Numpy、Matplotlib and Pandas
一、NumPy
1.创建与访问
1.与列表的区别:数组中所有元素的数据类型是相同的。底层经过充分优化的 C 语言代码,计算性能比高。提供了全面的数学函数可以直接应用在数组上。
2.定义的数组叫ndarray,n-dimensions-array 即:n维数组。
import numpy as np # 按照传统导入
a = np.array([1, 2, 3]) # 或a = np.array((1, 2, 3))
print(a) # [1 2 3]
print(type(a)) # 
3.创建ndarray的方式
import numpy as np
# ==================有值创建==================
a_list = np.array([1, 2, 3])
a_tuple = np.array((1, 2, 3))
# ==================填充创建==================
a_zeros = np.zeros((2, 3))
a_ones = np.ones((2, 3))
a_empty = np.empty((2, 3))
# ==================等差创建==================
a_ar = np.arange(6)
a_lin = np.linspace(0, 10, num=5)
# ==================随机创建==================
# 给定随机种子
np.random.seed(10)
# 创建维度为(3,1)的0~1的随机数列
t1 = np.random.rand(3, 1)
# 创建维度为(2,2)的(0~100)的小数随机数列
t2 = np.random.uniform(0, 100, (2, 2))
# 创建维度为(2,2)的(0~100)的整数随机数列
t3 = np.random.randint(0, 20, (2, 2))
# 给定均值、标准差、维度的正态分布
t4 = np.random.normal(0, 1, (2, 2))
# 标准正太分布。定均值为0、标准差为1的正太分布
t5 = np.random.standard_normal(size=(2, 2))
4.访问数组
可以通过索引或者切片的方式访问数组
import numpy as np
# 创建 5*4 二维数组(5行4列)
c = np.array([[0, 1, 2, 3], [10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33], [40, 41, 42, 43]])
print(c)
# 按照索引取 第1行,第2列的元素
print(c[1, 2]) # 12
# 切片,取 1~2 行,第2~3列元素(数组)
print(c[1:3, 2:4])
# 切片,取 1~2 行,第2列的元素(数组)
print(c[1:3, 2])
# 步长=2,取到第 1, 3 行,第2~3列元素
print(c[1:6:2, 2:4])
# 取最后一维,下标为2的元素
print(c[:, 2])
# 维度比较多,需要写很多:,提供...可以代表之前或之后的任意维度
print(c[..., 2])
2.数组操作
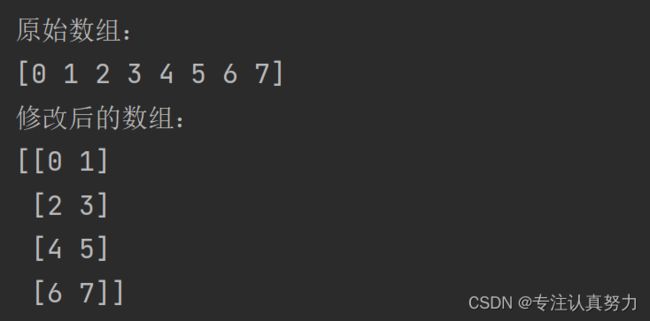
1.修改数组形状

import numpy as np
a = np.arange(8)
print('原始数组:')
print(a)
b = a.reshape(4, 2)
print('修改后的数组:')
print(b)
二、Matplotlib
1.入门
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-1, 1, 50) # x为(-1,1)区间上的50个等差点构成的数组/列表/元组
y = 2 * x + 1 # y与x的函数关系
plt.plot(x, y) # 用于画图,它可以绘制点和线, 并且对其样式进行控制
plt.show() # 显示图像

2.数据传入
1.x为x轴数据, y为y轴数据
import matplotlib.pyplot as plt
x = [3, 4, 5] # [列表]
y = [2, 3, 2] # x,y元素个数N应相同
plt.plot(x, y)
plt.show()
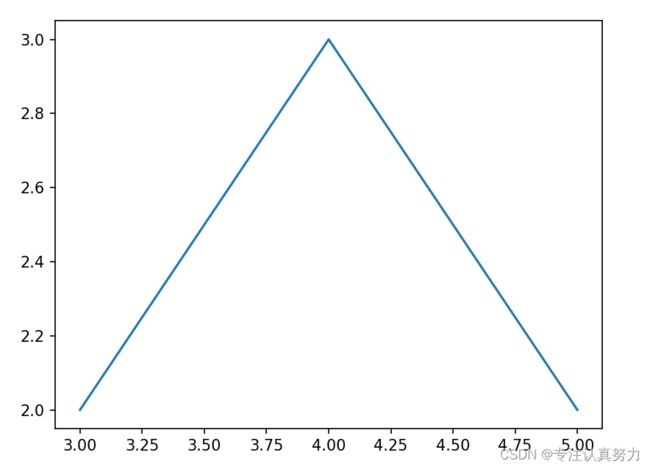
2.x, y可传入(元组), [列表], np.array, pd.Series
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x=(3,4,5) # (元组)
y1=np.array([3,4,3]) # np.array
y2=pd.Series([4,5,4]) # pd.Series
plt.plot(x,y1)
plt.plot(y2) # x可省略,默认[0,1..,N-1]递增
plt.show() # plt.show()前可加多个plt.plot(),画在同一张图上
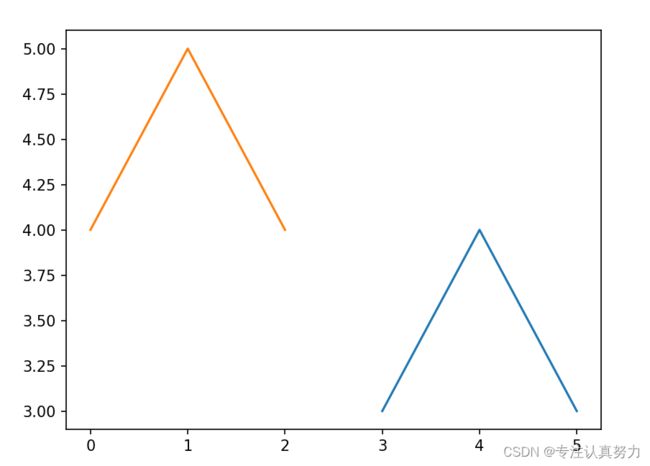
3.可传入多组x, y
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x=(3,4,5)
y1=np.array([3,4,3])
y2=pd.Series([4,5,4])
plt.plot(x,y1,x,y2) # 此时x不可省略
plt.show()
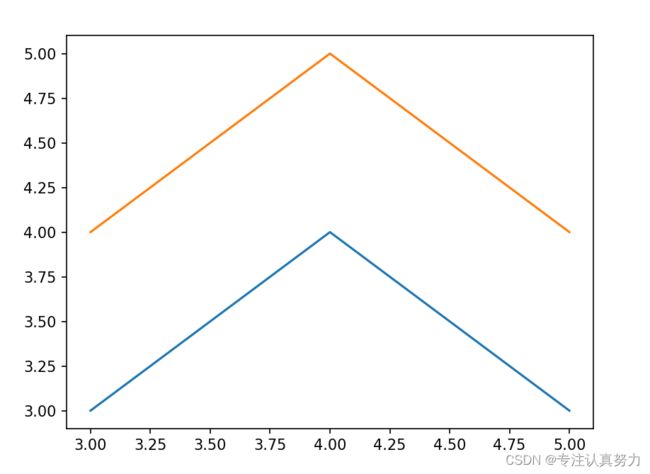
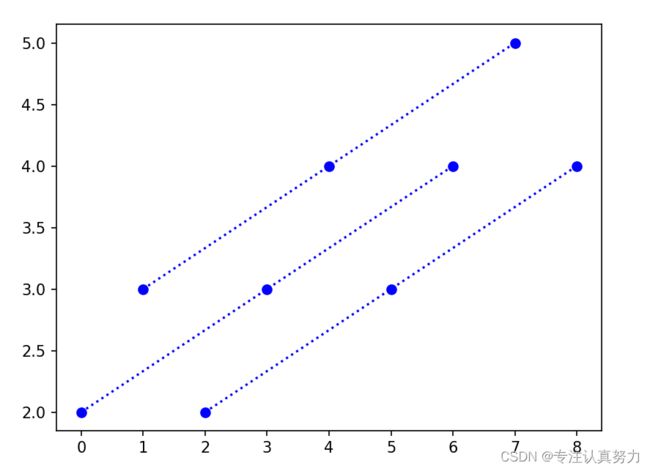
4.x或y传入二维数组
import matplotlib.pyplot as plt
import numpy as np
lst1 = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
x = np.array(lst1)
lst2 = [[2, 3, 2], [3, 4, 3], [4, 5, 4]]
y = np.array(lst2)
print(x)
print(y)
plt.plot(x, y)
plt.show()

蓝色:x1(0,3,6) y1(2,3,4)
橙色:x2(1,4,7) y2(3,4,5)
绿色:x3(2,5,8) y3(2,3,4)
3.图形控制
1.plt.plot(x, y, “格式控制字符串”)
import matplotlib.pyplot as plt
import numpy as np
lst1 = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
x = np.array(lst1)
lst2 = [[2, 3, 2], [3, 4, 3], [4, 5, 4]]
y = np.array(lst2)
plt.plot(x, y, "ob:") # "b"为蓝色, "o"为圆点, ":"为点线
plt.show()
2."格式控制字符串"最多可以包括三部分, “颜色”, “点型”, “线型”
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
color = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'w']
line_style = ['-', '--', '-.', ':']
dic1 = [[0, 1, 2], [3, 4, 5]]
x = pd.DataFrame(dic1)
dic2 = [[2, 3, 2], [3, 4, 3], [4, 5, 4], [5, 6, 5]]
y = pd.DataFrame(dic2)
# 循环输出所有"颜色"与"线型"
for i in range(2):
for j in range(4):
plt.plot(x.loc[i], y.loc[j], color[i * 4 + j] + line_style[j])
plt.show()

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
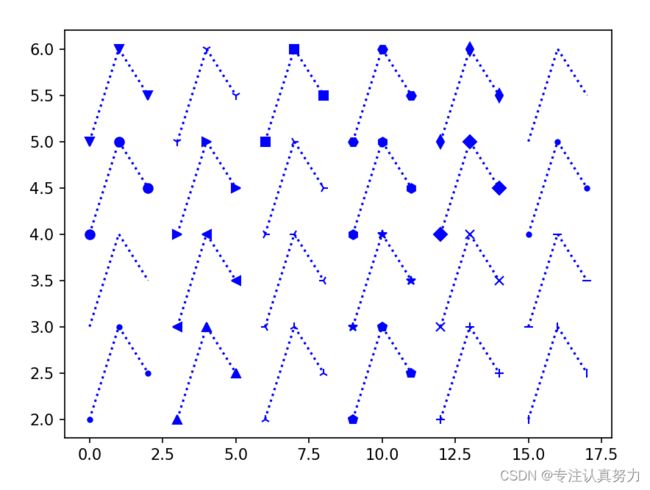
marker = ['.', ',', 'o', 'v', '^', '<', '>', '1', '2', '3', '4', 's', 'p', '*', 'h', 'H', '+', 'x', 'D', 'd', '|', '_',
'.', ',']
dic1 = [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13, 14], [15, 16, 17]]
x = pd.DataFrame(dic1)
dic2 = [[2, 3, 2.5], [3, 4, 3.5], [4, 5, 4.5], [5, 6, 5.5]]
y = pd.DataFrame(dic2)
# 循环输出所有"点型"
for i in range(6):
for j in range(4):
plt.plot(x.loc[i], y.loc[j], "b" + marker[i * 4 + j] + ":") # "b"蓝色,":"点线
plt.show()
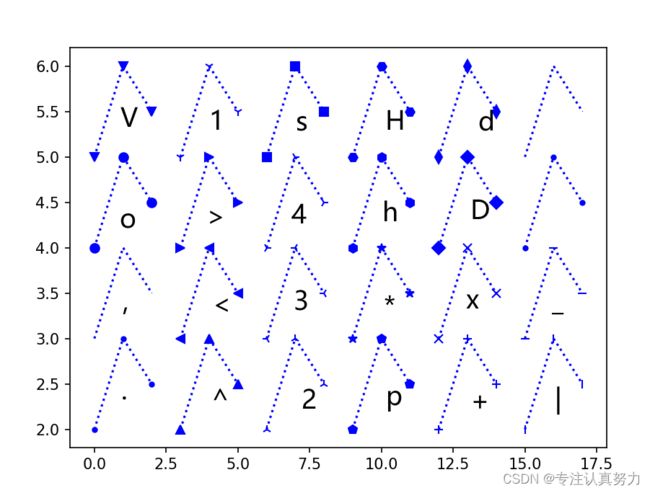
颜色
“c” cyan青
“r” red 红
“g” green 绿
“b” blue 蓝
“w” white 白
“k” black 黑
“y” yellow 黄
“m” magenta 洋红
线型
“:” 点线
“-.” 点画线
“–” 短划线
“-” 实线
点型
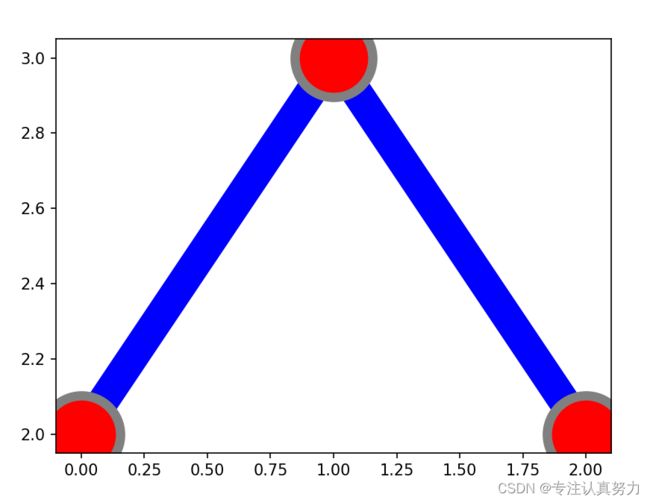
3.plt.plot(x, y, “格式控制字符串”, 关键字=参数)
除了"格式控制字符串", 还可以在后面添加关键字=参数
import matplotlib.pyplot as plt
y = [2, 3, 2]
# 蓝色,线宽20,圆点,点尺寸50,点填充红色,点边缘宽度6,点边缘灰色
plt.plot(y, color="blue", linewidth=20, marker="o", markersize=50,
markerfacecolor="red", markeredgewidth=6, markeredgecolor="grey")
plt.show()
4.进阶

折线图

直方图

条形图

散点图

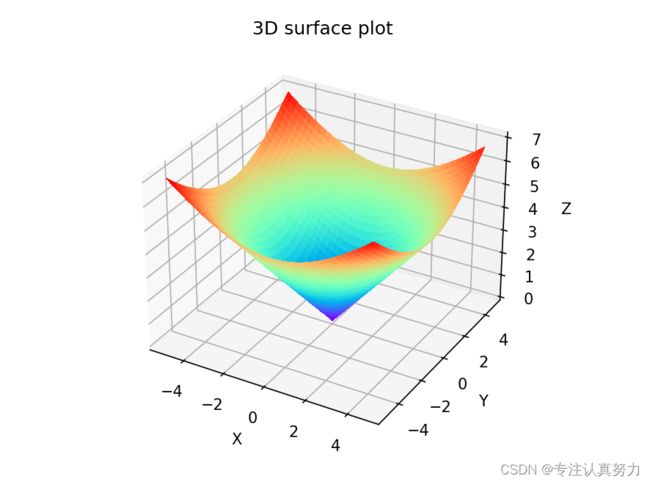
5.三维曲面
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure()
ax = fig.add_subplot(projection="3d")
x = np.arange(-5, 5, 0.25)
y = np.arange(-5, 5, 0.25)
x, y = np.meshgrid(x, y)
z = np.sqrt(x ** 2 + y ** 2)
ax.set_xlabel("X")
ax.set_ylabel("Y")
ax.set_zlabel("Z")
ax.set_title("3D surface plot")
ax.plot_surface(x, y, z,
rstride=1,
cstride=1,
cmap=plt.cm.coolwarm,
linewidth=0,
antialiased=False)
plt.show()
三、Pandas
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
在 ndarray 数组(NumPy 中的数组)的基础上构建出了两种不同的数据结构,分别是 Series(一维数据结构)DataFrame(二维数据结构)
- Series 是带标签的一维数组,这里的标签可以理解为索引,但这个索引并不局限于整数,它也可以是字符类型,比如 a、b、c 等;
- DataFrame 是一种表格型数据结构,它既有行标签,又有列标签。

1.Series 序列
它是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。
Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。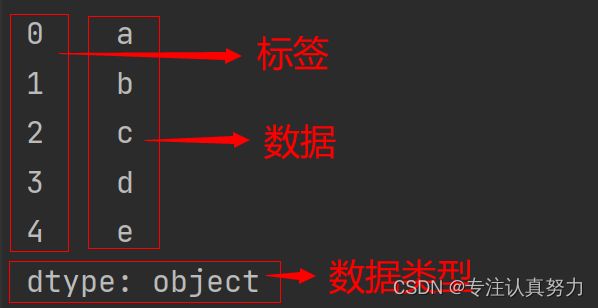

import pandas as pd
import numpy as np
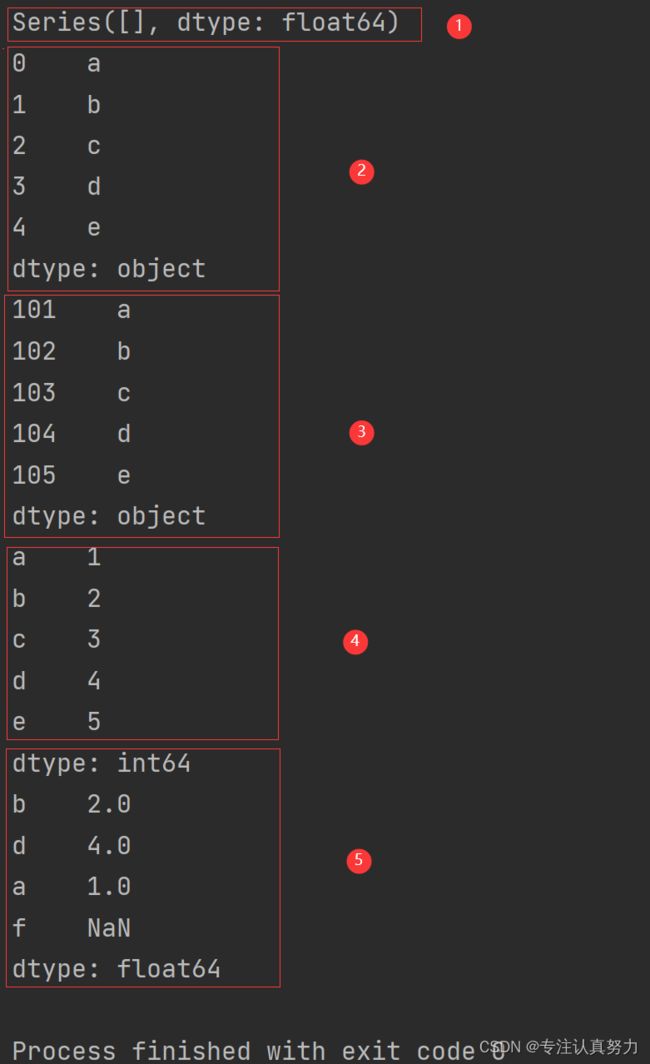
print(pd.Series([], dtype='float64')) # 1.空白数据
# 使用列表创建
data = np.array(['a', 'b', 'c', 'd', 'e'])
print(pd.Series(data)) # 2.标签为默认从0开始递增
print(pd.Series(data, index=[101, 102, 103, 104, 105])) # 3.自定义标签
# 使用键值对创建
data_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
print(pd.Series(data_dict)) # 4.标签为键,数值为值
print(pd.Series(data_dict, index=['b', 'd', 'a', 'f'])) # 5.当传递的索引值无法找到与其对应的值时,使用 NaN(非数字)填充。

import pandas as pd
s = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
# 索引访问
print(s[0]) # 1.单个元素访问
print(s[:3]) # 2.切片访问
print(s[[1, 4, 3]]) # 3.多个非连续元素访问
# 标签访问
print(s['a']) # 4.单个元素访问
print(s[:'d']) # 5.切片访问
print(s[['a', 'd', 'e']]) # 6.多个非连续元素访问


![]()
head()&tail()查看数据
import pandas as pd
import numpy as np
s = pd.Series(np.random.randint(1, 100, 8))
print(s)
print(s.head()) # 默认访问前5个数据
print(s.head(3)) # 自定义访问前n个数据
print(s.tail()) # 默认访问后5个数据
print(s.tail(3)) # 自定义访问后n个数据
isnull()&nonull()检测缺失值
import pandas as pd
s = pd.Series(['a', 'b', 'c', None])
print(pd.isnull(s)) # 如果为值不存在或者缺失,则返回 True
print(pd.notnull(s)) # 如果值不为空,则返回 True
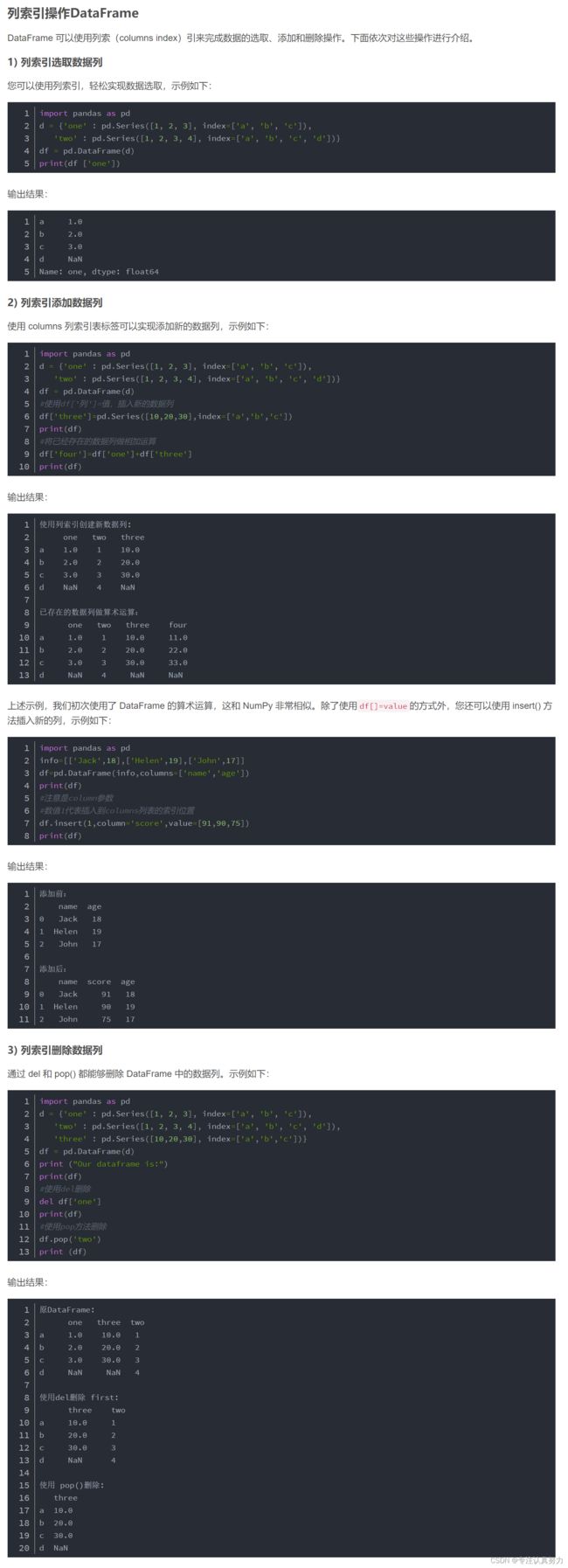
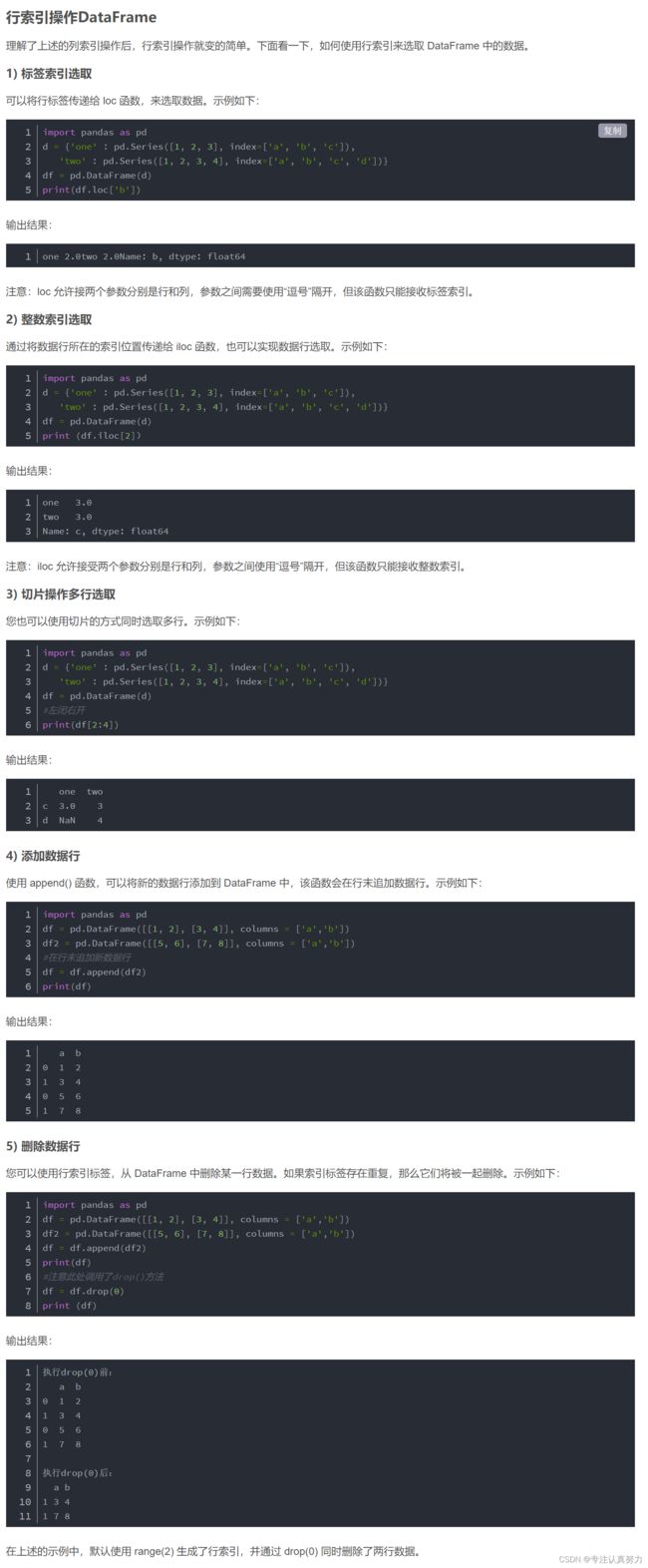
2.DataFrame表格结构


import pandas as pd
# 1.创建空的DataFrame对象
print(pd.DataFrame())
# 2.单一列表创建 DataFrame
print(pd.DataFrame(['a', 'b', 'c', 'd']))
# 3.使用嵌套列表创建 DataFrame 对象
print(pd.DataFrame([['Alex', 10], ['Bob', 12], ['Clarke', 13]], columns=['name', 'age']))
# 4.字典嵌套列表创建,字典的键被用作列名
print(pd.DataFrame({'Name': ['Tom', 'Jack', 'Steve', 'Ricky'], 'Age': [28, 34, 29, 42]}))
# 5.列表嵌套字典创建DataFrame对象,字典的键被用作列名
print(pd.DataFrame([{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]))