优化程序性能
程序优化是我学的不好的一块地方,在这里重新仔细阅读,可能会有很多理解不准确的地方,敬请理解。
CSAPP在第五章讨论了优化程序性能,这个优化跟编译器中进行的优化是不一样的,编译器通过剖析代码生成对应的机器代码,根据你设定的优化选项进行优化。但是编译器进行的优化又是保守的,他要保证编译出来的代码与预想的行为完全一致,因此有可能产生不同行为的优化方法他都不会采用,他会优化的非常小心,而且由于编译器是对静态的程序进行优化,因此他不能对程序的行为进行任何的分析,所以当不知道会发生什么情况时,他就会不采用优化策略。
但是我们没有考虑这些问题,我们的行为更像是调整我们所写的代码,通过改变其指令的顺序或其他一些关联行为,使我们的程序拥有更好的性能。(插一句题外话,我好像刚在流水线周期里面提过,CPU提供了我们对于程序指令的抽象,让我们相信我们的程序时顺序安全执行的,那按照这个理论来说,我们做优化程序这件事情,就显得是越俎代庖)
我们通过时钟周期数去反映程序的性能,这一点很重要。
CSAPP和PPT加在一起就有点乱了,所以我不会剖析了,只会罗列出各种优化的方法,供大家参考。
一般有用的优化
代码移动
我们用代码移动去消除不必要的工作:函数调用、条件测试、内存引用等——不依赖于及其。如全局变量比局部变量快。
代码移动:是为了减少执行的频率,如果总是产生相同的结果就将其从循环中移出。(换句话说就是,能使用全局变量的就不使用局部变量,能使用寄存器的就不去访问内存,重复做一件事情的东西就把它从循环中移出)
几个例子:

 复杂运算简化
复杂运算简化
用更简单的方法替换昂贵的操作,比如用移位、加,替代乘法/除法;
共享公用子表达式
重用表达式的一部分使得其只需计算一次。

妨碍优化的因素/优化障碍
函数调用
将不会变化的调用移到循环外

内存别名使用
在C中很容易发生两个不同的内存指向相同的位置,因为C中允许做地址运算也允许访问存储结构,所以编译器对于这种情况就会采用保守的方法,并不进行优化,不断的读写内存。
因此养成引入局部变量的习惯是非常重要的:在循环中累积——用寄存器别名替换;告诉编译器不要检查内存别名使用的方法。


移除内存别名的使用改用局部变量后,就不需要存储中间结果。
(PPT上写告诉编译器怎么实现不要检查内存别名使用,书上并没有写,而且另外一点是书上这一节的名字叫做消除不必要的内存别名使用)
指令级并行
要理解什么是指令级并行,就要去理解现代处理器是怎么架构的,并且了解他是怎么工作的。在这里不进行详细赘述,因此这里不是重点,也不是本节需要着重理解的地方。
现代处理器使用复杂的硬件,进行复杂的操作,但是对于我们仍然是一个顺序执行的安全抽象。但是在实际的处理器中,我们对多条指令同时求值,称为指令级并行。但是即使采用复杂奇异的微处理器结构,我们最后还是给用户提供简单的顺序执行的表象。

我们在一个执行单元中又塞入好多个功能单元,从而提升每个单元的性能。
我们使用数据流去考察程序性能,目的是为了展现不同操作之间的数据相关是如何限制它们的执行顺序,这些限制形成关键路径,从而方便我们考察一组机器指令所需时钟周期数的下界。
比如说对于一个这样的程序:

其一个循环可以画作:
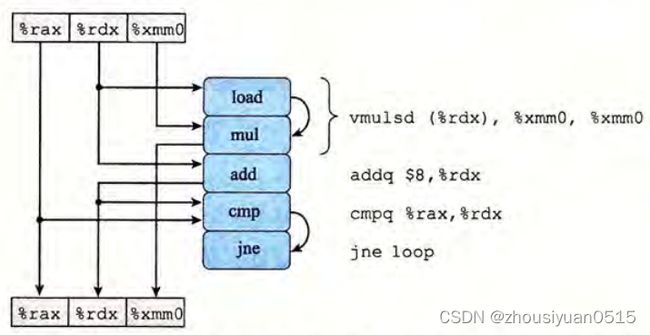
将其扩展n次就可以得到其数据流的图像。
优化
我们以一个普通的程序优化来打开我们的优化理解。
这段程序用来计算向量元素的和或积。

简单优化
首先进行我们上述讨论过的简单优化:

可以看到,我们使用代码移动,将vec_length()和get_vec_element()移到循环外,避免每次进行函数调用的开销;
用t作为临时变量累积结果,避免每次都需要访存并写入内存。
循环展开2*1


每个循环运行两倍更有用的工作,但是我们发现并没有很大的提升,只对整数+有帮助,原因是我们去考察我们的关键路径,n次运算操作依然是制约我们性能的决定性因素,但是2*1展开并没有帮助我们减少关键路径的时间。
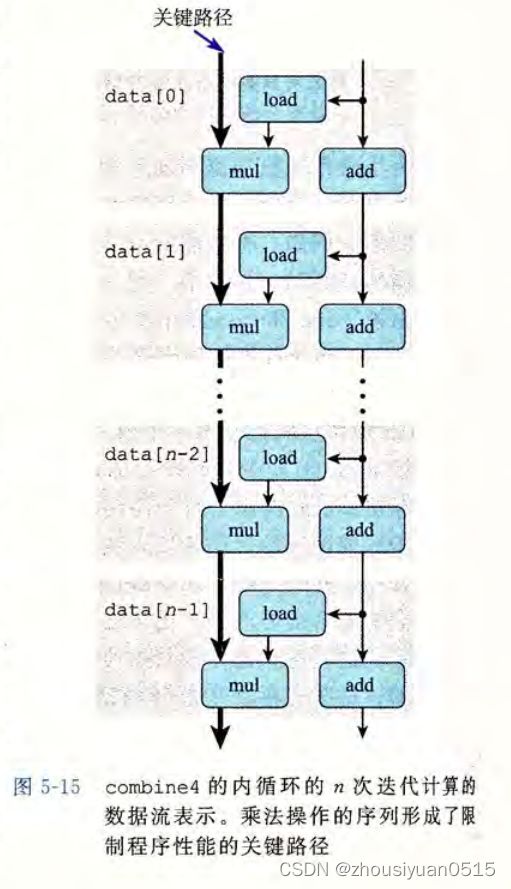
我们去继续采用3*1或之后的展开形式会发现仍然没有提升,这很大程度上证明了我们的说法是正确的。
提高并行性
所以我们要从提高并行性的角度去考虑这个问题, 我们将一组合并运算分割成两个或更多的部分,并在最后合并结果来提高性能。
2*2循环展开

我们看到这次我们使用了两次循环展开,以使每次迭代合并更多的元素,并将奇数累积在x1中,偶数值累积在x1中,最终合并x0和x1计算最终的结果,可以看到我们打破了延迟界限。

2*1a重组的循环展开

直接看上面这段代码,可以明显的看到,我们并不是进行展开,而是相对于原本的2*1展开进行了重新结合变换,括号改变了向量元素与累积值acc的合并顺序,产生了我们现在看到的循环展开形式。
初看可能看不出来与之前的2*1的区别,我们看到,来自于vmovsd和第一个vmulsd的load指令从内存中加载向量元素i和i + 1,第一个mul操作把他吗撑起来,然后第二个mul操作把这个结果诚意累积值acc。
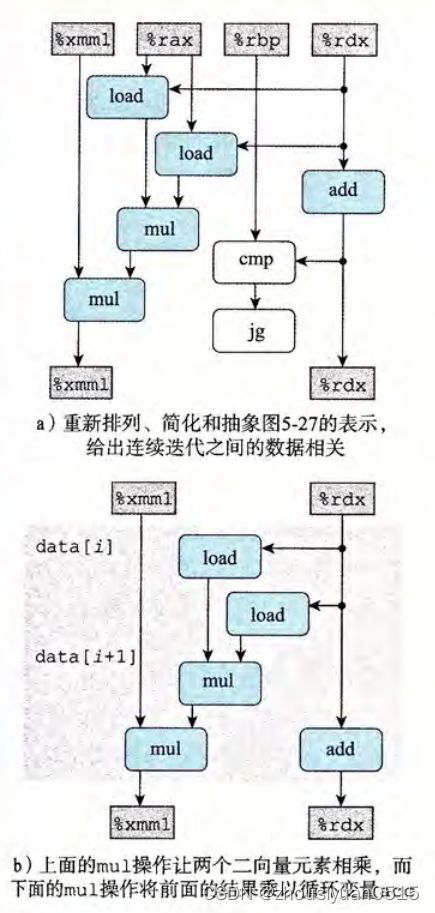

所以我们看到这次的关键路径变成了n/2次乘法运算,从而带来了性能提升。
限制因素
我们在数据流图中通过关键路径指明了执行程序所需时间的基本下界,如果这条链上所有延迟之和为T,我们就需要至少T个周期。
寄存器溢出
如果我们在并行时超过了可用的寄存器数量,就会导致溢出,某些值会被存放在内存中,因此会反噬程序,让程序甚至变得更差。
分支预测和预测错误惩罚
我们并不用过分关心可预测的分支,虽然我们错误预测分支可能会导致很大的影响,但是我们对于分支预测逻辑和其长期的趋势会让我们更容易预测对分支,比如我们只会在最后一次循环分支收到预测错误惩罚。
我们书写适合条件传送的代码,这一点是第三章就已经提出的,但是我个人觉得这个工作更不像是程序员做的事情,因此在此持怀疑态度。
另外,程序的局部性和程序剖析会更好的拯救我们,给我们的优化提供方向。
剩下的不想写了,也许考研之后会看看,但是我觉得仍然觉得CSAPP不是一本完美的书,他把软硬剥离开来,把很多概念拿出来解读,但是又不给你系统的说明,很多时候会产生困惑,但是如果你了解其底层的实现,问题会更少一点,会变成叹息,这个问题没有得到完整的探讨就戛然而止,因此CSAPP是一本很全面的书,是一本优秀的书,但不是一本可以常读常新的书。