Chapter4 Pytorch数据处理与可视化(Dataset、DataLoader、tensorboard、torchvision)
目录
- 1、数据处理工具箱概述
- 2、`Dataset`和`DataLoader`
-
- 2.1、`Dataset`
- 2.2、`DataLoader`
- 3、`tensorboard`/`tensorboardX`
-
- 3.1、`tensorboard`简介
- 3.2、可视化神经网络
- 3.3、可视化损失值
- 3.4、可视化图像
- 4、`torchvision`
-
- 4.1、`transforms`
- 4.2、`datasets`
- 4.3、`models`
数据下载和预处理是机器学习、深度学习实际项目中耗时又重要得任务,尤其是数据预处理,关系到数据质量和模型性能,往往要占据项目的大部分时间。
Pytorch为此提供了专门的数据下载、数据处理包。使用这些包,可以大大提高我们的开发效率和数据质量。本文主要介绍一下几个方面。
- Pytorch相关的数据处理工具箱
utils.data下的Dataset和DataLoadertorchvisiontensorboard
1、数据处理工具箱概述
PyTorch涉及数据处理(数据加载、数据预处理、数据增强等)。主要工具包及相互关系图下图所示。
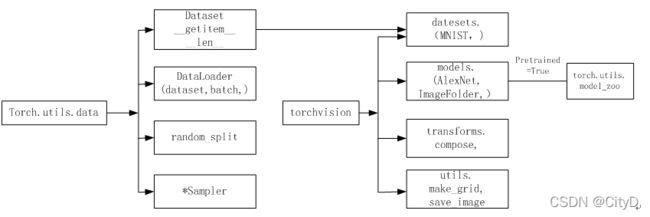
图左边为torch.utils.data工具包,以下是其中常用的几个类。
DataSet:是一个抽象类,其他数据集需要继承这个类,并且覆写其中的两个方法(__getitem__,__len__)。DataLoader:定义一个新的迭代器,实现批量(batch)读取,打乱(shuffle)数据并提供并行加速等功能。random_split:把数据集随机拆分为给定长度的非重叠的新数据集。Sampler:多种采样函数。TensorDataset:可以用来对 tensor 进行打包,就好像 python 中的 zip 功能。该类通过每一个 tensor 的第一个维度进行索引。因此,该类中的 tensor 第一维度必须相等。
图中间是Pytorch可视化处理工具torchvision,是Pytorch的一个视觉处理工具包。其中常用的类有以下四个。
datasets:提供常用的数据集加载,设计上继承自torch.utils.data.Dataset,主要包括MNIST,CIFAR-10/100,ImageNet,COCO等。models:提供深度学习中各种经典的网络结构以及训练好的模型(如果选择pretrained=True),包括AlexNet,VGG系列,ResNet系列,Inception系列等。transforms:常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。utils:其中常用的两个函数为make_grid函数和save_img函数。make_grid函数能将多张图片拼接在一个网格中,save_img能将Tensor保存成图片。
2、Dataset和DataLoader
Dataset和DataLoader是utils.data里常用的两个类。torch.utils.data.Dataset为抽象类,自定义数据集需要继承这个类,并实现两个函数,一个是__len__(),另一个是__getitem__()。子类也可以选择性地覆盖__len__(),许多采样器的实现和DataLoader的默认选项都期望它能返回数据集的大小。所有的子类应该覆盖__getitem__(),支持为一个给定的键取一个数据样本。
torch.utils.data.DataLoader是数据加载器。结合一个数据集和一个采样器,并在给定的数据集上提供一个可迭代的数据。DataLoader支持map风格和可迭代风格的数据集,具有单进程或多进程加载,自定义加载顺序和可选的batch大小以及其他的一些操作。
2.1、Dataset
下面通过定义一个简单的数据集,简单的介绍Dataset的使用。
- 导入需要的模块
import torch
from torch.utils import data
import numpy as np
- 定义获取数据集的类。
该类继承基类Dataset,自定义一个数据集及对应标签。
class TestDataset(data.Dataset):
def __init__(self):
#定义生成数据集的数据
self.Data=np.asarray([[1,2],[3,4],[2,1],[3,4],[4,5]])#由二维向量组成的向量集
self.Label=np.asarray([0,1,0,1,2])
#根据下标返回数据(txt和label)
def __getitem__(self,index):
#将`numpy`转为`Tensor`
txt=torch.from_numpy(self.Data[index])
label=torch.tensor(self.Label[index])
return txt,label
#返回数据集长度
def __len__(self):
return len(self.Data)
- 获取数据集中的数据
Test=TestDataset()
#获取数据集中的第三个数据,相当于调用__getitem__(2)
print(Test[2])
#获取数据集的长度
print(Test.__len__())
(tensor([2, 1], dtype=torch.int32), tensor(0, dtype=torch.int32))
5
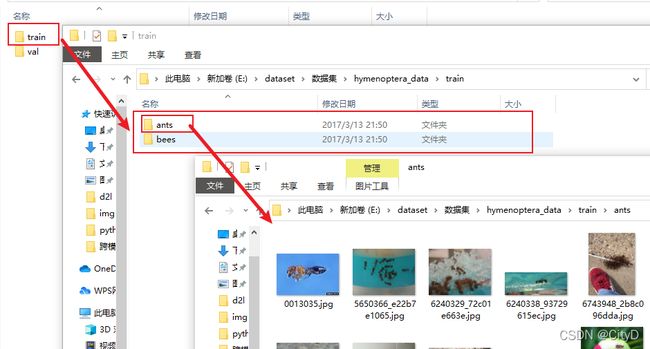
下面介绍一个稍微复杂一点的数据集是如何进行处理的。该数据集是蚂蚁和蜜蜂的二分类的数据集,有训练集和验证集两部分,标签名为文件夹的名字,对应标签的的图片全部为相对应的图片,例如,ants文件夹下的图片全部都是蚂蚁数据集。数据集的组成如下图所示,下面就为改数据创建数据集,即通过下标就可以获得相应的图片及其对应的标签名。
其处理的相应的代码为:
from torch.utils.data import Dataset
from PIL import Image
import os
%matplotlib inline
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
#将文件名进行合并
self.path=os.path.join(self.root_dir,self.label_dir)
#获得所有图片文件名称列表
self.img_path=os.listdir(self.path)
def __getitem__(self, index):
#获取指定下标的文件名称
img_name=self.img_path[index]
#获取指定文件的地址
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
#获取图片文件
img = Image.open(img_item_path)
#标签信息
label=self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir="hymenoptera_data/train"
ants_labels_dir="ants"
bees_labels_dir="bees"
#实例化蚂蚁数据集
ants_dataset=MyData(root_dir,ants_labels_dir)
#实例化蜜蜂数据集
bees_dataset=MyData(root_dir,bees_labels_dir)
#获取蚂蚁数据集和蜜蜂数据集的长度
len(ants_dataset),len(bees_dataset)
(124, 121)
2.2、DataLoader
Dataset只负责数据的抽取,调用一次__getitem__()只返回一个样本。如果希望批处理,还要同时进行shuffle和并行加速等操作,就需要使用DataLoader。官方给出的DataLoader的格式为:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,
num_workers=0, collate_fn=None, pin_memory=False, drop_last=False,
timeout=0, worker_init_fn=None, multiprocessing_context=None,
generator=None, *, prefetch_factor=2, persistent_workers=False)
下面对主要的参数的进行说明:
datatset:加载的数据集。batch_size:批大小。shuffle:是否将数据打乱,一般训练集的时候需要打乱,而测试集的时候则不需要进行打乱。sampler:样本抽样。num_workers:使用多进程加载的进程数,0代表不使用多进程。collate_fn:如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式就可以。pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一点。drop_last:dataset中的数据的个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃。
下面将使用前面定义的简单的Dataset数据集Test,来展示DataLoader的使用。
from torch.utils import data
#batch_size大小为2,shuffle为False则不将数据打乱,num_workers为0则进程数为0
test_loader=data.DataLoader(Test,batch_size=2,shuffle=False,num_workers=0)
#读取`DataLoader`中的数据
for i,traindata in enumerate(test_loader):
print('i:',i)
Data,Label=traindata
print('data:',Data)
print('Label',Label)
i: 0
data: tensor([[1, 2],
[3, 4]], dtype=torch.int32)
Label tensor([0, 1], dtype=torch.int32)
i: 1
data: tensor([[2, 1],
[3, 4]], dtype=torch.int32)
Label tensor([0, 1], dtype=torch.int32)
i: 2
data: tensor([[4, 5]], dtype=torch.int32)
Label tensor([2], dtype=torch.int32)
还可以使用iter命令将其转换成迭代器,使用迭代的方式对其进行读取
dataiter=iter(test_loader)
for img,label in dataiter:
print(img,label)
tensor([[1, 2],
[3, 4]], dtype=torch.int32) tensor([0, 1], dtype=torch.int32)
tensor([[2, 1],
[3, 4]], dtype=torch.int32) tensor([0, 1], dtype=torch.int32)
tensor([[4, 5]], dtype=torch.int32) tensor([2], dtype=torch.int32)
3、tensorboard/tensorboardX
Tensorboard是Tensorflow的可视化工具,它可以记录训练数据、评估数据、网络结构、图像等,并且可以在web上展示,对于观察神经网络的训练过程非常有帮助。Pytorch可以采用tensorboard_logger、visdom等可视化工具,但这些方法比较复杂或不够友好。为了解决这一问题,推出了可用于Pytorch可视化的新的更强大的工具——tensorboardX。
Pytorch原本没有像tensorboard这样的可视化工具,为了弥补这一不足,就借鸡生蛋,直接将tensorflow的tensorboard拿过来使用,tensorboardx就是这样来的。换句话说,tensorboardx和tensorflow中的tensorboard是同一个东西,只是让tensorboard能在pytorch上运行。
早期没有tensorboardx时,pytorch通过torch.utils.tensorboard 使用tensorboard。使用tensorboardx和torch.utils.tensorboard效果相同。
3.1、tensorboard简介
tensorboard功能很强大,支持scalar、image、figure、histogram、audio、text、graph、onnx_graph、embedding、pr_curve和videosummaries等可视化方式。
安装也比较方便,如果使用tensorboardX,先安装tensorflow,然后再安装tensorboardX使用命令:conda install tensorboardX。
如果使用torch.utils.tensorboard,直接使用conda install tensorboard进行安装即可。
下面介绍使用tensorboard的一般步骤。
- 导入
tensorboard,实例化SunnmaryWriter类,指明记录日志路径等信息。
from torch.utils.tensorboard import SummaryWriter
#实例化SummaryWriter,并指明日志存放路径。在当前目录没有logs目录将自动创建。
writer = SummaryWriter(log_dir='logs')
#调用实例
writer.add_xxx()#add_xxx可根据不同需求调用不同的实例,如add_scalar(),add_image()等
#关闭实例
writer.close()
说明:
- 如果是Windows系统,log_dir需要主义路径解析如:
writer = SummaryWriter(log_dir='E:\code\python\pytorchLearn\logs')- SummaryWriter的格式为:
SummaryWriter(log_dir=None,comment='',**kwargs)。其中comment在文件命名加上comment后缀。- 如果不写
log_dir,系统将在当前目录创建一个名为runs的目录。
- 调用相应的API接口,接口的一般格式为:
add_xxx(tag-name,object,iteration-number),即add_xxx(标签,记录的对象,迭代次数)
程序运行完成之后,就会生成名为logs的文件夹。
- 启动
tensorboard服务:
转到logs目录所在的同级目录,在命令行输入如下命令,logdir等式右边可以是相对路径也可以是绝对路径。
tensorboard --logdir=logs --port 6006
在Windows环境下,输入绝对路径的时候需要注意路径解析:
tensorboard --logdir=r'E:\code\python\pytorchLearn\logs' --port 6006
- web展示
在浏览器输入:
http://服务器IP或名称:6006/,如果是本机,服务器名称可以使用localhost。
便可以看到logs目录保存的各种图形。
下面以绘制y=x^2图形为例实际实现一下tensorboard是如何使用的。
- 创建
SummaryWriter实例,然后将标量添加到实例,然后关闭实例。
from torch.utils.tensorboard import SummaryWriter
#创建实例
writer = SummaryWriter(log_dir='logs')
# y=2*x
for i in range(100):
writer.add_scalar('y=x^2',i*i,i)
writer.close()
然后会在当前目录下,产生一个名为logs的文件夹,其中存放的就是可以在web端进行展示的图像。
![]()
- 打开
logs同级的命令窗口,输入下面的命令。
tensorboard --logdir=logs --port 6006
运行的结果如下:

- 在浏览器打开网址
http://localhost:6006/就可以看到可视化后的结果如下。

3.2、可视化神经网络
使用tensorboard实现可视化神经网络
- 导入需要的模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torch.utils.tensorboard import SummaryWriter
- 构建神经网络(带有卷积层的)
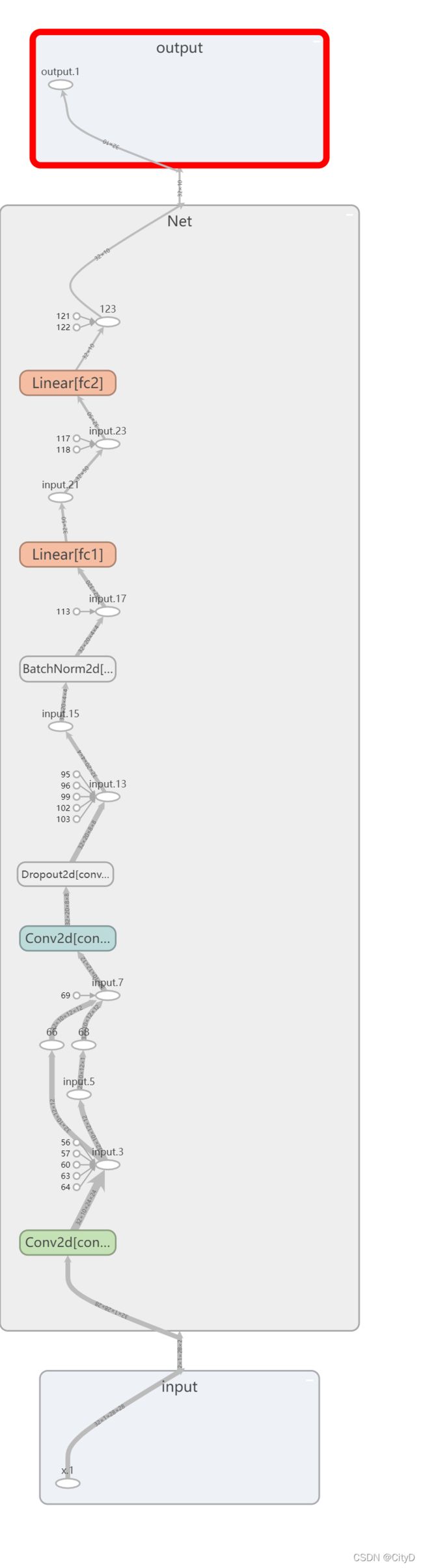
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
#为卷积层,后面章节会介绍
self.conv1=nn.Conv2d(1,10,kernel_size=5)
self.conv2=nn.Conv2d(10,20,kernel_size=5)
#drop层,会丢弃一部分参数,后面详细接受
self.conv2_drop=nn.Dropout2d()
#线性层
self.fc1=nn.Linear(320,50)
self.fc2=nn.Linear(50,10)
#批量归一化
self.bn=nn.BatchNorm2d(20)
def forward(self,x):
#max_pool2d最大池化
x=F.max_pool2d(self.conv1(x),2)
x=F.relu(x)+F.relu(-x)
x=F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)),2))
x=self.bn(x)
x=x.view(-1,320)
x=F.relu(self.fc1(x))
x=F.dropout(x,training=True)
x=self.fc2(x)
x=F.softmax(x,dim=1)
return x
- 把模型保存为一个graph
#定义输入
input = torch.rand(32,1,28,28)
#实例化神经网络
model=Net()
#将model保存为graph
with SummaryWriter(log_dir='logs',comment='Net') as w:
w.add_graph(model,(input,))
- 在命令窗口输入
tensorboard --logdir=logs --port 6006,然后再浏览器输入网址http://localhost:6006/。得到可视化后的网络。
3.3、可视化损失值
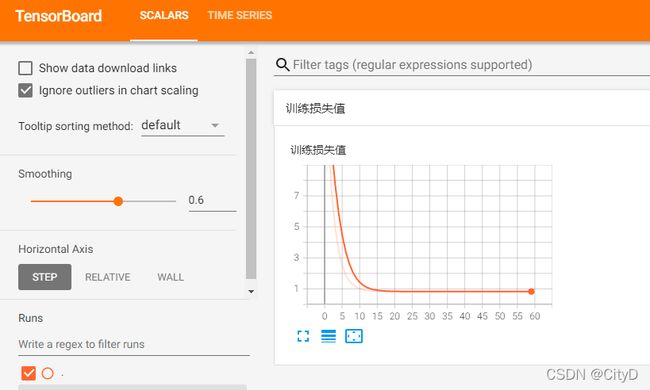
可视化损失值,就是将训练时产生的损失数值进行可视化,与简介中类似,使用add_scalar函数将数值进行可视化。在此,利用一层全连接神经网络,训练一元二次函数产生的损失值可视化为例。
#导入需要的模块
import torch
import torch.nn as nn
import numpy as np
from torch.utils.tensorboard import SummaryWriter
#创建实例
writer=SummaryWriter(log_dir='logs',comment='Linear')
#产生训练数据
np.random.seed(100)
x_train=np.linspace(-1,1,100).reshape(100,1)
y_train=3*np.power(x_train,2)+2+0.2*np.random.rand(x_train.size).reshape(100,1)
#构建模型
model=nn.Linear(1,1)
#损失函数
criterion=nn.MSELoss()
#优化器
optimizer=torch.optim.SGD(model.parameters(),lr=0.1)
#迭代训练
for epoch in range(60):
inputs=torch.from_numpy(x_train).type(torch.FloatTensor)
targets=torch.from_numpy(y_train).type(torch.FloatTensor)
#计算预测值
output=model(inputs)
#计算损失值
loss=criterion(output,targets)
#梯度清零
optimizer.zero_grad()
#反向传播
loss.backward()
#更新参数
optimizer.step()
#保存训练的损失值并进行可视化
writer.add_scalar('训练损失值',loss,epoch)
在命令窗口输入tensorboard --logdir=logs --port 6006,然后再浏览器输入网址http://localhost:6006/。得到可视化后的损失值。
3.4、可视化图像
使用tensorboard中的add_image方法可以对图像进行可视化,因此也可以对网络产生的特征对进行可视化,不同的卷积层的特征图的抽取成都是不一样的,为了便于观察可以使用tensorboard进行可视化。在此,只对图像进行可视化操作,特征图与之类似。
add_image方法的使用以及参数说明如下,所传入图片的格式为torch.Tensor, numpy.array, or string/blobname。
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
#tag (string): Data identifier
#img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data
#global_step (int): Global step value to record
该方法对于传入图片的形状有一定的要求:
img_tensor:默认为 :math:(3, H, W)。 您可以使用torchvision.utils.make_grid()来
将一批张量转换为3xHxW格式或调用add_images让我们完成这项工作。
具有:math:(1, H, W), :math:(H, W), :math:(H, W, 3) 的张量也适用,只要
相应的 dataformats 参数被传递,例如 CHW,HWC,HW。
下面是一个简单的可视化图片的例子。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter(log_dir='logs')
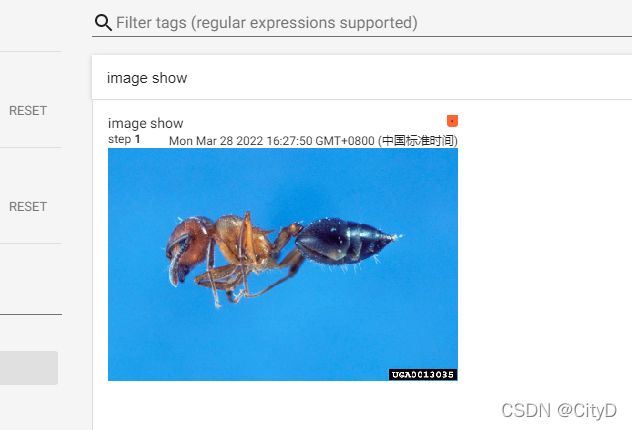
image_path="hymenoptera_data/train/ants/0013035.jpg"
img_PIL=Image.open(image_path)
img_array=np.array(img_PIL)
#(512, 768, 3),因此需要修改dataformats为HWC
print(img_array.shape)
writer.add_image('image show',img_tensor=img_array,global_step=1,dataformats='HWC')
writer.close()
(512, 768, 3)
在命令窗口输入tensorboard --logdir=logs --port 6006,然后再浏览器输入网址http://localhost:6006/。得到可视化后的图片。
4、torchvision
torchvision中有四个功能模块model、datasets、transforms和utils。
datasets:是用来进行数据加载的,PyTorch团队在这个包中帮我们提前处理好了很多很多图片数据集。models:中为我们提供了已经训练好的模型,让我们可以加载之后,直接使用,例如 AlexNet, VGG, ResNet等。transforms:常用的图像操作,例如:随机切割,旋转,数据类型转换,图像到tensor,numpy 数组到tensor,tensor到图像等,从而对源数据进行预处理、增强等。
4.1、transforms
transforms提供了对PIL Image对象和Tensor对象的常用操作。在使用这些方法前首先查看官方文档,了解该方法的输入与输出才能更好的使用这些方法。
以下是transforms的一些常用操作:
Scale/Resize:调整图片的尺寸大小,官方不推荐使用此Scale调整大小。CenterCrop、RandomCrop、RandomSizedCrop:裁剪图片,CenterCrop和RandomCrop裁剪时是固定的size,RandomSizedCrop裁剪时是随机的size。Pad:填充。ToTensor:RandomHorizontalFlip:图像随机水平反转,反转概率为0.5。RandomVerticalFlip:图像随机垂直反转。ColorJitter:修改亮度、对比度和饱和度。Normalize:标准化,即减均值然后除以标准差。ToPILImage:将Tensor转为PIL Image。Compose:功能类似于Sequential,将这些操作像管道一样拼接起来。
下面结合tensorboard对其中几个方法简单使用。导入相关包。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer=SummaryWriter("logs")
img = Image.open('testImg/OIP-C.jpg')
- ToTensor
将PIL Image或者numpy.ndarray转为tensor
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img)
writer.add_image("ToTensor",img_tensor)
可视化结果为:

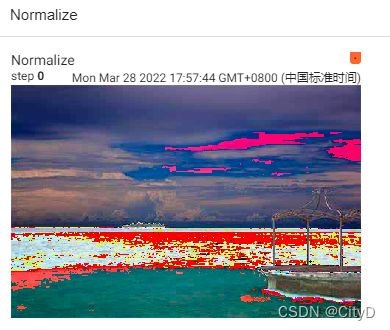
- Normalize
用均值和标准差对张量图像进行归一化。此变换不支持 PIL 图像。给定均值:(mean[1],...,mean[n]) 和标准差:(std[1],..,std[n]) 用于n 通道 ,这个变换将对输入的每个通道进行归一化。计算方式为output[channel] = (input[channel] - mean[channel]) / std[channel]。
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_norm(img_tensor)
writer.add_image("Normalize",img_norm)
可视化结果为:
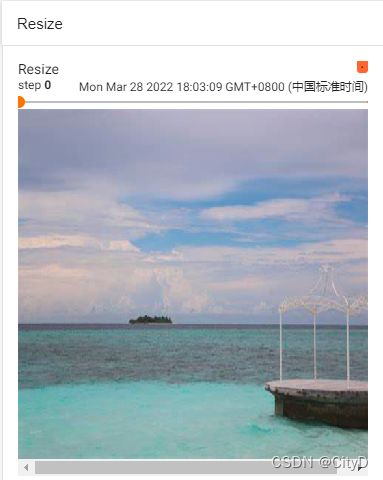
- Resize
将输入图像调整为给定大小。
- 如果输入是Tensor输出也为Tensor
- 如果输入是PIL Image输出也为PIL Image
下面以输入Tensor输出Tensor为例演示Resize。输入PIL Image输出PIL Image,然后再转Tensor在下面结合Compose演示。
trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img_tensor)
writer.add_image("Resize",img_resize,0)
可视化结果为:
- Compose
将这些操作像管道一样拼接起来。Compose()中的参数需要是一个列表。Python中,列表的表示形式为[数据1,数据2,…]。在Compose中,数据需要是transforms类型,所以得到,Compose([transforms参数1,transforms参数2,...])
# PIL Image->PIL Image->Tensor
trans_resize_2=transforms.Resize(300)
trans_compse=transforms.Compose([
trans_resize_2,trans_totensor
])
img_resize_2=trans_compse(img)
writer.add_image("Resize",img_resize_2,1)
可视化结果为:

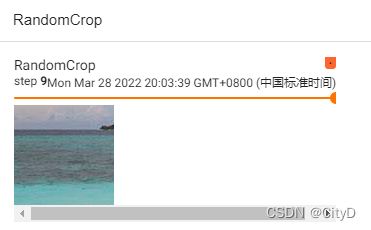
- RandomCrop
在随机位置裁剪给定的图像,需要指定尺寸大小。支持PIL Image和Tensor,输入为什么输出就为什么。下面对十个随机位置进行剪裁。
trans_random=transforms.RandomCrop(100)
for i in range(10):
img_crop=trans_random(img_tensor)
writer.add_image("RandomCrop",img_crop,i)
writer.close()
可视化结果为:
4.2、datasets
datasets主要用于数据加载,有许多常用的数据集,如CIFAR10,MNIST,Kinetics400,ImageNet等。所有的数据集可以参考网址https://pytorch.org/vision/stable/datasets.html。
在此主要介绍CIFAR10数据集的加载和使用,然后结合transforms对其进行操作,然后使用tensorboard对其进行可视化。
CIFAR10数据集的使用格式为:torchvision.datasets.CIFAR10(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
相关参数为:
root (string):存放cifar-10数据集的根目录。train (bool, optional):如果为真,则从训练集创建数据集,否则从测试集创建。transform (callable, optional):一个函数/转换,它接受一个PIL图像并返回一个转换后的版本。download (bool, optional):如果为true,则从Internet下载数据集并将其放在根目录中。如果数据集已经下载,则不会再次下载。
- 使用
datasets下载该数据集。
import torchvision
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./dataset\cifar-10-python.tar.gz
93.9%
Files already downloaded and verified
该数据集与之前我们使用Dataset定义的数据集是一样的,因此可以使用下标获取数据集中的数据。
img,target=test_set[0]
print(img,target)
print(test_set.classes[target])
img.show()
3
cat
![]()
由以上输出可以看出,输出的图片的类型是PIL Image。下面结合使用前面学到的trasnforms对其进行一个处理。
dataset_transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
Files already downloaded and verified
Files already downloaded and verified
然后查看图片的类型,结果为Tensor类型。
img,target=train_set[0]
print(type(img))
最后使用tensorboard对其进行可视化。
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter('cifar10')
for i in range(10):
img ,target=test_set[i]
writer.add_image('test_set',img,i)
writer.close()
可视化的结果为:

4.3、models
torchvision.models子包包含用于解决不同任务的模型定义,包括:图像分类、像素语义分割、对象检测、实例分割、人物关键点检测、视频分类和光流。如AlexNet、VGG、SqueezeNet、GoogLeNet、VGG等网络,更多的详情可以查看官方网址https://pytorch.org/vision/stable/models.html
下面主要介绍一下VGG16网络,主要介绍如何加载使用该网络,以及如何修改该网络中的参数。
VGG16的使用格式为:torchvision.models.vgg16(pretrained: bool = False, progress: bool = True)
pretrained:如果为 True,则返回在 ImageNet 上预训练的模型。progress:如果为 True,则显示下载到 stderr 的进度条。
- 加载预训练和未预训练的
VGG16网络
#未预训练
vgg16_false=torchvision.models.vgg16(pretrained=False)
#预训练好的
vgg16_true=torchvision.models.vgg16(pretrained=True)
Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to C:\Users\76059/.cache\torch\hub\checkpoints\vgg16-397923af.pth
99.6%
查看VGG16的网络结构。
vgg16_false
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
可以看出最后一层为输出为1000的线性层,如果将其应用到CIFAR-10上,则需要将最后一层改为输出为10的线性层。现在有两种方法进行修改。
-
在VGG16原来的网络上的最后在添加一层。
-
将原来的VGG16的网络的最后一层进行修改。
-
在VGG16原来的网络上的最后再添加一层,并添加到classifier中
import torch.nn as nn
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))
vgg16_true
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
)
- 将原来的VGG16的网络的最后一层进行修改
vgg16_false.classifier[6]=nn.Linear(4096,10)
vgg16_false
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)