残差网络结构(1)----ResNet,ResNext,ResNetV2
目录
1,CNN的发展史
2,基础残差网络ResNet和ResNext
2.1 ResNet和ResNext
2.2 ResNet18到ResNet153家族
2.3 ResNetV1和ResNetV2(激活和BN放哪里是正确的)
1,CNN的发展史
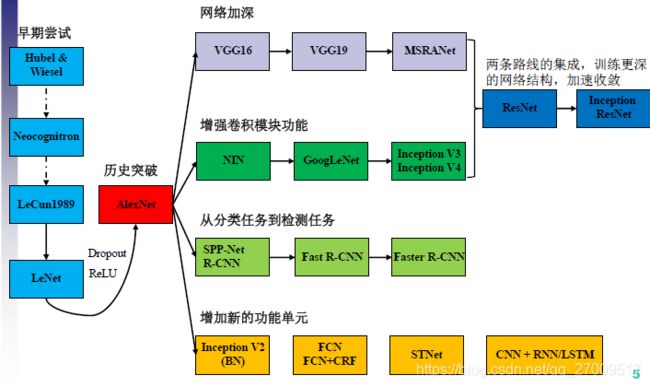
从上图的上半段可以看出,在1*1的卷积的应用在增加网络的深度和宽度后,残差连接的出现,成为了模型设计中的一个新的标准,同时也衍生出了很多新的网络。下面介绍一下,基于残差连接的经典网络。
2,基础残差网络ResNet和ResNext
2.1 ResNet和ResNext
网络 ResNeXt,同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。ResNeXt是网络ResNet在宽度上的一个扩充。下图左边是ResNet,右边是ResNeXt网络结构

ResNeXt的基本模块包含了32个分支,每个分支一模一样。每个矩形框中的参数分别表示输入维度,卷积大小,输出维度。它主要是通过1*1的卷积 层进行降维然后再升维。
下图中是ResNet-50 和 ResNeXt-50 的内部结构,最后两行说明二者之间的参数复杂度差别不大。

50 的原因: 1+9+12+18+9+1=50 只算卷积层,不计算池化层
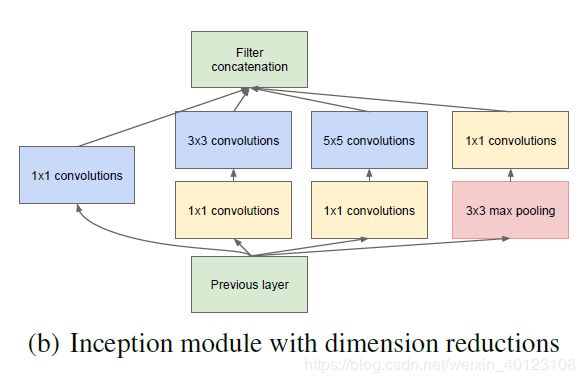
备注:基础思想 Inception结构
2.2 ResNet18到ResNet153家族
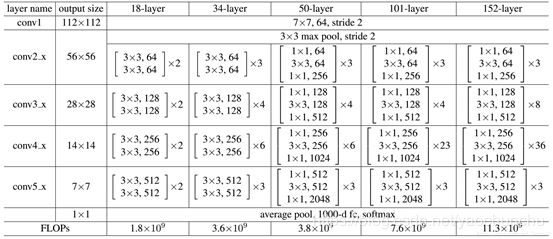
出镜率比较高的是 ResNet50和ResNet101,这两个运用比较多一些;
上面一共提出了5种深度的ResNet,分别是18,34,50,101和152,首先看表2最左侧,我们发现所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x,之后的其他论文也会专门用这个称呼指代ResNet50或者101的每部分。
拿101-layer那列,我们先看看101-layer是不是真的是101层网络,首先有个输入7x7x64的卷积,然后经过3 + 4 + 23 + 3 = 33个building block,每个block为3层,所以有33 x 3 = 99层,最后有个fc层(用于分类),所以1 + 99 + 1 = 101层,确实有101层网络;
注:101层网络仅仅指卷积或者全连接层,而激活层或者Pooling层并没有计算在内; 这里我们关注50-layer和101-layer这两列,可以发现,它们唯一的不同在于conv4_x,ResNet50有6个block,而ResNet101有23个block,查了17个block,也就是17 x 3 = 51层。
2.3 ResNetV1和ResNetV2(激活和BN放哪里是正确的)
ResNet残差网络,想必大家一定很熟悉了,那么先考考大家,下面(1)-(5)的结构哪个是我们常用的ResNet结构?
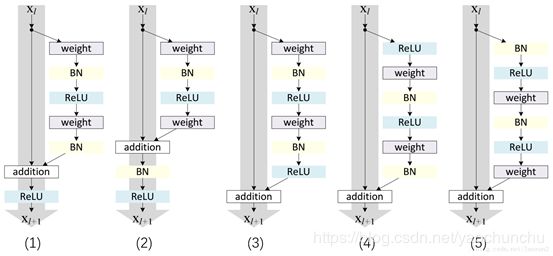
其中weight指conv层,BN指Batch Normalization层,ReLU指激活层,addition指相加;根据ResNet的描述,似乎以上五组都符合,那么2016年ResNet原文是哪一个结构呢?以及其他四组结构也都work么?我们不禁有了这两个疑问,伴随着疑问我们一一揭开谜题;
针对第一个问题,ResNet原文中使用的结构是(1)。原文中的结构的特点有两个:1)BN和ReLU在weight的后面;2)最后的ReLU在addition的后面;
对于特点1),属于常规范畴,我们平时也都这个顺序:Conv->BN->ReLU;
对于特点2),为什么ReLU放在addition后面呢?按照常规,不是应该是图(3)这种么,那么我们接下来引出的问题就是:
图(3)的结构work么?
对于每个图右侧部分我们称作“residual”分支,左侧部分我们称作“identity”分支,如果ReLU作为“residual”分支的结尾,我们不难发现“residual”分支的结果永远非负,这样前向的时候输入会单调递增,从而会影响特征的表达能力,所以我们希望“residual”分支的结果应该在(-∞, +∞);这点也是我们以后设计网络时所要注意的。
对于图(3)不OK的情况,那如果把BN也挪到addition后面呢?如图(2),同时也保证了“residual”分支的取值范围?
这里BN改变了“identity”分支的分布,影响了信息的传递,在训练的时候会阻碍loss的下降;这里大家肯定又有个问题:
为什么“identity”分支发生变化,会影响信息传递,从而影响训练呢?
这里简单回顾ResNet的公式:

因此 图(2)也不OK
在分析图(4)和图(5)之前,我们引出一个概念:”Post-activation”激活之后和”Pre-activation”激活之前,”Post-activation”激活之后的意思是激活函数处于卷积层和BN层之后。
”Pre-activation”激活之前的意思是激活函数处于卷积层之前。
其中Post和Pre的概念是相对于weight(conv)层来说的,那么我们不难发现,图(1), (2), (3)都是”Post-activation”,图(4), (5)都是”Pre-activation”,那么两种模式哪一个更好呢?这里我们就用实验结果说话。

上图是5种结构在Cifar10上的实验结果,一共实验了两种网络ResNet110和ResNet164。
从实验结果上,我们可以发现图(4)的结构与ResNet原结构伯仲之间,稍稍逊色,然而图(5)的结构却好于ResNet原结构。图5的结构好的原因在于两点:1)反向传播基本符合假设,信息传递无阻碍;2)BN层作为pre-activation,起到了正则化的作用;
最后我们通常把图5的结构称作ResNetV2,这里我们给出ResNetV1和ResNetV2结构:

上面两个结构提升好的原因在于两点:1)反向传播基本符合假设,信息传递无阻碍;2)BN层作为pre-activation,起到了正则化的作用;
该部分内容参考的博文为:
深度学习经典网络(4)ResNet深度残差网络结构详解_青衫憶笙-CSDN博客_resnet网络结构