深度学习:图像去雨网络实现Pytorch (二)一个简单实用的基准模型(PreNet)实现
本文参考文献:Progressive Image Deraining Networks: A Better and Simpler Baseline Dongwei Ren1, Wangmeng Zuo2, Qinghua Hu∗1, Pengfei Zhu1, and Deyu Meng31College of Computing and Intelligence, Tianjin University, Tianjin, China 2School of Computer Science and Technology, Harbin Institute of Technology, Harbin, China 3Xi’an Jiaotong University, Xi’an, China
论文下载网址:[1901.09221] Progressive Image Deraining Networks: A Better and Simpler Baseline (arxiv.org) https://arxiv.org/abs/1901.09221
https://arxiv.org/abs/1901.09221
论文作者提供的Github实验源码:https://github.com/csdwren/PReNet.
关于论文:本文参考论文的主要贡献是提出了一种简单易实现且有较好效果的去雨网络架构PreNet,虽然其所用技术不是最先进的,但却有着十分优秀的去雨效果,因此作者认为这是一种可供众多研究者学习和实验对比使用的优良的基准模型。而在我看来,正是由于模型的以上这些特点,PreNet也十分适合深度学习去雨入门研究者进行学习和实现。
接下来将仔细说明一种十分简便的实现方法以及部分实验原理。
实验环境
首先介绍实现的实验环境。新手建议首选在以下网址注册账号(注册需科学上网,后续使用不必)利用线上环境写Pytorch代码,并将模型放网站提供的免费云算力服务器上训练。可以省去新手配置本地cuda环境的烦恼。
Kaggle: Your Home for Data Sciencehttps://www.kaggle.com/

点击左侧 Code
再点击 New Notebook 即可开启线上编程环境

线上编程环境和Jupyter类似,进入编程界面后可以在上方菜单栏设置界面外观选项(可以选择添加行号以便于查看代码)。右侧可选择加速器,我推荐使用GPU P100。

代码编写及调试完成后点击右上角 Save Version 来讲模型放在云GPU上训练(注意保存的版本无法手动删除,因此一定要确认代码调试无误后再点击 Save Version,以免版本太多造成的混乱)。
以上即是对编程环境的基本介绍,下面详细介绍实现步骤。
具体实现
图像去雨任务和图像分类任务的处理流程相似,都是:数据处理 --> 模型构建 --> 训练 --> 记录训练信息及模型保存。接下来将结合代码详细介绍。
数据处理:
'''
Dataset for Training.
'''
class MyTrainDataset(Dataset):
def __init__(self, input_path, label_path):
self.input_path = input_path
self.input_files = os.listdir(input_path)
self.label_path = label_path
self.label_files = os.listdir(label_path)
self.transforms = transforms.Compose([
transforms.CenterCrop([64, 64]),
transforms.ToTensor(),
])
def __len__(self):
return len(self.input_files)
def __getitem__(self, index):
label_image_path = os.path.join(self.label_path, self.label_files[index])
label_image = Image.open(label_image_path).convert('RGB')
'''
Ensure input and label are in couple.
'''
temp = self.label_files[index][:-4]
self.input_files[index] = temp + 'x2.png'
input_image_path = os.path.join(self.input_path, self.input_files[index])
input_image = Image.open(input_image_path).convert('RGB')
input = self.transforms(input_image)
label = self.transforms(label_image)
return input, label
'''
Dataset for testing.
'''
class MyValidDataset(Dataset):
def __init__(self, input_path, label_path):
self.input_path = input_path
self.input_files = os.listdir(input_path)
self.label_path = label_path
self.label_files = os.listdir(label_path)
self.transforms = transforms.Compose([
transforms.CenterCrop([64, 64]),
transforms.ToTensor(),
])
def __len__(self):
return len(self.input_files)
def __getitem__(self, index):
label_image_path = os.path.join(self.label_path, self.label_files[index])
label_image = Image.open(label_image_path).convert('RGB')
temp = self.label_files[index][:-4]
self.input_files[index] = temp + 'x2.png'
input_image_path = os.path.join(self.input_path, self.input_files[index])
input_image = Image.open(input_image_path).convert('RGB')
input = self.transforms(input_image)
label = self.transforms(label_image)
return input, label上面的代码分为两个部分:分别是训练集和测试集的Dataset类的重写。这是自定义Pytorch数据集处理方式的比较方便的处理方式。由于训练集和测试集的处理方式一致,这里仅对训练集的处理方式进行介绍。
首先我们需要明白,为什么我们特别地需要重写__init__, __length__, __getitem__ 这三个Dataset()类的方法,因为后续处理中封装用的DataLoader类需要调用Dataset对象的这三个函数来获取数据集的相关信息,这个关系可以理解为:DataLoader类负责将数据切分为很多个批次(batch)以分批次进行训练,而Dataset负责记录数据整体信息处理每一批次中的每一对标签和输入数据的内容。换句话说,Dataset类只负责记录整体数据信息处理一对标签和输入数据对,而DataLoader将Dataset的处理方式循环地应用到整个数据集上。因此,对于不同的数据集我们要重写Dataset类的这三个函数以改变DataLoader处理数据的方式。
明白了以上内容,我们就好理解这三个函数的运作方式了:__init__和 __length__负责记录数据集的一些基本信息,__length__的内容一定是返回输入数据项的长度(不可更改),而__init__用于初始化你需要用到的一些基本变量(可高度自定义),这些变量将在__getitem__中被调用。__getitem__就负责处理每一对数据对的匹配输出,其关键是一定要保证最后 return 的 input 和 label 是成对的。
以下是创建Dataset和DataLoader对象的过程:
'''
Path of Dataset.
'''
input_path = "../input/jrdr-deraining-dataset/JRDR/rain_data_train_Heavy/rain/X2"
label_path = "../input/jrdr-deraining-dataset/JRDR/rain_data_train_Heavy/norain"
valid_input_path = '../input/jrdr-deraining-dataset/JRDR/rain_data_test_Heavy/rain/X2'
valid_label_path = '../input/jrdr-deraining-dataset/JRDR/rain_data_test_Heavy/norain'
'''
Prepare DataLoaders.
Attension:
'pin_numbers=True' can accelorate CUDA computing.
'''
dataset_train = MyTrainDataset(input_path, label_path)
dataset_valid = MyValidDataset(valid_input_path, valid_label_path)
train_loader = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, pin_memory=True)
valid_loader = DataLoader(dataset_valid, batch_size=batch_size, shuffle=True, pin_memory=True)
需要注意的是我使用的是Kaggle网站上提供的线上数据集,可自行搜索添加:

你可以选择使用Heavy数据集训练,也可以使用Light,分别对应人工合成的大雨和小雨数据集。我推荐使用Heavy,使用Heavy训练出来的模型对于真实下雨场景的去雨效果更明显。
模型构建:
# 网络架构
class PReNet_r(nn.Module):
def __init__(self, recurrent_iter=6, use_GPU=True):
super(PReNet_r, self).__init__()
self.iteration = recurrent_iter
self.use_GPU = use_GPU
self.conv0 = nn.Sequential(
nn.Conv2d(6, 32, 3, 1, 1),
nn.ReLU()
)
self.res_conv1 = nn.Sequential(
nn.Conv2d(32, 32, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.ReLU()
)
self.conv_i = nn.Sequential(
nn.Conv2d(32 + 32, 32, 3, 1, 1),
nn.Sigmoid()
)
self.conv_f = nn.Sequential(
nn.Conv2d(32 + 32, 32, 3, 1, 1),
nn.Sigmoid()
)
self.conv_g = nn.Sequential(
nn.Conv2d(32 + 32, 32, 3, 1, 1),
nn.Tanh()
)
self.conv_o = nn.Sequential(
nn.Conv2d(32 + 32, 32, 3, 1, 1),
nn.Sigmoid()
)
self.conv = nn.Sequential(
nn.Conv2d(32, 3, 3, 1, 1),
)
def forward(self, input):
batch_size, row, col = input.size(0), input.size(2), input.size(3)
#mask = Variable(torch.ones(batch_size, 3, row, col)).cuda()
x = input
h = Variable(torch.zeros(batch_size, 32, row, col))
c = Variable(torch.zeros(batch_size, 32, row, col))
if self.use_GPU:
h = h.cuda()
c = c.cuda()
x_list = []
for i in range(self.iteration):
x = torch.cat((input, x), 1)
x = self.conv0(x)
x = torch.cat((x, h), 1)
i = self.conv_i(x)
f = self.conv_f(x)
g = self.conv_g(x)
o = self.conv_o(x)
c = f * c + i * g
h = o * torch.tanh(c)
x = h
for j in range(5):
resx = x
x = F.relu(self.res_conv1(x) + resx)
x = self.conv(x)
x = input + x
x_list.append(x)
return x, x_list我直接照搬的论文源码的网络架构,简单来说,该网络就是结合了LSTM和递归残差网络的处理方式。你暂时可以不用理解,直接用就行。如果想要进行深入了解的话可以查看本文开头处提供的原文链接或本站搜索论文翻译。
训练:
'''
Define optimizer and Loss Function.
'''
optimizer = optim.RAdam(net.parameters(), lr=learning_rate)
scheduler = CosineAnnealingLR(optimizer, T_max=epoch)
loss_f = SSIM()首先初始化优化器和损失函数,采用RAdam优化器(Adam优化器的基础上增加了warm-up的功能)并使用CosineAnnealingLR(余弦退火算法)让学习率随训练轮数呈余弦变化,以优化训练结果。
SSIM损失函数使用的是论文作者提供的源码:
# SSIM损失函数实现
def gaussian(window_size, sigma):
gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
return gauss/gauss.sum()
def create_window(window_size, channel):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
return window
def _ssim(img1, img2, window, window_size, channel, size_average = True):
mu1 = F.conv2d(img1, window, padding = window_size//2, groups = channel)
mu2 = F.conv2d(img2, window, padding = window_size//2, groups = channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1*mu2
sigma1_sq = F.conv2d(img1*img1, window, padding = window_size//2, groups = channel) - mu1_sq
sigma2_sq = F.conv2d(img2*img2, window, padding = window_size//2, groups = channel) - mu2_sq
sigma12 = F.conv2d(img1*img2, window, padding = window_size//2, groups = channel) - mu1_mu2
C1 = 0.01**2
C2 = 0.03**2
ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1).mean(1).mean(1)
class SSIM(torch.nn.Module):
def __init__(self, window_size = 11, size_average = True):
super(SSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.channel = 1
self.window = create_window(window_size, self.channel)
def forward(self, img1, img2):
(_, channel, _, _) = img1.size()
if channel == self.channel and self.window.data.type() == img1.data.type():
window = self.window
else:
window = create_window(self.window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
self.window = window
self.channel = channel
return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
def ssim(img1, img2, window_size = 11, size_average = True):
(_, channel, _, _) = img1.size()
window = create_window(window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
return _ssim(img1, img2, window, window_size, channel, size_average)SSIM是一种评估两幅图像相似度的算法,具体原理此处不再详述,你只需要记住其值越大两张图像相似度越高,值为一则两张图象完全一样。因此我们在后续训练时需要取SSIM的负值。
下面是循环训练的代码:
'''
START Training ...
'''
for i in range(epoch):
# ---------------Train----------------
net.train()
train_losses = []
'''
tqdm is a toolkit for progress bar.
'''
for batch in tqdm(train_loader):
inputs, labels = batch
outputs, _ = net(inputs.to(device))
loss = loss_f(labels.to(device), outputs)
loss = -loss
optimizer.zero_grad()
loss.backward()
'''
Avoid grad to be too BIG.
'''
grad_norm = nn.utils.clip_grad_norm_(net.parameters(), max_norm=10)
optimizer.step()
'''
Attension:
We need set 'loss.item()' to turn Tensor into Numpy, or plt will not work.
'''
train_losses.append(loss.item())
train_loss = sum(train_losses) / len(train_losses)
Loss_list.append(train_loss)
print(f"[ Train | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {train_loss:.5f}")
scheduler.step()
for param_group in optimizer.param_groups:
learning_rate_list.append(param_group["lr"])
print('learning rate %f' % param_group["lr"])
# -------------Validation-------------
'''
Validation is a step to ensure training process is working.
You can also exploit Validation to see if your net work is overfitting.
Firstly, you should set model.eval(), to ensure parameters not training.
'''
net.eval()
valid_losses = []
for batch in tqdm(valid_loader):
inputs, labels = batch
'''
Cancel gradient decent.
'''
with torch.no_grad():
outputs, _ = net(inputs.to(device))
loss = loss_f(labels.to(device), outputs)
loss = -loss
valid_losses.append(loss.item())
valid_loss = sum(valid_losses) / len(valid_losses)
Valid_Loss_list.append(valid_loss)
print(f"[ Valid | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {valid_loss:.5f}")
break_point = i + 1
'''
Update Logs and save the best model.
Patience is also checked.
'''
if valid_loss < best_valid_loss:
print(
f"[ Valid | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {valid_loss:.5f} -> best")
else:
print(
f"[ Valid | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {valid_loss:.5f}")
if valid_loss < best_valid_loss:
print(f'Best model found at epoch {i+1}, saving model')
torch.save(net.state_dict(), f'model_best.ckpt')
best_valid_loss = valid_loss
stale = 0
else:
stale += 1
if stale > patience:
print(f'No improvement {patience} consecutive epochs, early stopping.')
break见注释即可。其中break_point用于记录训练结束的epoch值,stale用于记录模型未进步所持续的训练轮数,patience是预设的模型未进步所持续轮数的最大值。
记录训练信息及模型保存:
部分内容是从上面的代码段截取的,由于实例较分散,我只在下面说明了其中比较典型的几个:
Loss_list.append(train_loss) # 用于后续绘制Loss曲线
print(f"[ Train | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {train_loss:.5f}")
打印日志信息
print(f'Best model found at epoch {i+1}, saving model')
torch.save(net.state_dict(), f'model_best.ckpt')保存模型(关于所保存文件的后缀.ckpt 和 .pth的区别此处不详述,可自行搜索)
'''
Use plt to draw Loss curves.
'''
plt.figure(dpi=500)
plt.subplot(211)
x = range(break_point)
y = Loss_list
plt.plot(x, y, 'ro-', label='Train Loss')
plt.plot(range(break_point), Valid_Loss_list, 'bs-', label='Valid Loss')
plt.ylabel('Loss')
plt.xlabel('epochs')
plt.subplot(212)
plt.plot(x, learning_rate_list, 'ro-', label='Learning rate')
plt.ylabel('Learning rate')
plt.xlabel('epochs')
plt.legend()
plt.show()利用matplotlib库绘制训练过程中重要参数变化曲线。
实验结果:
先附上我的完整代码链接(注意前面提供的代码不完整,一些细节部分被我省略了,直接复制粘贴无法运行):
Kaggle平台:PreNet | Kagglehttps://www.kaggle.com/code/leeding123/prenet Gihub仓库(欢迎点星):Derain_platform/prenet.ipynb at f3249f6ee4f14055bf30c53239141bccecdcb0f2 · DLee0102/Derain_platform · GitHubContribute to DLee0102/Derain_platform development by creating an account on GitHub. https://github.com/DLee0102/Derain_platform/blob/f3249f6ee4f14055bf30c53239141bccecdcb0f2/prenet.ipynb 我在Heavy训练集上的训练结果:
https://github.com/DLee0102/Derain_platform/blob/f3249f6ee4f14055bf30c53239141bccecdcb0f2/prenet.ipynb 我在Heavy训练集上的训练结果:

注:Loss曲线图中红色为训练集Loss蓝色为测试集Loss
合成数据集上的去雨效果:
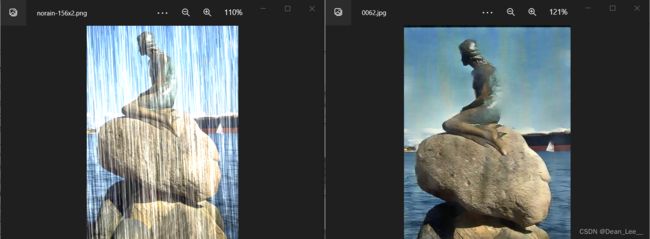
真实数据集上的去雨效果: