深度学习入门(9)神经网络Affine与Softmax层的计算图表示方式及其误差反向传播的代码实现
《深度学习入门》系列文章目录
深度学习入门 (1)感知机
深度学习入门(2)神经网络
深度学习入门(3)神经网络参数梯度的计算方式
深度学习入门(4)【深度学习实战】无框架实现两层神经网络的搭建与训练过程
深度学习入门(5)如何对神经网络模型训练结果进行评价
深度学习入门(6)误差反向传播基础---计算图与链式法则使用
深度学习入门(7)误差反向传播计算方式及简单计算层的实现
深度学习入门(8)激活函数ReLU和 Sigmoid的计算图表示方式及其误差反向传播的代码实现
前几篇博文介绍了计算图基础、简单层的实现以及激活函数的层实现。本篇文章主要介绍神经网络中Affine层与sofmax层的计算图及其反向传播层的代码实现。
目录
1 Affine与Softmax层的实现
1.1 Affine层
1.2 批量版的Affine层
1.3 Softmax-with-Loss层
1 Affine与Softmax层的实现
1.1 Affine层
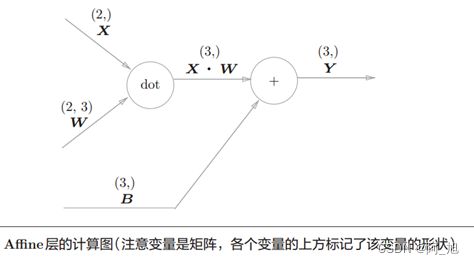
神经元的加权和可以用 Y = np.dot(X, W) + B计算出来。然后,Y 经过激活函数转换后,传递给下一层。这就是神经网络正向传播的流程。
神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换” 。将进行仿射变换的处理实现为“Affine层”。
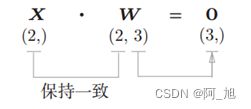
Y = np.dot(X, W) + B,计算图如下:
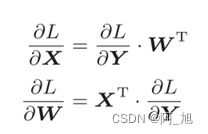
式中WT的T表示转置。转置操作会把W的元素(i, j)换成元素(j, i)。
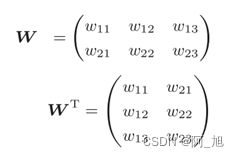
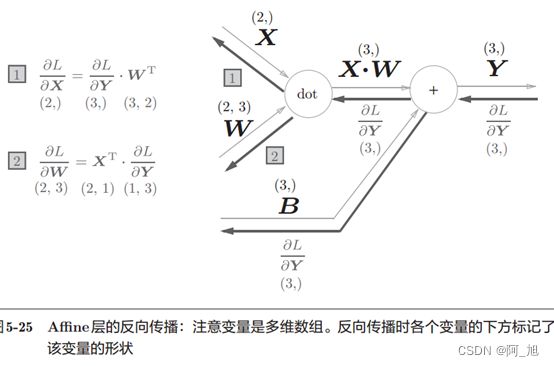
X和αL/αX形状相同, W和αL/αW形状相同。从下面的数学式可以很明确地看出X和
αL/αX形状相同。
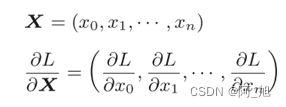
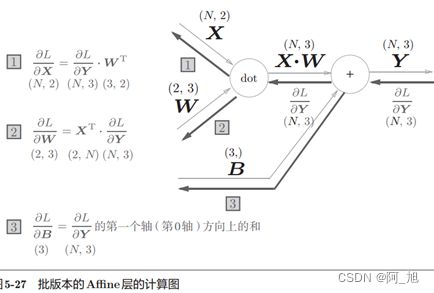
1.2 批量版的Affine层
前面介绍的Af ne层的输入X是以单个数据为对象的。现在我们考虑N个数据一起进行正向传播的情况,也就是批版本的Affine层。



1.3 Softmax-with-Loss层
softmax函数会将输入值正规化之后再输出。比如手写数字识别时, Softmax层的输出如图所示。
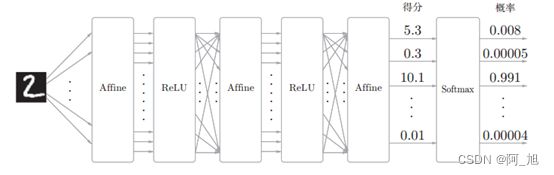
注:神经网络中进行的处理有推理(inference)和学习两个阶段。神经网络的推理通常不使用Softmax层。比如,用图5-28的网络进行推理时,会将最后一个Affine层的输出作为识别结果。神经网络中未被正规化的输出结果(上图中 Softmax 层前面的 Affine 层的输出)有时被称为“得分”。也就是说,当神经网络的推理只需要给出一个答案的情况下,因为此时只对得分最大值感兴趣,所以不需要Softmax层。不过,神经网络的学习阶段则需要Softmax层。
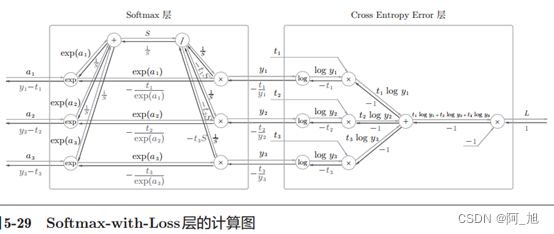
下面来实现Softmax层。考虑到这里也包含作为损失函数的交叉熵误差( cross entropy error),所以称为“ Softmax-with-Loss层”。 Softmax-withLoss层( Softmax函数和交叉熵误差的计算图如下图所示。
注意:交叉熵函数中的log是默认以e为底的。
计算图简化版:
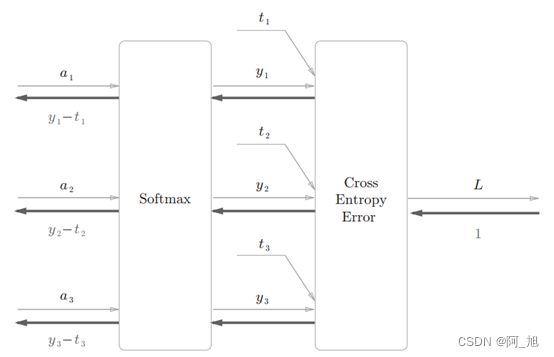
softmax函数记为Softmax层,交叉熵误差记为Cross Entropy Error层。这里假设要进行3类分类,从前面的层接收3个输入(得分)。如图5-30所示, Softmax层将输入( a1, a2, a3)正规化,输出( y1,y2, y3)。 Cross Entropy Error层接收Softmax的输出( y1, y2, y3)和教师标签( t1,t2, t3),从这些数据中输出损失L。
Softmax层的反向传播得到了( y1 - t1, y2 - t2, y3 - t3)这样“漂亮”的结果。由于( y1, y2, y3)是Softmax层的输出,( t1, t2, t3)是监督数据,所以( y1 - t1, y2 - t2, y3 - t3)是Softmax层的输出和教师标签的差分。神经网络的反向传播会把这个差分表示的误差传递给前面的层,这是神经网络学习中的重要性质。
注:使用交叉熵误差作为 softmax 函数的损失函数后,反向传播得到( y1 - t1, y2 - t2, y3 - t3)这样“漂亮”的结果。实际上,这样“漂亮” 的结果并不是偶然的,而是为了得到这样的结果,特意设计了交叉熵误差函数。回归问题中输出层使用“恒等函数”,损失函数使用“平方和误差”,也是出于同样的理由(3.5节)。也就是说,使用“平方和误差”作为“恒等函数”的损失函数,反向传播才能得到( y1 -t1, y2 - t2, y3 - t3)这样“漂亮”的结果。
softmax-with-Loss层的代码实现:

请注意反向传播时,将要传播的值除以批的大小( batch_size)后,传递给前面的层的是单个数据的误差。
如果内容对你有帮助,感谢点赞+关注哦!
更多干货内容持续更新中…