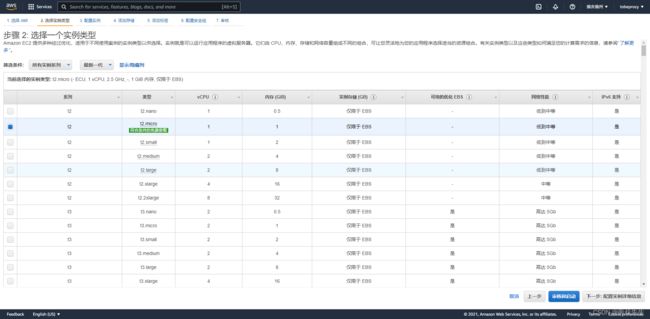
3.2AWS亚马逊云
aws云也有类似的免费服务,就不具体介绍了。https://us-east-2.console.aws.amazon.com/console/home?region=us-east-2


3.3华为云(免费试用-华为云)
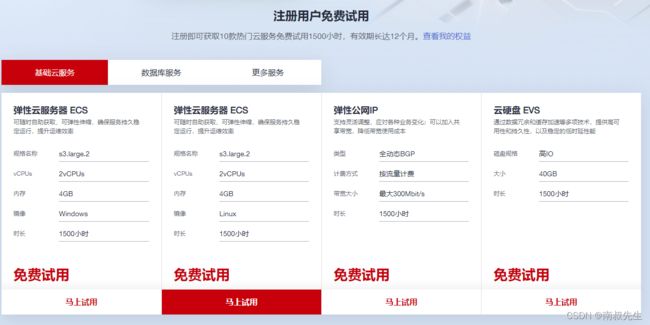
3.4 以上说的几朵云的GPU都是需要付费
四、google colab篇
在tensorflow的工具里有一个,colab,它是一个免费的具有GPU服务器,凑合着用。
https://www.tensorflow.org/resources/tools

具体的使用教程如下
https://colab.research.google.com/notebooks/basic_features_overview.ipynb
4.1google 云盘
也可以通过google云盘来使用colab
https://drive.google.com/drive/my-drive

创建 之后就可以自由使用了
为了和电脑进行文件交互,可以下一个客户端,安装完成后,就相当于电脑的一个盘。

4.2链接
使用google的前提是,要建立梯子。做一个守法公民,这里不做具体介绍,不过仅仅作为学术需要,可以使用的。(V2ray)