【JavaEE初阶】第三节.多线程基础篇
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
文章目录
前言
一、认识线程
二、多线程程序
2.1 第一个Java多线程程序
2.2 怎么样观察线程的详细情况
2.3 sleep方法
2.4 run 和 start 方法的区别是什么
三、创建线程
3.1 继承 Thread类
3.2 实现 Runnable接口
3.3 使用 匿名内部类 来创建线程
3.4 使用Runnable接口,以匿名内部类的方式创建线程
3.5 使用Lambda表达式创建线程(推荐做法)
四、多线程的优点
五、多线程的使用场景
总结
前言
今天我们将进入到多线程基础的学习中,本节内容我们将对线程有一定的了解,学会掌握创建线程以及了解线程的优点等等,就让我们一起进入到今天的学习当中吧!!!!!!!!
提示:以下是本篇文章正文内容,下面案例可供参考
一、认识线程
首先我们需要知道,为啥要有多个进程呢?
那是因为我们要 并发编程(CPU 单个核心已经发展到极致了,要想提升算力,就得使用多个核心)
引入 并发编程,最大的目地就是为了能够充分的利用好 CPU 的多核资源(如果在写代码的时候,不去处理一下,默认只会用到一个核心,造成资源浪费)
使用 多进程 这种模型,是可以完全做到 并发编程,并且也能够使 CPU 多核被充分利用!!!
但是,在有些场景下,会存在问题:
如果需要频繁的创建/销毁进程,这个时候就会比较低效!!!
例如,写了一个服务器,服务器需要同一时刻 给很多客户端提供服务的;此时,就需要使用到 并发编程 了
典型的做法,就是每个客户端给他分配一个进程,提供一对一的服务;客户端来了,就需要创建进程;客户端走了,就需要销毁进程
如果客户端来来回回很多,就需要 频繁的创建/销毁进程,这样就会比较低效;
创建/销毁进程,本身就是一个比较低效的操作:
- 创建 PCB
- 分配系统资源(尤其是 内存资源)
- 把 PCB 加入到内核的双向链表中
其中,分配资源 就已经是特别需要消耗时间了;
由于频繁的创建/销毁进程,是一件比较低效的事情;所以,就引入了 "线程";线程 也叫做 "轻量级进程"
说明:
一个线程其实是包含在进程之中的(一个进程里面可以有多个线程)
每个线程也可以有自己的 PCB (所以 一个进程里面可能对应多个 PCB)
同一个进程的多个线程之间,共用一份系统资源(这就意味着 新创建的线程,不必给他分配系统资源,只需要复用之前的即可,即 上述的分配资源的操作,就不需要再进行了)
因此,创建线程只需要做到:
- 创建 PCB
- 把 PCB 加入到内核的链表中
这就是 线程相对于进程做出的重大改进,也是进程更 "轻量" 的原因!!!
举例说明:
张三家里是开厂子的,最近几年来生意非常好,需求的订单比较多,于是他准备扩建一下
现在有两种方案:
- 再次建造一个相同的工厂
- 在原来的工厂里面 新增加一条生产线即可
两个方案都可以以相同的效率生产产品,但是 很明显,方案1所需要的成本更高一些
如果可以把进程就可以看作是 工厂,那么线程就可以看成是 生产线
方案1表示多进程实现并发编程,方案2表示多线程实现并发编程
但是,使用多线程是能够提高效率,前提是多核资源必须是要充分的
如果 随着线程数量的增加,CPU 核心都被吃满了,那么 此时再继续增加线程,就已经没有意义了
这个时候速度不会进一步增加,反而会因此额外增加调度的成本(可以想象一下 工厂的生产线也不可以一直的增加下去,工厂的所占的空间满了咋搞,万一生产线之间太挤而会影响效率又咋搞)
总结:
- 线程,是包含在进程内部的 "逻辑执行流"(线程可以执行一段单独的代码,多个线程之间 是并发执行的)
- 操作系统进行调度的时候,其实是以 "线程为单位" 来进行调度的,换句话来说,系统内核不认 进程/线程,只认PCB(一个线程对应一个 PCB,一个进程对应 一个或多个 PCB)
- 进程里的线程的数量不可以无限增加,效率不会越来越高
- 创建线程的开销要比创建进程的开销要小,销毁线程开销要比销毁进程的开销要小
- 进程间是独立的,每个进程都有独立的虚拟地址空间,一个进程崩溃不会影响其余的进程;但是在同一个进程中,多个线程是共用一块资源,一个线程崩溃,这个进程中的所有线程都会崩溃
- 进程之间有隔离性,线程之间没有隔离性
- 进程是操作系统中 资源分配 的基本单位,线程是操作系统中 调度执行 的基本单位

二、多线程程序

即使是一个最简单的 hello world,其实在运行的时候也涉及到 "线程" 了;一个进程里面至少有一个线程
运行这个程序,操作系统就会创建一个 Java进程,在这个 Java进程 里就会有一个线程(主线程)调用 main方法~
虽然在上述代码中,我们没有手动的创建其他线程,但是 Java进程 在运行的时候,内部也会创建出多个线程
2.1 第一个Java多线程程序
Java中创建线程,离不开一个关键的类 —— Thread;
一种创建线程的方式,是写一个子类,继承 Thread,并且重写其中的 run方法:
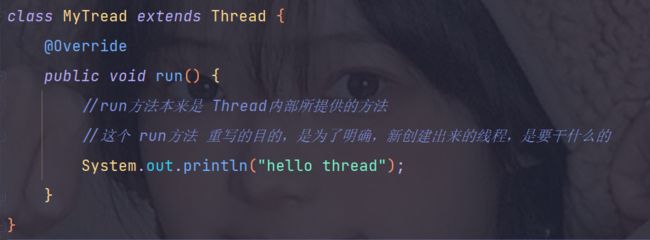
当然,如果仅仅是创建了一个类,还不可以说是 创建了线程,还得要创建实例才可以:

可以这样来理解:
重写的 run方法 —— 先把新员工的任务准备好;
Thread t = new MyThread(); —— 招聘来了一个新员工 t,把任务交给他了(但是还没有开始干活);
t.start(); —— 开始干活
即:使用 new 创建线程对象,线程并没有被创建,而是仅仅创建了一个线程对象,运行 start 方法 时才会创建线程,并执行 run 方法
第一个Java多线程程序的代码
package thread; class MyTread extends Thread { @Override public void run() { //run方法本来是 Thread内部所提供的方法 //这个 run方法 重写的目的,是为了明确,新创建出来的线程,是要干什么的 System.out.println("hello thread"); } } public class Demo1 { public static void main(String[] args) { //创建MyThread线程对象,但是线程没有创建 Thread t = new MyTread(); t.start(); //t.start() 才是真正的开始创建线程, // 在操作系统内核中,创建出对应线程的 PCB,然后让这个 PCB // 加入到系统链表中 参与调度,出现的线程就会执行上面的 run方法 } }
运行结果:

2.2 怎么样观察线程的详细情况
如果我们此时在 主函数中添加这样一句代码:
那么,此时的运行结果是:
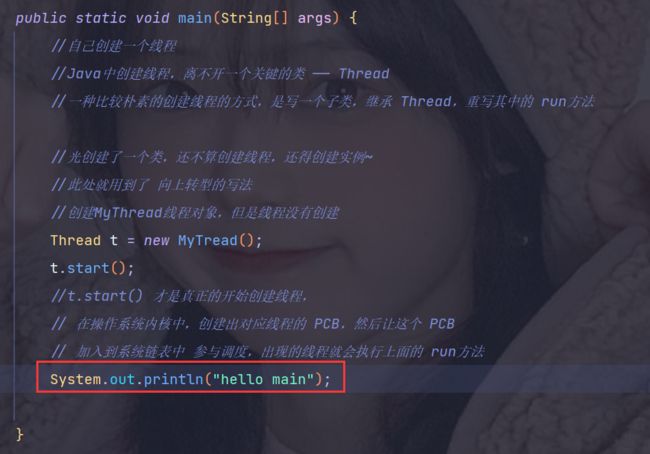
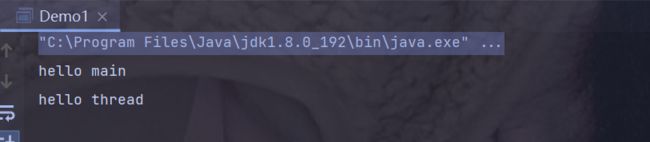
明明是先执行了线程,后打印的"hello main",但是 为什么结果却是 先打印出来 "hello main",后打印的"hello thread" 呢?
- 每个线程都是独立的执行流!换句话说,main对应了一个执行流,MyThread对应了另一个执行流,这两个执行流之间是 并发 的关系;
- 此时两个线程执行的先后顺序,取决于操作系统 调度器 的具体实现;
程序猿可以把这里的调度规则 简单的视为 "随机调度",这个是改变不了的;
如果是想要控制哪个线程先执行,最多是让某个线程先等待,让另一个线程执行完了再执行;
所以,当程序运行的时候,先看到哪一个被执行的顺序 是不确定的;
虽然 可以在这里运行了许多次,先打印出来的是"hello main",但是顺序仍然是不可确定的,大概率是受到了创建线程自身的开销影响的;
当执行结果中出现了这一句话,就说明 进程已经结束了,并且退出码是 0:
就像 C语言中的 return 0;操作系统中用 进程的退出码 来表示进程的运行结果:
使用0表示进程执行完关闭,结果正确;使用 非0 表示进程执行完关闭,结果不正确;还有一种情况是 main还没有返回,程序就崩溃,此时返回的值很可能是一个随机值

当然,如果想要使进程不要结束的那么快,可以在 main方法 和 重写的run方法 使用死循环,让它们一直打印,这样就可以了
然后再执行结果中 是:"hello main" 和 "hello thread" 在交替打印,每一波都会打印几个,然后再打印下一波,当然 都是不确定的,打印那个内容,也都是调度器在进行控制;此时,就可以来查看 当前Java进程里面的线程的情况
可以在任务管理器中 看见Java进程的情况(需要把死循环的代码运行起来,不然嗖的一下就没了):
当然,此时是看不到 Java线程的,需要借助其他的工具 ;
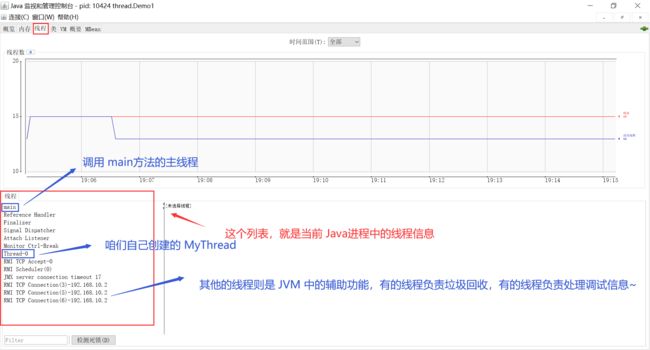
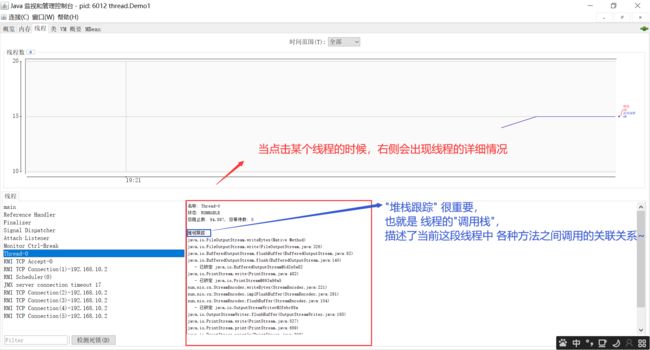
在 JDK 里,提供了一个 jconsole 这样的工具,可以看到 Java进程里面的线程的详情;
运行 jconsole 之后,就可以看到 线程的情况了:

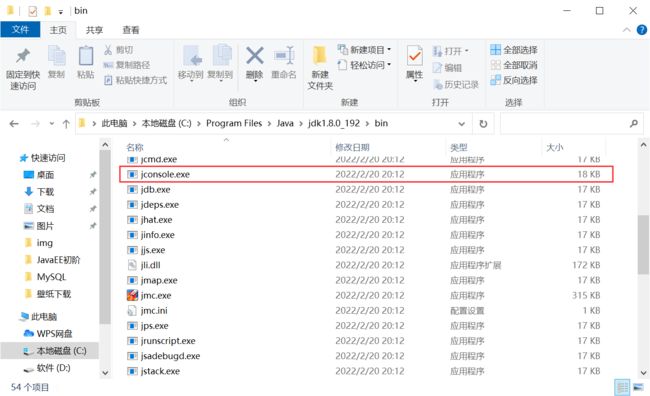

注意:如果在打开 jconsole 之后,如果显示不到 本地进程的管理列表,那么可以退出,然后右键 选择使用管理员的方式运行;
2.3 sleep方法
如果想要线程来适当的 "休息" 一下,为了方便观察,不要让刚刚的死循环代码 打印 "hello main" 和 "hello thread" 打印的太多太快,我们可以用 sleep 来进行操作;
sleep 是 "休眠" 操作,指定让线程摸一会儿鱼,不要上 CPU 上干活,参数单位是 毫秒;
使用 Thread.sleep 的方式进行休眠,sleep 是 Thread 的静态成员方法,直接通过 类名.方法名 的方式调用;
注意时间单位的换算
1秒 = 1000毫秒,1毫秒 = 1000微秒,1微秒 = 1000纳秒,1纳秒 = 1000皮秒;
秒(s)、毫秒(ms)、微秒(us)、纳秒(ns)、皮秒(ps);
由于计算机算得快,所以常用的单位是:ms、us、ns这几个单位;
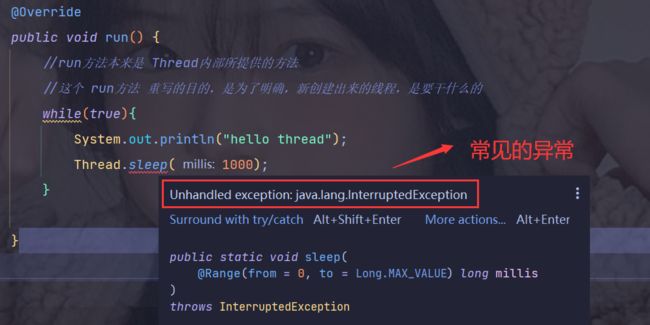
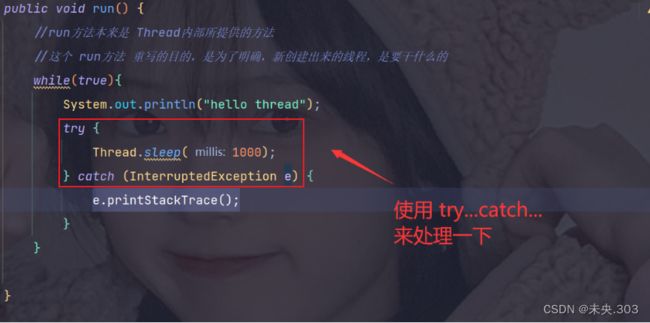
Interrupted 中断!!!
sleep(1000)就是要休眠 1000毫秒,但是 在休眠过程中,可能有一点点意外 把线程给提前唤醒 —— 该异常唤醒的
当然,用同样的方法 处理一下 main方法里面的,就可以很清楚的看到 最终打印的结果是按照自己设定的样子进行的(博客写不了按照时间运行的过程,就不去展示了)
代码结果:

2.4 run 和 start 方法的区别是什么
start 方法:
run 方法 :
解析:
所以我们可以很清楚的看到,直接调用 run方法,并没有创建新的线程,而只是在之前的线程中,执行了 run方法里面的内容;使用 start方法,则是创建了新的线程,新的线程里面会调用 run方法,新线程和旧线程是并发执行的关系;
三、创建线程
3.1 继承 Thread类
如上面所介绍过的,创建一个类 继承 Thread,再重写 run方法
package thread;
class MyTread extends Thread {
@Override
public void run() {
//run方法本来是 Thread内部所提供的方法
//这个 run方法 重写的目的,是为了明确,新创建出来的线程,是要干什么的
while(true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo1 {
public static void main(String[] args) {
//一种比较朴素的创建线程的方式,是写一个子类,继承 Thread,重写其中的 run方法
Thread t = new MyTread();
t.start();
}
}
}说明:
这个写法,线程 和 任务内容 是绑定在一起的;
3.2 实现 Runnable接口
创建线程,还可以创建一个类,实现 Runnable接口,再重写 run方法
package thread;
class MyRunnable implements Runnable {
@Override
public void run() {
while (true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo2 {
public static void main(String[] args) {
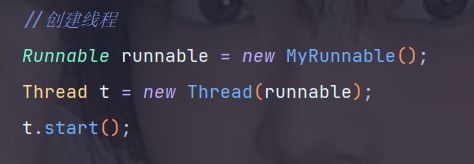
//创建线程
Runnable runnable = new MyRunnable();
Thread t = new Thread(runnable);
t.start();
while (true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}运行结果:

分析:
此处创建的 Runnable,相当于是定义了一个 "任务"(代码要做什么);
还是需要 Thread实例,把任务交给 Thread;
还是需要 Thread.start 来创建具体的线程;
说明:
这个写法,线程和任务是分离开的,可以更好的解耦合,"高内聚 低耦合",因此 使用实现 Runnable接口的方法更优;
把任务内容 和 线程 本身分离开了,即 任务的内容和线程的关系不大;
假设这个任务不想通过多线程的方式执行了,想通过别的方式来执行,这个时候代码改动也不大;
3.3 使用 匿名内部类 来创建线程
我们也可以仍然继承 Thread类,但是不在是显式继承,而是使用 "匿名内部类" 来创建线程;
package thread; public class Demo3 { public static void main(String[] args) { Thread t = new Thread() { @Override public void run() { while (true) { System.out.println("hello thread"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }; t.start(); }运行结果:
分析:
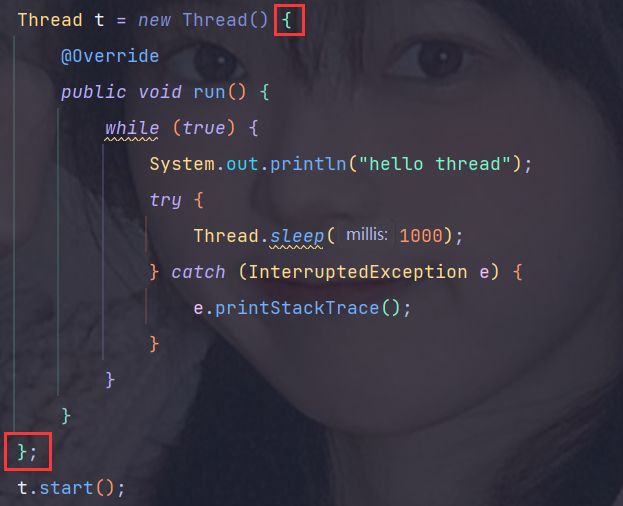
红色框框里面的内容,创建了一个匿名内部类(没有名字),这个匿名内部类是 Thread 的子类,同时前面的 new 关键字,就会给这个匿名内部类创建出了一个实例
这一套操作,继承、方法重写、实例化 一条龙服务
在 start 之前,线程只是准备好了,并没有真正的被创建出来,执行了 start方法,才真正在操作系统中创建了线程;
Thread 实例是 Java 中对于线程的表示,实际上要想正真跑起来,还需要操作系统里面的线程;
创建好了 Thread,此时操作系统里面还没有线程,直到调用 start方法,操作系统才真的创建了线程(创建 PCB,并且把 PCB 加入到链表里),并且进行执行起来;
3.4 使用Runnable接口,以匿名内部类的方式创建线程
package thread; public class Demo4 { public static void main(String[] args) { Thread t = new Thread(new Runnable() { @Override public void run() { while (true) { System.out.println("hello thread"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }); t.start(); } }运行结果:

3.5 使用Lambda表达式创建线程(推荐做法)
package thread; public class Demo5 { public static void main(String[] args) { Thread t = new Thread(() ->{ while(true){ System.out.println("hello thread"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }); t.start(); } }
运行结果:
说明:
使用 lambda表达式,其实是更简单的写法,也是推荐写法;
形如 lambda表达式这样的,能够简化代码编写的语法规则,称为 "语法糖";
四、多线程的优点
单个线程,串行的,完成 20 亿次自增:
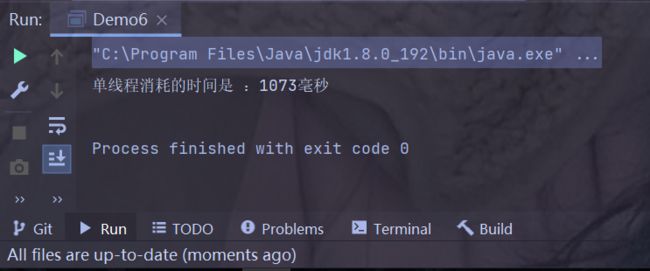
package thread; public class Demo6 { private static final long count = 20_0000_0000; private static void serial() { //serial 是 "串行" 的意思 //需要把方法执行的时间给记录下来 //记录当前的毫秒计时间戳 long begin = System.currentTimeMillis(); int a = 0; for(long i = 0; i < count; i++) { a++; } a = 0; for(long i = 0; i < count;i++) { a++; } long end = System.currentTimeMillis(); System.out.println("单线程消耗的时间是 :" + (end-begin) + "毫秒"); } public static void main(String[] args) { serial(); } }运行结果:
多运行几次,取其平均值,所得的结果大概是:
单线程消耗的时间是:1070毫秒;
多个线程,并发的,完成 20 亿次自增
我们向 Demo6 中添加如下代码:
private static void concurrency() { //concurrency 的意思是 "并发" long begin = System.currentTimeMillis(); Thread t1 = new Thread(() ->{ int a = 0; for(long i = 0; i < count; i++) { a++; } }); Thread t2 = new Thread(() ->{ int a = 0; for(long i = 0; i < count; i++) { a++; } }); t1.start(); t2.start(); long end = System.currentTimeMillis(); System.out.println("多线程并发执行的时间:" + (end-begin) + "毫秒"); }这个代码,涉及到三个线程:t1、t2、main(调用 concurrency 方法的线程),三个线程都是并发执行的
即 t1、t2会开始执行,同时,可能不等t1、t2执行完,main线程就结束了,于是就结束计时
此处的计时,是为了衡量 t1 和 t2 的执行时间,所以正确的做法应该是等到 t1 和 t2 都执行完,才停止计时
所以在 创建线程的时候,还需要使用 jion方法
jion方法是等待线程结束(等待线程把自己的 run方法执行完)
所以还需要在 t1 和 t2 创建线程后 加上:
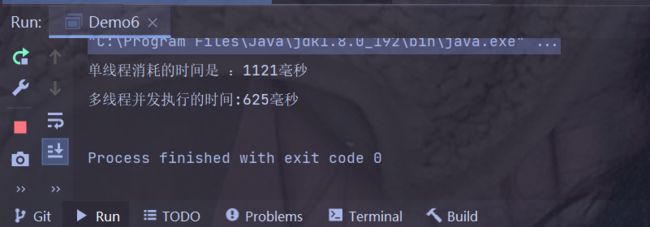
--加在 t2.start(); 之后 try { t1.join(); t2.join(); } catch (InterruptedException e) { e.printStackTrace(); }并此时可以在 mian方法中调用 concurrency() 方法
运行结果:
并同时执行多次 取其均值,我们可以发现,并发执行的时间的平均值 在 600 毫秒左右;
所以,相比之下,我们可以知道,多线程的效率确实是提高不少;
当然,如果在任务量不大的情况下,可能多线程并不会比单线程有太大的优势,毕竟线程的创建也是有开销的嘛;
五、多线程的使用场景
(1)在 CPU 密集型场景
代码中的大部分工作,都是在使用 CPU 进行运算(如 上面的反复 ++ 运算),此时使用 多线程 就可以更好的利用 CPU 多核计算资源,从而提高效率
(2)在 IO 密集型场景
I : input 输入
O : output 输出
如 读写硬盘、读写网卡......这些都算 IO
这些场景里,就需要花很大的时间等待
像这些 IO 操作,都是几乎不消耗 CPU 就能快速的完成读写数据的操作,既然 CPU 在摸鱼,就可以找点活干,可以使用多线程,避免 CPU 过于闲置
这就好比去食堂打饭,但是人多要排队,排队的过程就是等待(类似于 等待IO结束),于是 顺便拿出一本书来学习
(当然,我相信更多的同学会掏出手机刷视频)
总结
今天的内容就分享到这里了,下一节我们将更多了解有关多线程的知识,更加深入的进行学习,就让我们下一节内容再见吧!!!!!!!!!!!!!!
