webshell检测方式深度剖析---语法语义检测(下)
开篇
这一篇我们从代码角度,分析RIPS的架构设计和核心代码部分,从源码入手,深入分析其核心检测原理。前面关于语法语义检测的两讲已经讨论了很多概念,比如污染型漏洞以及静态代码分析的框架组成,也分析了rips在框架各个部分的实现,不过这些讨论还是停留在文字层面。该篇我们就把rips的源代码作为解剖对象,看看其核心检测部分到底是怎么实现的,在实现部分有没有创新和可以借鉴的地方,毕竟理论框架都是统一的,而具体实现却可以千变万化。
好了,废话不多说,“Don‘t talk,show me the code!”,让我们开始吧。
类图
描述一个项目的代码结构,类图是最适合的工具了。下面给出的就是RIPS中描述各个类功能和关系的类图了。

后面我们将按照依赖关系来依次讲解这些类的功能,因为scanner类是核心检测分析类,所以我们放到最后来讲解。
Tokenizer类
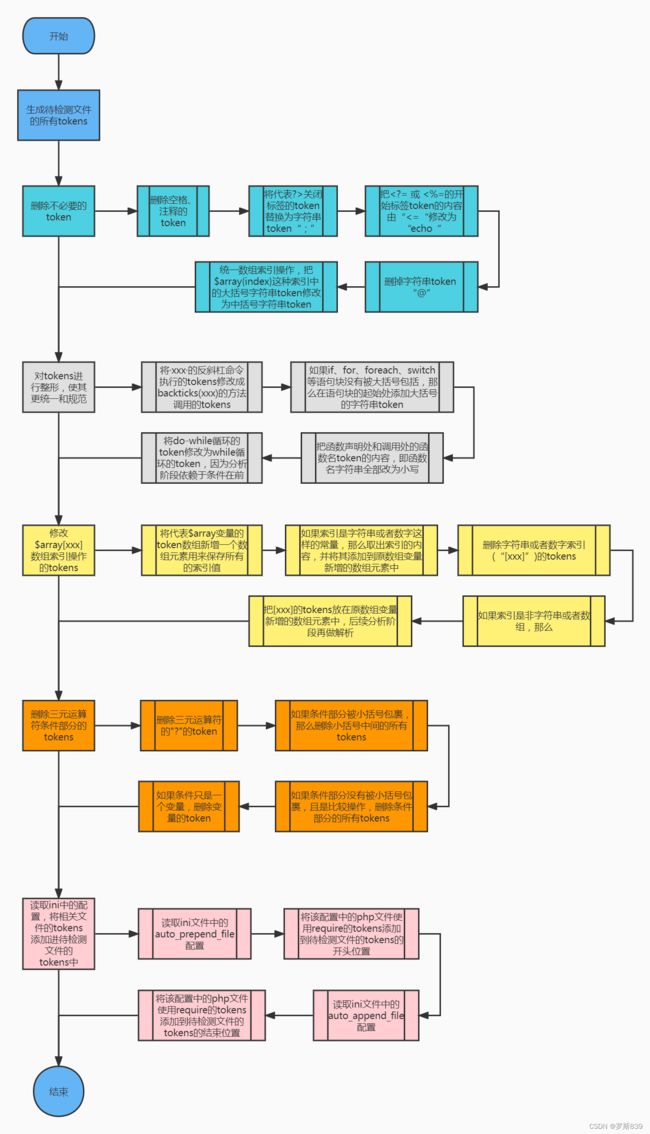
该类用于将给定的源文件生成tokens序列,并对该序列做一些重构预处理,目的是删除对分析没有作用的toknes,以及将不同语法统一成同一种写法,方便后续分析。
因为后续的所有分析都是基于该tokens序列的,所以必须尽量对tokens做简化处理,否则在实际分析时要考虑同一语法的不同写法,增加了分析的难度。对tokens的整形涵盖了很多操作,具体可以参加下面的流程图,可以看到整个整形过程涵盖了很多细节操作。
VarDeclare类
该类用于代码中出现的变量,当出现变量赋值或者其他能生成新的变量的操作时,比如extract函数调用,每个新生成的变量都会生成一个该类的实例对象,并将其添加到scanner类中记录的本地或全局变量列表中。
需要注意的是,属性tokens记录的是变量赋值"a = xxx;"的整个token序列,如果是foreach中的key和value的话,这个tokens就是foreach条件部分的整个token。
在分析过程中,我们需要判断一个变量是否被外部输入污染或者是否被安全函数净化,要根据变量生成部分的tokens去进行递归回溯,回溯针对的是这部分tokens中所有出现的变量,只要有一个变量被污染即可以认为当前变量也被污染。
属性tokenscanstart和tokenscanstop用于标记属性tokens中与当前变量有关的tokens范围,比如foreach中对key和value来讲,只有最开始的可迭代对象对它们有关联,而这两个属性就可以框定回溯的范围,减少不必要的回溯和误报。
FunctionDeclare类
如果当前对源文件的tokens遍历是在一个函数或方法声明中,那么就会建立一个FunctionDeclare类的实例对象来临时记录该函数的一些信息,当token遍历到该函数外部后,该变量会自动销毁。该类记录的信息并不多,仅仅包括函数名,函数的参数名数组等等几项,比较简单。
Analyzer类
Analyzer是一个工具类,提供了一些重要的功能方法供检测分析时使用,其中有两个方法值得重点说一下。
get_tokens_value方法
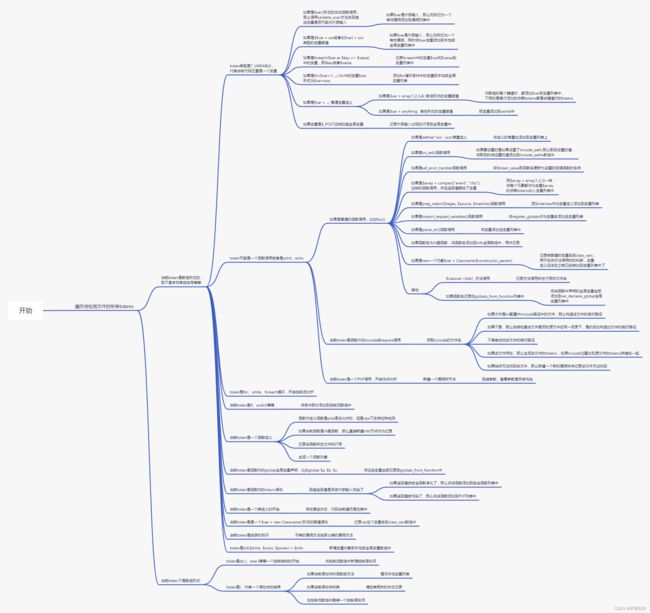
该方法应该是Rips中第三重要的方法了(前两个在scanner类中),其用于对一个表达式进行动态估值。
有时我们需要知道一个表达式的值才能做更精细的分析,比如"a = 1 + 1",这样一条赋值语句,如果想知道变量a的具体值是多少,必须对生成变量a的“1 + 1”的这部分表达式进行计算。但因为Rips是静态代码分析,不可能真的去执行这部分代码,所以才构建了这样一个表达式动态估值的方法。
该方法返回的始终是一个字符串,与真正的执行时表达式求值不同,该方法进行的估值是一系列的字符串拼接,其中的关键是如果在求值过程中发现某个变量与外部输入有关,那么会将最终结果与"USERINPUT"做拼接,这样就可以通过对一段tokens调用get_tokens_value方法来得知这段tokens是否被污染了。
具体的估值步骤可以参加下方的流程图:

get_var_value方法
该方法用于获取一个变量的值,最终获取到的值是一个字符串,方法内部会调用get_tokens_value估值方法对生成变量的tokens部分进行估值,然后将该值作为变量的值返回。
那怎么根据变量名字得知该生成该变量的那部分tokens呢,其实在scanner类中记录着本地变量和全局变量列表,这两个列表中保存的即是变量名和VarDeclare对象的对应关系,而VarDeclare对象中即保存着该变量的生成tokens,因此也就可以对这部分tokens调用估值方法来获取估值结果了。
VulnBlock类
该类代表发现的一个漏洞,最终记录到“文件名->VulnBlock实例对象数组”的一个映射表中,作为最终给用户的检测结果输出到页面。
VulnBlock对象中记录的是一个代码位置可能存在的多个漏洞,其中一个代码位置只会产生一个VulnBlock对象,多个漏洞通过VulnTreeNode实例对象来表示。
VulnTreeNode类
VulnTreeNode对象代表一个完整的漏洞,其上记录的信息可以完整的描述一个漏洞:
- $dependencies:描述该漏洞的PVF所在的控制流;
- $children:该漏洞参数部分在回溯过程中被标记为外部输入的变量定义对象;
在输出漏洞信息到用户页面时,可以遍历该类型的对象,将对象中记录的信息加工和反编译后返回给用户。
scanner类
该类是检测核心类,其会遍历检测文件的所有tokens,遍历过程中记录代码静态信息,并在几个关键token处进行分析,最终记录分析结果。其中每一个待检测文件都会生成一个scanner对象来进行检测。
scanner类中有两个方法特别关键,我们分别来看一下。
scan_parameter方法
该方法会递归地追踪变量,最终返回该变量是否被外部输入污染,同时如果该变量被外部输入污染,将该变量的变量定义对象作为child添加到VulnTreeNode对象中。该方法用于当发现一个PVF函数后,对其参数部分进行回溯,或者回溯一个函数的返回值,并在回溯过程中,把它们作为子节点添加到VulnTreeNode上。

parse方法
该方法是检测分析的主方法,用来遍历tokens,构建检测模型,并进行控制流和污点分析。整个parse方法的逻辑细节非常之多,但可以总体概括为在遇到某个类型的token时进行对应的处理。
总结
至此,我们对RIPS的分析就告一段落了,在这个分析过程中我们可以窥见静态代码分析的常用技术,比如控制流分析、过程内和过程间分析等等。也能看到静态代码分析的局限,比如对表达式的求值只能进行估计,不能准确求值的问题。而且RIPS没有进行数据流分析,会导致一定的误报存在。
接下来,我们会分析一个在静态代码分析领域做得更完整的一个开源项目,Pixy。从它身上,我们会将静态代码分析的能力发掘的更彻底。