Python自然语言处理第二章 - 获得文本语料与词汇
一,获取文本语料库
1,古腾堡语料库
古腾堡语料库主要存储的是免费的电子图书。
import nltk
from nltk.corpus import *
fileids = gutenberg.fileids();
text1 = gutenberg.words(fileids[0]);
len(text1)
# 如果要使用第一章中的concordance()等函数需要将text1转换为Text类型...
text1_1 = nltk.Text(text1);
text1_1.concordance('surprize');
# 常用操作,raw()函数给我们的是没有进行任何语言学处理的文件的内容
chars = gutenberg.raw(fileids[0]);
words = gutenberg.words(fileids[0]);
sents = gutenberg.sents(fileids[0]);2,网络与聊天文件
webfiles = webtext.fileids();
chatroom = nps_chat.posts('1--19-20s_706posts.xml');3,布朗语料库
from nltk.corpus import brown
ctgr = brown.categories();
fileids = brown.fileids();
words1 = brown.words(categories=ctgr[0]);
word2 = brown.words(fileids=fileids[0]);
sents = brown.sents(categories=['news','editorial','reviews']);4,路透社语料库
5,就职演说语料库
6,标注文本语料库
等等 详见P61
7,文本语料库的结构

8,基本语料库函数

9,载入自己的语料库
(1)载入自己的文本文件
from nltk.corpus import PlaintextCorpusReader
corpus_root = '/usr/share/dict';
wordlists = PlaintextCorpusReader(corpus_root,'.*');
wordlists.fileids();(2)载入本地硬盘上自己的语料库的拷贝
from nltk.corpus import BracketParseCorpusReader
corpus_root = r"C:\corpora\penntreebank\parsed\mrg\wsj"
file_pattern = r".*/wsj_.*\.mrg"
ptb = BracketParseCorpusReader(corpus_root, file_pattern)
ptb.fileids();二,条件频率分布
1,按文本计数词汇
FreqDist以一个简单的链表作为输入,ConditonalFreqDist以一个配对链表作为输入。
from nltk.corpus import brown
cfd = nltk.ConditionalFreqDist(
(genre,word)
for genre in brown.categories()
for word in brown.words(categories=genre))
cfd.conditions();
cfd['news'];
cfd['news']['could'];2,绘制分布图与分布表
cfd.tabulate();
cfd.tabulate(conditions=['news','romance'],samples=['who','when','where']);
cfd.plot();
cfd.plot(conditions=[],samples=[]);3,使用双连词生成随机文本
import nltk
from nltk.corpus import gutenberg
def generate_model(cfdist,word,num=15):
for i in range(num):
print(word,end=' ');
word = cfdist['word'].max();
text = gutenberg.words(gutenberg.fileids()[0]);
bigrams = nltk.bigrams(text);
cfd = nltk.ConditonalFreqDist(bigrams);
generate_model(cfd,'livng');NLTK条件概率分布的常用方法

三,代码重用
- 函数
- 模块(module)
- 包(package)
- 库(library)
在一个文件中的变量和函数定义的集合被称为一个Python 模块(module)。相关模块的集合称为一个包(package)。处理布朗语料库的NLTK 代码是一个模块,处理各种不同的语料库的代码的集合是一个包。NLTK 的本身是包的集合,有时被称为一个库(library)。
四,词典资源
1,词汇列表语料库
(1)所有词汇
nltk.corpus.words.words()(2)2stopwords语料库
nltk.corpus.stopwords.words()
nltk.corpus.stopwords.words('english')(3)names语料库
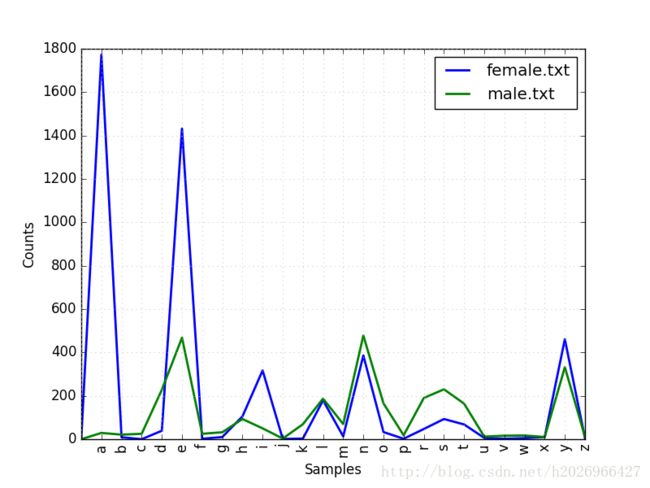
可以用来分析一些名词的特点或者男性名字与女性名字的特点。如下:
>>> names.fileids()
['female.txt', 'male.txt']
>>> import nltk
>>> cfd = nltk.ConditionalFreqDist(
... (fileids,name[-1])
... for fileids in names.fileids()
... for name in names.words(fileids))
>>> cfd.plot()
2,发音的词典
cmudict语料库
可以用来把具有相同发音特点的词找出来。
from nltk.corpus import cmudict
entries = cmudict.entries();
for entry in entries[:10]:
pint(entry,end=' ');
for word,pron in entries:
if len(pron)==3:
ph1,ph2,ph3 = pron;
if ph1='P' and ph3='T':
print(word,ph2);3,比较词表
可以用来制作一个简单的单词翻译器。
from nltk.corpus import swadesh
swadesh.fileids();
fr2en = swadesh.entries(['fr','en']);
translate = dict(fr2en);
translate['jeter'];
de2en = swadesh.entries(['de','en']);
translate.update(dict(de2en));4,词汇工具Toolbox
五,Wordnet
Wordnet是一个面向语义的英语词典。
1,意义与同义词
>>> wordnet.synsets('motorcar')
[Synset('car.n.01')] #确定motorcar只有一个意思car.n.01。
>>> wordnet.synset('car.n.01').lemma_names()
['car', 'auto', 'automobile', 'machine', 'motorcar'] #这个同义词集中的所有词
>>> wordnet.synset('car.n.01').definition()
'a motor vehicle with four wheels; usually propelled by an internal combustion engine' #这个同义词集中的词表示的意义
>>> wordnet.synset('car.n.01').examples()
['he needs a car to get to work']
>>> wordnet.synset('car.n.01').lemmas()
[Lemma('car.n.01.car'), Lemma('car.n.01.auto'), Lemma('car.n.01.automobile'), Lemma('car.n.01.machine'), Lemma('car.n.01.motorcar')] #这个同义词集中的所以词条,词条就是同义词集和词的配对。其中car.n.01被称为synset或同义词集,是一种特殊的结构。
Wordnet的层次结构

主要有上位词、下位词等概念。
可以通过nltk中的wordnet浏览器:nltk.app.wordnet()来浏览wordnet。
更多词汇关系
上位词和下位词被称为词汇关系,还有很多词汇关系如整体与部分,反义词等等。
语义相似度
六,小结
- 文本语料库是一个大型结构化文本的集合。NLTK 包含了许多语料库,如:布朗语料库nltk.corpus.brown。
- 有些文本语料库是分类的,例如通过文体或者主题分类;有时候语料库的分类会相互重叠。
- 条件频率分布是一个频率分布的集合,每个分布都有一个不同的条件。它们可以用于通过给定内容或者文体对词的频率计数。
- 行数较多的Python 程序应该使用文本编辑器来输入,保存为.py 后缀的文件,并使用import 语句来访问。
- Python 函数允许你将一段特定的代码块与一个名字联系起来,然后重用这些代码想用多少次就用多少次。
- 一些被称为“方法”的函数与一个对象联系在起来,我们使用对象名称跟一个点然后跟方法名称来调用它,就像:x.funct(y)或者word.isalpha()。
- 要想找到一些关于变量v 的信息,可以在Pyhon 交互式解释器中输入help(v)来阅读这一类对象的帮助条目。
- WordNet 是一个面向语义的英语词典,由同义词的集合—或称为同义词集(synsets)—组成,并且组织成一个网络。
- 默认情况下有些函数是不能使用的,必须使用Python 的import 语句来访问。