【论文阅读】StegaStamp: Invisible Hyperlinks in Physical Photographs
前言
- 博客主页:睡晚不猿序程
- ⌚首发时间:2022.7.27
- ⏰最近更新时间:2022.7.27
- 本文由 睡晚不猿序程 原创,首发于 CSDN
- 作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
目录
文章目录
- 前言
- 1. 内容简介
- 2. 摘要浏览
- 3. 图片、表格浏览
- 4. 引言浏览
-
- 4.1 总结
- 5. 自由阅读
-
- 5.1 为了实现在现实世界的鲁棒性进行的训练(原文第三章)
-
- 5.1.1 透视变换
- 5.1.2 运动和失焦模糊
- 5.1.3 色彩操作
- 5.1.4 噪声
- 5.1.5 JPEG 压缩
- 5.2 实施细节
-
- 5.2.1 编码器
- 5.2.2 解码器
- 5.2.3 探测器
- 5.4 训练过程
- 5.5 局限性
- 5.6 网络结构
- 6. 总结、预告
-
- 6.1 总结
- 6.2 预告
1. 内容简介
准备开一个新的栏目啦,记录一下自己看论文的时候写的笔记以及思考。
本博客的内容为《StegaStamp: Invisible Hyperlinks in Physical Photographs》的笔记
论文标题:《StegaStamp: Invisible Hyperlinks in Physical Photographs》
作者:Matthew Tancik, Ben Mildenhall, Ren Ng
发布于:CVPR 2020
自己认为的关键词:暗水印,隐写术
2. 摘要浏览
看一个文章的摘要我们可以大致知道这篇文章的大致内容了。
解决的问题:
本文工作:这篇文章提出了一种结构,算法和系统雏形完成了信息在图像的不可见插入
主要贡献:StegaStamp,能将超链接的比特串编码插入到图片中去
Stegastamp的架构:StegaStamp 是一个深度神经网络,通过学习编码算法,从而让信息的插入以及提取对图像的变换鲁棒
完成效果:在亮,暗,透视变形,遮挡以及不同的距离拍摄表现良好。在经过了错误矫正后可以插入 56 bit 的信息
3. 图片、表格浏览
图一
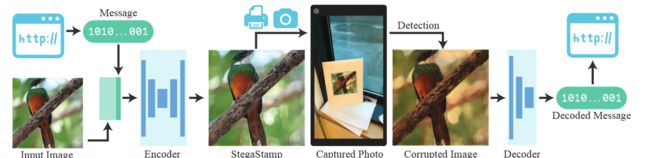
这张图片是整个 StegaStamp 的结构:
- 给定输入图片,然后把信息转换为二进制表示,并与输入图像进行拼接
- 将拼接之后的数据传入编码器进行编码,得到一个 StegaStamp
- StegaStamp 通过打印或者是屏幕显示来呈现在镜头前
- 镜头画面经过探测器的探测提取出经过变换的图片进行恢复,然后将其送入解码器
- 解码器得到二进制的编码信息
图二

这张图是 StegaStamp 进行数据嵌入的效果样例,最后一列是编码器生成的残差,会被加到原图像中来生成编码图像,这几个样例编码了 100 bit,且对现实世界中打印和显示中产生的干扰鲁棒。
图三
这张图显示了被添加到编码器和解码器之间的噪声层,他会模拟图片经过了打印或者是显示之后给图片造成的变换,以此让网络具有对打印/显示具有鲁棒性
图四

这张图显示了 StegaStamp 在现实世界中进行解码的效果
图五

这张图表示,虽然我们没有明确的训练网络的抗遮挡能力,但是训练完成的网络仍然具有一些抗遮挡能力
表一

该表展示了使用了六种显示方式(打印和屏幕显示各三种)并用三种接收方式(网络摄像头,手机镜头,单反相机)对隐藏信息进行提取的正确率
图六

这个表格对比了其他几个模型的效果
表二
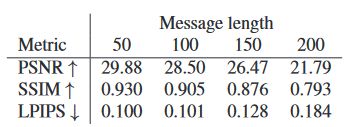
这个表格展示了不同的嵌入信息量的 PSNR,SSIM 和 LPIPS 指标
图七
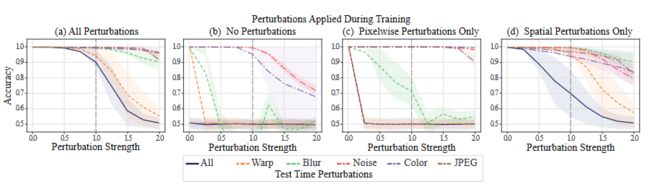
对噪声层进行消融实验,发现如果对图像的色彩(像素级)变换和空间变换的模拟缺一不可,不然会导致鲁棒性的降低
图八

使用不同长度的隐写信息进行嵌入,并展现其效果
4. 引言浏览
引言提出,现在有很多的类似二维码的数据转换工具,但是我们的方法可以认为是一种与上面的几种方式互补的办法,可以让数字信息隐式的插入到现实直接中普遍存在的图片中。
他提出了三种主要使用场景
- 在市场(比如超市),产品的照片和产品的价格单可能离得很远,如果能把价格隐式地插入到产品的图片当中去,效果就会很不错
- 大学的教职员工墙:扫描导师照片就可以获得信息
- 时报广场的广告牌:扫描广告获得信息
成果:StegaStamp,整个系统是一个神经网络,编码器和解码器一起联合训练
贡献:第一个端到端的深度水印系统
和以往工作的不同:在编码器和解码器之间添加了一些像素或者是空间的变化来近似现实世界中带来的扰动(比如打印,显示,图像裁切)
结果:正确率95%,在保留了很好的视觉效果的情况下
4.1 总结
本论文应该是提出了一个深度神经网络,实现了端到端的信息隐写,并且可以抵抗由打印、显示对图片的干扰,完成隐写信息的提取。但是隐写信息只能在 100 bit 左右,再高的话图像效果就变差了很多,有着很明显的痕迹。
5. 自由阅读
在这里我将会按照我自己好奇的顺序来阅读这篇文章啦,因为是刚开始尝试阅读论文,所以我的阅读可能将会没什么章法,笔记也可能会变得很混乱,请各位前辈大佬多多指教了!
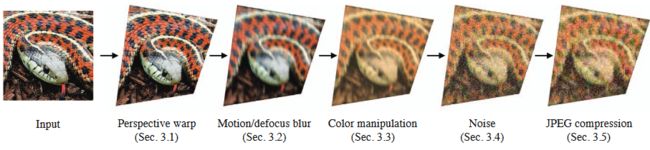
5.1 为了实现在现实世界的鲁棒性进行的训练(原文第三章)
为了实现鲁棒,在编码器的输出以及解码器的输入之间,添加了一个噪声层,这个噪声层由对图片进行多种扰动组成

比如上面的视角变换,失焦,颜色变换,添加噪声,jpeg 压缩等
通过上面这几种操作来模拟图片被打印、显示时候带来的扰动
对比之前的工作
之前的工作也有这样做,但是他们做的变换更少,更局限
HiDDeN:只进行了像素方面的变换,而没有进行空间方面的变换
Deep ChArUco:使用了空间或者是非空间扰动来训练
我们综合了他们的方法,让编码器解码器合作来鲁棒地嵌入密码信息,通过物理显示图片的管道(比如图片-编码图片-打印图片-秘密信息)
5.1.1 透视变换
阅读资料:单应性,
假设一个单孔摄像机,两张图片会和这个镜头相关(单应性?)
我们来创造一个随机的单应性,去模拟相机镜头没有垂直正对着图片的情况。
实际操作:随机扰动四个较角的坐标(在40像素之内),接着把原图像映射到经过了扰动之后的坐标处(也就是变形了)
我们对原图像进行了双线性重采样来生成经过了透视变换的图像
5.1.2 运动和失焦模糊
阅读资料:高斯模糊1,高斯模糊2
相机运动以及自动对焦的错误都会带来模糊
运动模糊:用随机角度生成了一个线性模糊核,大小为3或者7
失焦模糊:用了高斯模糊核,模糊半径1-3【是这样理解吗?】
5.1.3 色彩操作
打印/显示的色域相比起RGB色域要低,而且相机会修改其输出(白平衡,色彩校正矩阵)
我们利用了多种的色彩变换来模拟这个过程
- 色相转变:每个RGB通道偏移[-0.1, 0.1](在这个范围内随机取样)
- 饱和度:在完整的RGB图像和他的灰度图像之间使用随机线性插值
- 亮度和对比度:改变放射直方图的尺度, m x + b mx+b mx+b,其中 m ∼ U [ 0.5 , 1.5 ] m\sim U[0.5,1.5] m∼U[0.5,1.5], b ∼ U [ − 0.3 , 0.3 ] b\sim U[-0.3,0.3] b∼U[−0.3,0.3]
做了如上变换后,把色彩通道裁切到[0,1]【有点不理解】
5.1.4 噪声
使用了一个高斯噪声层来模拟相机带来的噪声
5.1.5 JPEG 压缩
阅读资料:JPEG压缩
参考:[Richard Shin and Dawn Song. Jpeg-resistant adversarial images. In NeurIPS Workshop on Machine Learning and Computer Security, 2017](Jpeg-resistant adversarial images)
使用了该公式【用这个公式干嘛有点弄不懂】
q ( x ) = { x 3 : ∣ x ∣ < 0.5 x : ∣ x ∣ ≥ 0.5 q(x)= \begin{cases}x^{3} & :|x|<0.5 \\ x & :|x| \geq 0.5\end{cases} q(x)={x3x:∣x∣<0.5:∣x∣≥0.5
JPEG质量范围为[50,100]
5.2 实施细节
5.2.1 编码器
结构:类 U-Net,接受四通道 400×400 输入,其中一个通道是密码信息,输出为三通道 RGB 残差图像
信息处理:信息是一个长度为 100 bit 的比特串,通过一个全连接层把他变成 50*50*3 的张量,然后再上采样变成 400*400*3 的张量
作者发现对信息进行预处理可以加快收敛
5.2.2 解码器
加入了一个空间变换网络来抵抗小的视角变换。
解码器通过一系列卷积,dense,最后通过一个 sigmoid 函数输出和原本信息一样长的信息,使用交叉熵损失进行监督
5.2.3 探测器
我们直接使用了 BiSeNet 来对认为含有 StegaStamp 的区域进行切割
训练数据集:随机转换成 StegaStamp 的图像插入到 DIV2K 中的图像中
测试的时候我们把一个四边形拟合到网络认为可能有 StegaStamp 的区域,然后再计算单应性变形,把他转换为400*400
5.4 训练过程
数据集:MIRFLICKR(重采样至400*400分辨率)
评价网络:作为整个损失的一部分,我们用了一个评价网络来预测是否有信息被编码到图形中(像GAN的思想),他被当作是视觉上的损失,这个网络由多个卷积层最后连着一个最大池化层。
评价网络训练:输入图片和编码图片被分类并使用 Wasserstein 损失进行监督,评价网络是和编解码器交替进行训练的
损失:使用了以下几种损失:
- L 2 L_2 L2 正则化残差损失( L R L_R LR )
- LPIPS 视觉损失( L P L_P LP)
- 评价损失( L C L_C LC)
- 信息的交叉熵损失( L M L_M LM)
训练损失就是上面这几种损失的加权和
L = λ R L R + λ P L P + λ C L C + λ M L M L=\lambda_RL_R+\lambda_PL_P+\lambda_CL_C+\lambda_ML_M L=λRLR+λPLP+λCLC+λMLM
训练的时候发现的三种损失函数调整有助于收敛:
- 随着编码器训练到高精度的时候, λ \lambda λ 要全部初始化为0,接着再线性增加
- 图像的扰动也要从 0 开始,其中透视变换是最敏感的扰动了,所以要增加的最缓慢
- 模型会学习在图像边缘分散注意力(希望这个可以有助于定位)所以我们通过余弦下降增加边缘的L2损失来减轻这种影响
5.5 局限性
-
残差图像的添加在图像的大块低频区域较为明显
可以改进这个结构或者是损失函数(作者说的:D)
-
使用现成网络作为探测器成为了该系统的瓶颈
而且我们还假设 StegaStamp 是一个单个的,方形图像,所以导致了 StegaStamp 如果嵌入到大图像的某个区域就无法检测了
作者说如果可以嵌入很多个块进入一个大图像,那会更为灵活
5.6 网络结构
网络结构在论文的附录中,CVPR 好像有要求论文的页数,所以附录没附带,可以下载 arxiv 版本
编码器:

- k:卷积核大小
- s:步长
- chns:通道数
- in 和 out :每一层输入输出的累积步长【这是啥意思?】
- +:拼接
- 除了最后一层,每一层之后都使用 ReLU。
解码器:
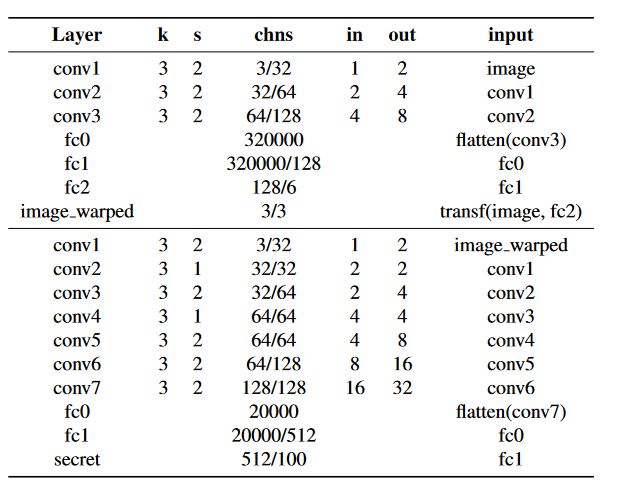
- fc:全连接层
- 网络的前半段输出一个放射翘曲【啥东西】接着用一个可微的变换层处理再进行输出。这个经过变换的结果被喂给网络的第二部分
- 网络的每一层之后都使用ReLU,除了空间变换层的前一层。
6. 总结、预告
6.1 总结
本文是我在阅读论文的时候顺手记录下来的想法以及笔记,文章的前半部分受到了点李沐老师的影响,就先看了摘要,然后就去看文章中的每个图片以及表格,了解了这篇文章做了啥,然后再去看引言,然后自行阅读感兴趣的部分。
感觉看的时候还是有一些问题不是很理解,我都使用了【】进行了标记,之后理解了将会进行修改。
也算是第一次认真的看论文,方式肯定还是有很大缺陷,看了也感觉和没看一样iai,有点不知道看完还需要做些什么,代码也有调通,但是代码使用的 TensorFlow 在未来似乎不会用到,有机会把他用Pytorch重写吗?
好了,文章总结:本文提出了一个名为 StegaStamp 的模型,他可以实现水印信息的隐写,并能在打印以及显示屏显示的情况下保持鲁棒性。
6.2 预告
感觉自己经常在摸鱼,接下来还是要 push 一下自己的,接下来打算学习 Transformer,以及 swim-transformer,在这里上一个大佬的链接,感谢大佬的汇总,接下来打算学习这方面的知识啦~
大家下次见~